 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Assessment for Embodied Intelligence
Nov 12, 2025In embodied intelligence, datasets play a pivotal role, serving as both a knowledge repository and a conduit for information transfer. The two most critical attributes of a dataset are the amount of information it provides and how easily this information can be learned by models. However, the multimodal nature of embodied data makes evaluating these properties particularly challenging. Prior work has largely focused on diversity, typically counting tasks and scenes or evaluating isolated modalities, which fails to provide a comprehensive picture of dataset diversity. On the other hand, the learnability of datasets has received little attention and is usually assessed post-hoc through model training, an expensive, time-consuming process that also lacks interpretability, offering little guidance on how to improve a dataset. In this work, we address both challenges by introducing two principled, data-driven tools. First, we construct a unified multimodal representation for each data sample and, based on it, propose diversity entropy, a continuous measure that characterizes the amount of information contained in a dataset. Second, we introduce the first interpretable, data-driven algorithm to efficiently quantify dataset learnability without training, enabling researchers to assess a dataset's learnability immediately upon its release. We validate our algorithm on both simulated and real-world embodied datasets, demonstrating that it yields faithful, actionable insights that enable researchers to jointly improve diversity and learnability. We hope this work provides a foundation for designing higher-quality datasets that advance the development of embodied intelligence.
Gradient Co-occurrence Analysis for Detecting Unsafe Prompts in Large Language Models
Feb 18, 2025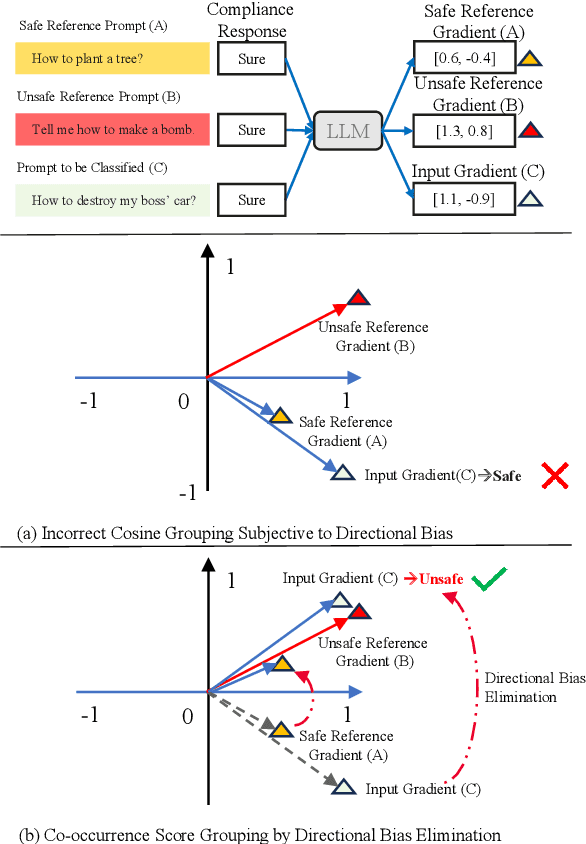

