 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-KV: Task-aware KV Cache Optimization via Semantic Differentiation of Attention Heads
Jan 25, 2025KV cache is a widely used acceleration technique for large language models (LLMs) inference. However, its memory requirement grows rapidly with input length. Previous studies have reduced the size of KV cache by either removing the same number of unimportant tokens for all attention heads or by allocating differentiated KV cache budgets for pre-identified attention heads. However, due to the importance of attention heads varies across different tasks, the pre-identified attention heads fail to adapt effectively to various downstream tasks. To address this issue, we propose Task-KV, a method that leverages the semantic differentiation of attention heads to allocate differentiated KV cache budgets across various tasks. We demonstrate that attention heads far from the semantic center (called heterogeneous heads) make an significant contribution to task outputs and semantic understanding. In contrast, other attention heads play the role of aggregating important information and focusing reasoning. Task-KV allocates full KV cache budget to heterogeneous heads to preserve comprehensive semantic information, while reserving a small number of recent tokens and attention sinks for non-heterogeneous heads. Furthermore, we innovatively introduce middle activations to preserve key contextual information aggregated from non-heterogeneous heads. To dynamically perceive semantic differences among attention heads, we design a semantic separator to distinguish heterogeneous heads from non-heterogeneous ones based on their distances from the semantic center. Experimental results on multiple benchmarks and different model architectures demonstrate that Task-KV significantly outperforms existing baseline methods.
Fusing Models for Prognostics and Health Management of Lithium-Ion Batteries Based on Physics-Informed Neural Networks
Jan 02, 2023



For Prognostics and Health Management (PHM) of Lithium-ion (Li-ion) batteries, many models have been established to characterize their degradation process. The existing empirical or physical models can reveal important information regarding the degradation dynamics. However, there is no general and flexible methods to fuse the information represented by those models. Physics-Informed Neural Network (PINN) is an efficient tool to fuse empirical or physical dynamic models with data-driven models. To take full advantage of various information sources, we propose a model fusion scheme based on PINN. It is implemented by developing a semi-empirical semi-physical Partial Differential Equation (PDE) to model the degradation dynamics of Li-ion-batteries. When there is little prior knowledge about the dynamics, we leverage the data-driven Deep Hidden Physics Model (DeepHPM) to discover the underlying governing dynamic models. The uncovered dynamics information is then fused with that mined by the surrogate neural network in the PINN framework. Moreover, an uncertainty-based adaptive weighting method is employed to balance the multiple learning tasks when training the PINN. The proposed methods are verified on a public dataset of Li-ion Phosphate (LFP)/graphite batteries.
Bidirectional Machine Reading Comprehension for Aspect Sentiment Triplet Extraction
Mar 13, 2021
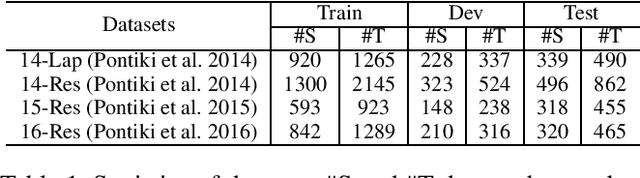
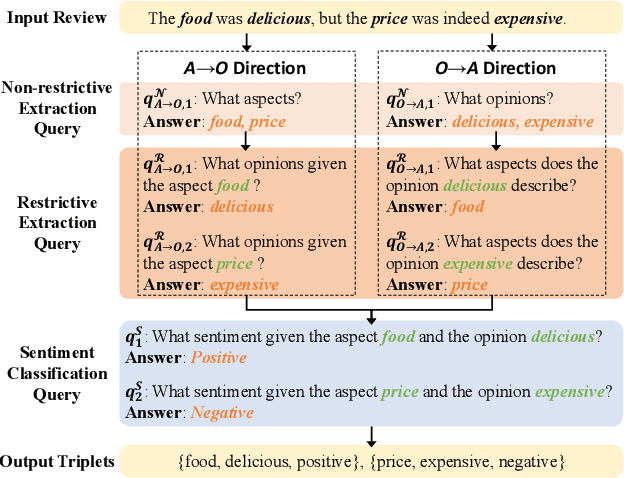
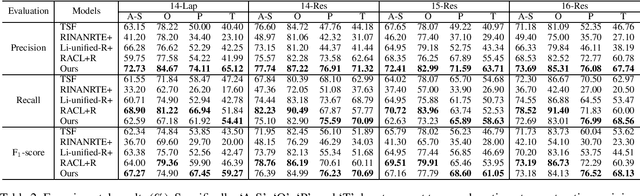
Aspect sentiment triplet extraction (ASTE), which aims to identify aspects from review sentences along with their corresponding opinion expressions and sentiments, is an emerging task in fine-grained opinion mining. Since ASTE consists of multiple subtasks, including opinion entity extraction, relation detection, and sentiment classification, it is critical and challenging to appropriately capture and utilize the associations among them. In this paper, we transform ASTE task into a multi-turn machine reading comprehension (MTMRC) task and propose a bidirectional MRC (BMRC) framework to address this challenge. Specifically, we devise three types of queries, including non-restrictive extraction queries, restrictive extraction queries and sentiment classification queries, to build the associations among different subtasks. Furthermore, considering that an aspect sentiment triplet can derive from either an aspect or an opinion expression, we design a bidirectional MRC structure. One direction sequentially recognizes aspects, opinion expressions, and sentiments to obtain triplets, while the other direction identifies opinion expressions first, then aspects, and at last sentiments. By making the two directions complement each other, our framework can identify triplets more comprehensively. To verify the effectiveness of our approach, we conduct extensive experiments on four benchmark datasets. The experimental results demonstrate that BMRC achieves state-of-the-art performances.