 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing efficient channels for ideal observers using the conjugate gradient method
May 28, 2026Task-based assessment of image quality (IQ) is critically important for the design and optimization of medical imaging systems. Ideal observers, including the Bayesian Ideal Observer (IO) and the ideal linear observer, i.e., the Hotelling observer (HO), provide objective figures of merit (FOMs) that quantify system performance on signal detection tasks. However, the application of ideal observers to high-dimensional image data is often computationally intractable. Channel mechanisms provide an effective framework for dimensionality reduction that can facilitate the computation of ideal observers. This work presents a conjugate gradient (CG)-based method to construct efficient channels for approximating the IO and HO performance.
Using gradient of Lagrangian function to compute efficient channels for the ideal observer
Jan 31, 2025It is widely accepted that the Bayesian ideal observer (IO) should be used to guide the objective assessment and optimization of medical imaging systems. The IO employs complete task-specific information to compute test statistics for making inference decisions and performs optimally in signal detection tasks. However, the IO test statistic typically depends non-linearly on the image data and cannot be analytically determined. The ideal linear observer, known as the Hotelling observer (HO), can sometimes be used as a surrogate for the IO. However, when image data are high dimensional, HO computation can be difficult. Efficient channels that can extract task-relevant features have been investigated to reduce the dimensionality of image data to approximate IO and HO performance. This work proposes a novel method for generating efficient channels by use of the gradient of a Lagrangian-based loss function that was designed to learn the HO. The generated channels are referred to as the Lagrangian-gradient (L-grad) channels. Numerical studies are conducted that consider binary signal detection tasks involving various backgrounds and signals. It is demonstrated that channelized HO (CHO) using L-grad channels can produce significantly better signal detection performance compared to the CHO using PLS channels. Moreover, it is shown that the proposed L-grad method can achieve significantly lower computation time compared to the PLS method.
Ambient Denoising Diffusion Generative Adversarial Networks for Establishing Stochastic Object Models from Noisy Image Data
Jan 31, 2025It is widely accepted that medical imaging systems should be objectively assessed via task-based image quality (IQ) measures that ideally account for all sources of randomness in the measured image data, including the variation in the ensemble of objects to be imaged. Stochastic object models (SOMs) that can randomly draw samples from the object distribution can be employed to characterize object variability. To establish realistic SOMs for task-based IQ analysis, it is desirable to employ experimental image data. However, experimental image data acquired from medical imaging systems are subject to measurement noise. Previous work investigated the ability of deep generative models (DGMs) that employ an augmented generative adversarial network (GAN), AmbientGAN, for establishing SOMs from noisy measured image data. Recently, denoising diffusion models (DDMs) have emerged as a leading DGM for image synthesis and can produce superior image quality than GANs. However, original DDMs possess a slow image-generation process because of the Gaussian assumption in the denoising steps. More recently, denoising diffusion GAN (DDGAN) was proposed to permit fast image generation while maintain high generated image quality that is comparable to the original DDMs. In this work, we propose an augmented DDGAN architecture, Ambient DDGAN (ADDGAN), for learning SOMs from noisy image data. Numerical studies that consider clinical computed tomography (CT) images and digital breast tomosynthesis (DBT) images are conducted. The ability of the proposed ADDGAN to learn realistic SOMs from noisy image data is demonstrated. It has been shown that the ADDGAN significantly outperforms the advanced AmbientGAN models for synthesizing high resolution medical images with complex textures.
Task-based Regularization in Penalized Least-Squares for Binary Signal Detection Tasks in Medical Image Denoising
Jan 31, 2025Image denoising algorithms have been extensively investigated for medical imaging. To perform image denoising, penalized least-squares (PLS) problems can be designed and solved, in which the penalty term encodes prior knowledge of the object being imaged. Sparsity-promoting penalties, such as total variation (TV), have been a popular choice for regularizing image denoising problems. However, such hand-crafted penalties may not be able to preserve task-relevant information in measured image data and can lead to oversmoothed image appearances and patchy artifacts that degrade signal detectability. Supervised learning methods that employ convolutional neural networks (CNNs) have emerged as a popular approach to denoising medical images. However, studies have shown that CNNs trained with loss functions based on traditional image quality measures can lead to a loss of task-relevant information in images. Some previous works have investigated task-based loss functions that employ model observers for training the CNN denoising models. However, such training processes typically require a large number of noisy and ground-truth (noise-free or low-noise) image data pairs. In this work, we propose a task-based regularization strategy for use with PLS in medical image denoising. The proposed task-based regularization is associated with the likelihood of linear test statistics of noisy images for Gaussian noise models. The proposed method does not require ground-truth image data and solves an individual optimization problem for denoising each image. Computer-simulation studies are conducted that consider a multivariate-normally distributed (MVN) lumpy background and a binary texture background. It is demonstrated that the proposed regularization strategy can effectively improve signal detectability in denoised images.