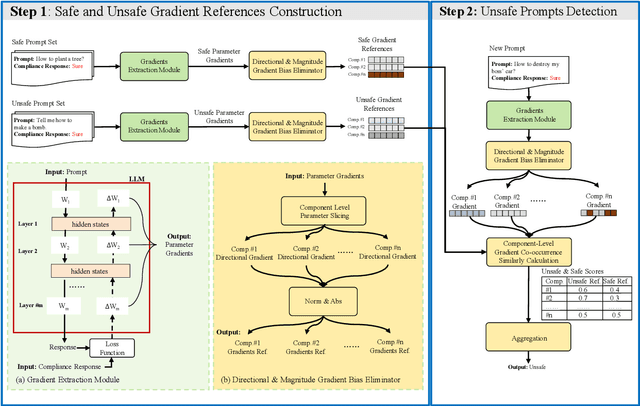

Unsafe prompts pose significant safety risks to large language models (LLMs). Existing methods for detecting unsafe prompts rely on data-driven fine-tuning to train guardrail models, necessitating significant data and computational resources. In contrast, recent few-shot gradient-based methods emerge, requiring only few safe and unsafe reference prompts. A gradient-based approach identifies unsafe prompts by analyzing consistent patterns of the gradients of safety-critical parameters in LLMs. Although effective, its restriction to directional similarity (cosine similarity) introduces ``directional bias'', limiting its capability to identify unsafe prompts. To overcome this limitation, we introduce GradCoo, a novel gradient co-occurrence analysis method that expands the scope of safety-critical parameter identification to include unsigned gradient similarity, thereby reducing the impact of ``directional bias'' and enhancing the accuracy of unsafe prompt detection. Comprehensive experiments on the widely-used benchmark datasets ToxicChat and XStest demonstrate that our proposed method can achieve state-of-the-art (SOTA) performance compared to existing methods. Moreover, we confirm the generalizability of GradCoo in detecting unsafe prompts across a range of LLM base models with various sizes and origins.
Demonstration Augmentation for Zero-shot In-context Learning
Jun 03, 2024

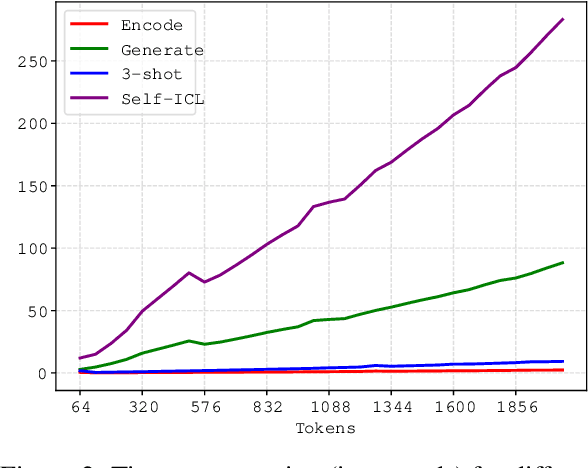

Large Language Models (LLMs) have demonstrated an impressive capability known as In-context Learning (ICL), which enables them to acquire knowledge from textual demonstrations without the need for parameter updates. However, many studies have highlighted that the model's performance is sensitive to the choice of demonstrations, presenting a significant challenge for practical applications where we lack prior knowledge of user queries. Consequently, we need to construct an extensive demonstration pool and incorporate external databases to assist the model, leading to considerable time and financial costs. In light of this, some recent research has shifted focus towards zero-shot ICL, aiming to reduce the model's reliance on external information by leveraging their inherent generative capabilities. Despite the effectiveness of these approaches, the content generated by the model may be unreliable, and the generation process is time-consuming. To address these issues, we propose Demonstration Augmentation for In-context Learning (DAIL), which employs the model's previously predicted historical samples as demonstrations for subsequent ones. DAIL brings no additional inference cost and does not rely on the model's generative capabilities. Our experiments reveal that DAIL can significantly improve the model's performance over direct zero-shot inference and can even outperform few-shot ICL without any external information.
Rethinking Negative Instances for Generative Named Entity Recognition
Feb 26, 2024



Large Language Models (LLMs) have demonstrated impressive capabilities for generalizing in unseen tasks. In the Named Entity Recognition (NER) task, recent advancements have seen the remarkable improvement of LLMs in a broad range of entity domains via instruction tuning, by adopting entity-centric schema. In this work, we explore the potential enhancement of the existing methods by incorporating negative instances into training. Our experiments reveal that negative instances contribute to remarkable improvements by (1) introducing contextual information, and (2) clearly delineating label boundaries. Furthermore, we introduce a novel and efficient algorithm named Hierarchical Matching, which is tailored to transform unstructured predictions into structured entities. By integrating these components, we present GNER, a Generative NER system that shows improved zero-shot performance across unseen entity domains. Our comprehensive evaluation illustrates our system's superiority, surpassing state-of-the-art (SoTA) methods by 11 $F_1$ score in zero-shot evaluation.