 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Paper and Code
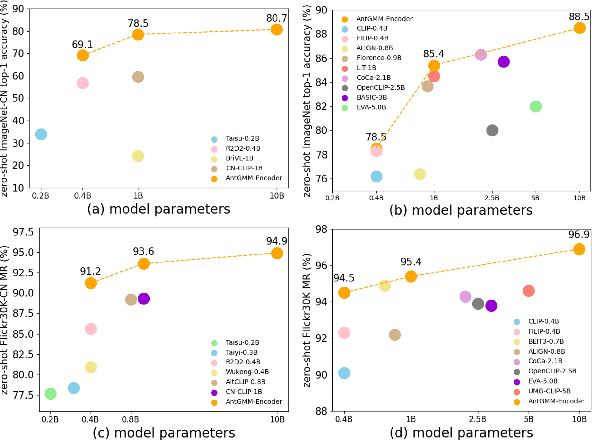
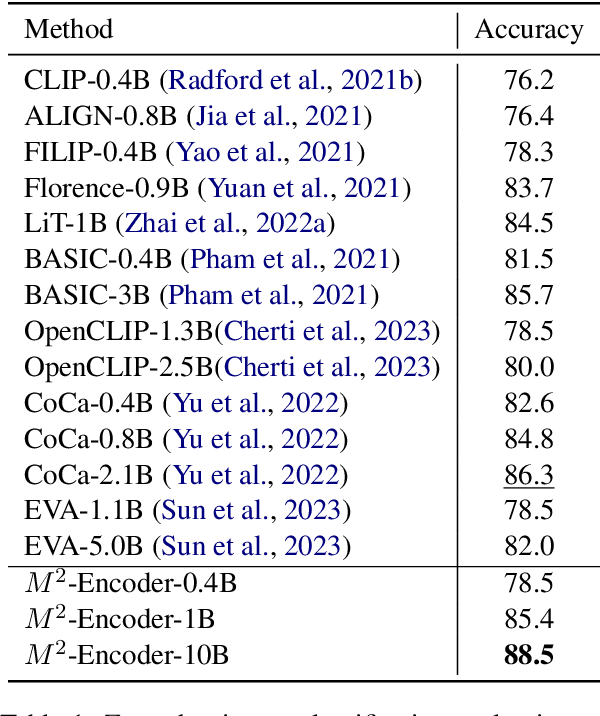
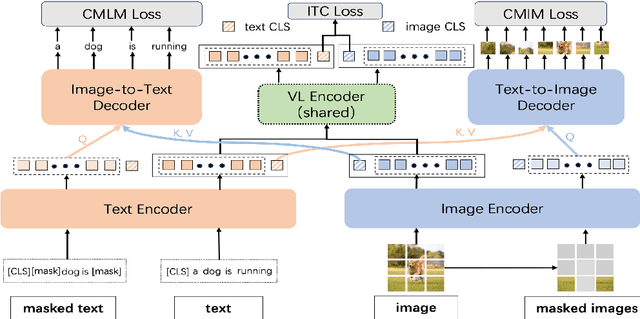
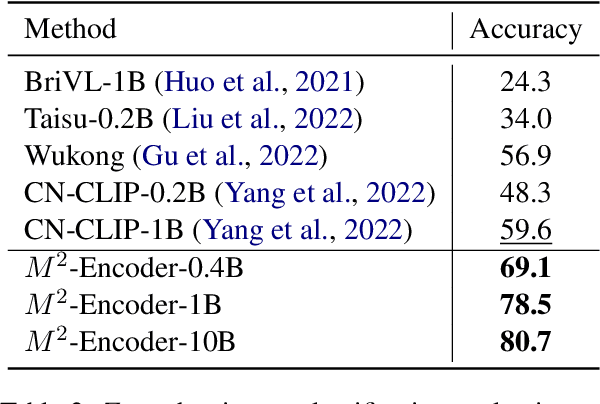
Vision-language foundation models like CLIP have revolutionized the field of artificial intelligence. Nevertheless, VLM models supporting multi-language, e.g., in both Chinese and English, have lagged due to the relative scarcity of large-scale pretraining datasets. Toward this end, we introduce a comprehensive bilingual (Chinese-English) dataset BM-6B with over 6 billion image-text pairs, aimed at enhancing multimodal foundation models to well understand images in both languages. To handle such a scale of dataset, we propose a novel grouped aggregation approach for image-text contrastive loss computation, which reduces the communication overhead and GPU memory demands significantly, facilitating a 60% increase in training speed. We pretrain a series of bilingual image-text foundation models with an enhanced fine-grained understanding ability on BM-6B, the resulting models, dubbed as $M^2$-Encoders (pronounced "M-Square"), set new benchmarks in both languages for multimodal retrieval and classification tasks. Notably, Our largest $M^2$-Encoder-10B model has achieved top-1 accuracies of 88.5% on ImageNet and 80.7% on ImageNet-CN under a zero-shot classification setting, surpassing previously reported SoTA methods by 2.2% and 21.1%, respectively. The $M^2$-Encoder series represents one of the most comprehensive bilingual image-text foundation models to date, so we are making it available to the research community for further exploration and development.