Unsupervised Generation of Pseudo Normal PET from MRI with Diffusion Model for Epileptic Focus Localization
Feb 02, 2024[$^{18}$F]fluorodeoxyglucose (FDG) positron emission tomography (PET) has emerged as a crucial tool in identifying the epileptic focus, especially in cases where magnetic resonance imaging (MRI) diagnosis yields indeterminate results. FDG PET can provide the metabolic information of glucose and help identify abnormal areas that are not easily found through MRI. However, the effectiveness of FDG PET-based assessment and diagnosis depends on the selection of a healthy control group. The healthy control group typically consists of healthy individuals similar to epilepsy patients in terms of age, gender, and other aspects for providing normal FDG PET data, which will be used as a reference for enhancing the accuracy and reliability of the epilepsy diagnosis. However, significant challenges arise when a healthy PET control group is unattainable. Yaakub \emph{et al.} have previously introduced a Pix2PixGAN-based method for MRI to PET translation. This method used paired MRI and FDG PET scans from healthy individuals for training, and produced pseudo normal FDG PET images from patient MRIs that are subsequently used for lesion detection. However, this approach requires a large amount of high-quality, paired MRI and PET images from healthy control subjects, which may not always be available. In this study, we investigated unsupervised learning methods for unpaired MRI to PET translation for generating pseudo normal FDG PET for epileptic focus localization. Two deep learning methods, CycleGAN and SynDiff, were employed, and we found that diffusion-based method achieved improved performance in accurately localizing the epileptic focus.
Ambient-Pix2PixGAN for Translating Medical Images from Noisy Data
Feb 02, 2024Image-to-image translation is a common task in computer vision and has been rapidly increasing the impact on the field of medical imaging. Deep learning-based methods that employ conditional generative adversarial networks (cGANs), such as Pix2PixGAN, have been extensively explored to perform image-to-image translation tasks. However, when noisy medical image data are considered, such methods cannot be directly applied to produce clean images. Recently, an augmented GAN architecture named AmbientGAN has been proposed that can be trained on noisy measurement data to synthesize high-quality clean medical images. Inspired by AmbientGAN, in this work, we propose a new cGAN architecture, Ambient-Pix2PixGAN, for performing medical image-to-image translation tasks by use of noisy measurement data. Numerical studies that consider MRI-to-PET translation are conducted. Both traditional image quality metrics and task-based image quality metrics are employed to assess the proposed Ambient-Pix2PixGAN. It is demonstrated that our proposed Ambient-Pix2PixGAN can be successfully trained on noisy measurement data to produce high-quality translated images in target imaging modality.
AmbientCycleGAN for Establishing Interpretable Stochastic Object Models Based on Mathematical Phantoms and Medical Imaging Measurements
Feb 02, 2024Medical imaging systems that are designed for producing diagnostically informative images should be objectively assessed via task-based measures of image quality (IQ). Ideally, computation of task-based measures of IQ needs to account for all sources of randomness in the measurement data, including the variability in the ensemble of objects to be imaged. To address this need, stochastic object models (SOMs) that can generate an ensemble of synthesized objects or phantoms can be employed. Various mathematical SOMs or phantoms were developed that can interpretably synthesize objects, such as lumpy object models and parameterized torso phantoms. However, such SOMs that are purely mathematically defined may not be able to comprehensively capture realistic object variations. To establish realistic SOMs, it is desirable to use experimental data. An augmented generative adversarial network (GAN), AmbientGAN, was recently proposed for establishing SOMs from medical imaging measurements. However, it remains unclear to which extent the AmbientGAN-produced objects can be interpretably controlled. This work introduces a novel approach called AmbientCycleGAN that translates mathematical SOMs to realistic SOMs by use of noisy measurement data. Numerical studies that consider clustered lumpy background (CLB) models and real mammograms are conducted. It is demonstrated that our proposed method can stably establish SOMs based on mathematical models and noisy measurement data. Moreover, the ability of the proposed AmbientCycleGAN to interpretably control image features in the synthesized objects is investigated.
Ideal Observer Computation by Use of Markov-Chain Monte Carlo with Generative Adversarial Networks
Apr 02, 2023
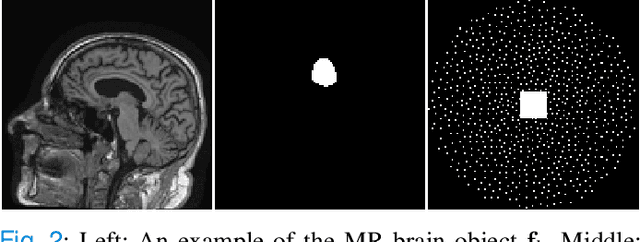

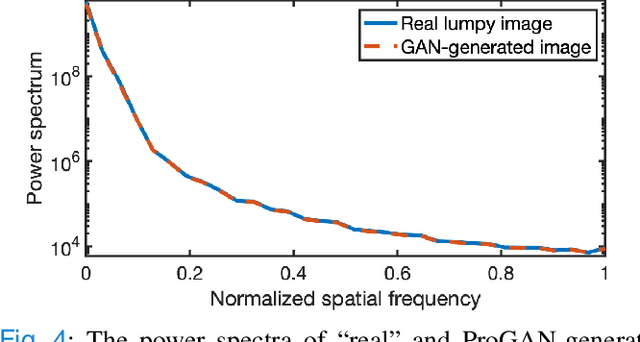
Medical imaging systems are often evaluated and optimized via objective, or task-specific, measures of image quality (IQ) that quantify the performance of an observer on a specific clinically-relevant task. The performance of the Bayesian Ideal Observer (IO) sets an upper limit among all observers, numerical or human, and has been advocated for use as a figure-of-merit (FOM) for evaluating and optimizing medical imaging systems. However, the IO test statistic corresponds to the likelihood ratio that is intractable to compute in the majority of cases. A sampling-based method that employs Markov-Chain Monte Carlo (MCMC) techniques was previously proposed to estimate the IO performance. However, current applications of MCMC methods for IO approximation have been limited to a small number of situations where the considered distribution of to-be-imaged objects can be described by a relatively simple stochastic object model (SOM). As such, there remains an important need to extend the domain of applicability of MCMC methods to address a large variety of scenarios where IO-based assessments are needed but the associated SOMs have not been available. In this study, a novel MCMC method that employs a generative adversarial network (GAN)-based SOM, referred to as MCMC-GAN, is described and evaluated. The MCMC-GAN method was quantitatively validated by use of test-cases for which reference solutions were available. The results demonstrate that the MCMC-GAN method can extend the domain of applicability of MCMC methods for conducting IO analyses of medical imaging systems.
A deep Q-learning method for optimizing visual search strategies in backgrounds of dynamic noise
Jan 28, 2022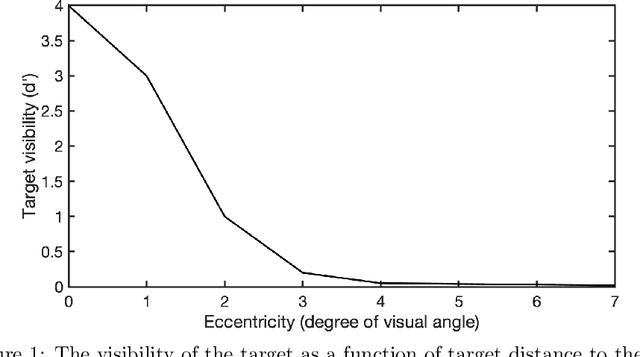
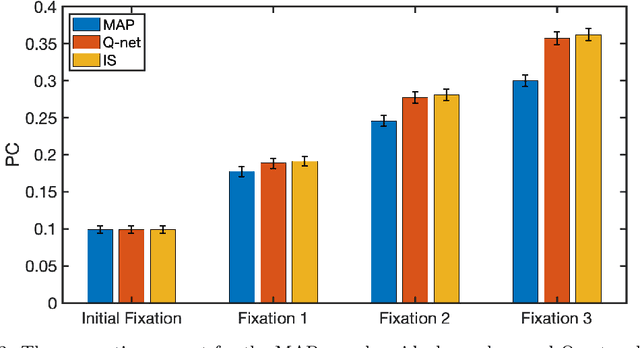
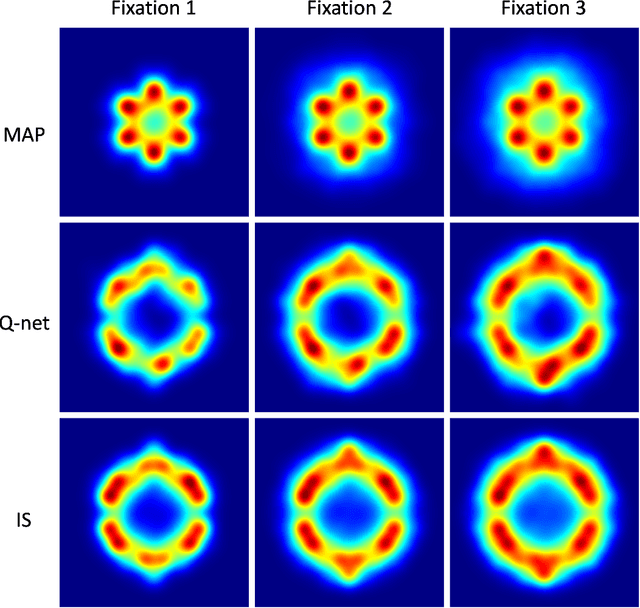
Humans process visual information with varying resolution (foveated visual system) and explore images by orienting through eye movements the high-resolution fovea to points of interest. The Bayesian ideal searcher (IS) that employs complete knowledge of task-relevant information optimizes eye movement strategy and achieves the optimal search performance. The IS can be employed as an important tool to evaluate the optimality of human eye movements, and potentially provide guidance to improve human observer visual search strategies. Najemnik and Geisler (2005) derived an IS for backgrounds of spatial 1/f noise. The corresponding template responses follow Gaussian distributions and the optimal search strategy can be analytically determined. However, the computation of the IS can be intractable when considering more realistic and complex backgrounds such as medical images. Modern reinforcement learning methods, successfully applied to obtain optimal policy for a variety of tasks, do not require complete knowledge of the background generating functions and can be potentially applied to anatomical backgrounds. An important first step is to validate the optimality of the reinforcement learning method. In this study, we investigate the ability of a reinforcement learning method that employs Q-network to approximate the IS. We demonstrate that the search strategy corresponding to the Q-network is consistent with the IS search strategy. The findings show the potential of the reinforcement learning with Q-network approach to estimate optimal eye movement planning with real anatomical backgrounds.
Supervised Learning-Enabled Ideal Observer Approximation for Joint Detection and Estimation Tasks
Oct 22, 2021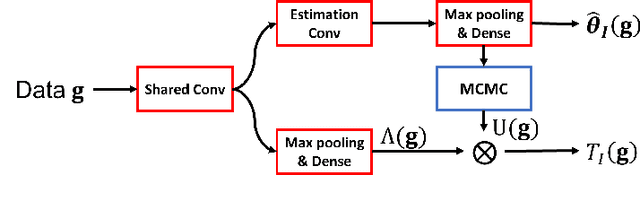
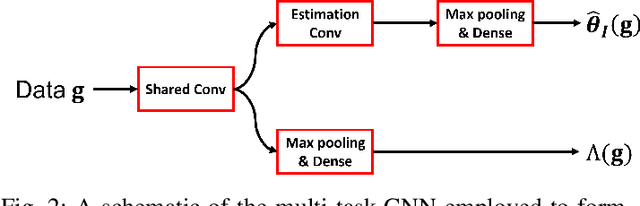


The ideal observer (IO) sets an upper performance limit among all observers and has been advocated for assessing and optimizing imaging systems. For general joint detection and estimation (detection-estimation) tasks, estimation ROC (EROC) analysis has been established for evaluating the performance of observers. However, in general, it is difficult to accurately approximate the IO that maximizes the area under the EROC curve. In this study, a hybrid method that employs machine learning is proposed to accomplish this. Specifically, a hybrid approach is developed that combines a multi-task convolutional neural network and a Markov-Chain Monte Carlo (MCMC) method in order to approximate the IO for detection-estimation tasks. In addition, a purely supervised learning-based sub-ideal observer is proposed. Computer-simulation studies are conducted to validate the proposed method, which include signal-known-statistically/background-known-exactly and signal-known-statistically/background-known-statistically tasks. The EROC curves produced by the proposed method are compared to those produced by the MCMC approach or analytical computation when feasible. The proposed method provides a new approach for approximating the IO and may advance the application of EROC analysis for optimizing imaging systems.