 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenmin University of China at TRECVID 2022: Improving Video Search by Feature Fusion and Negation Understanding
Nov 28, 2022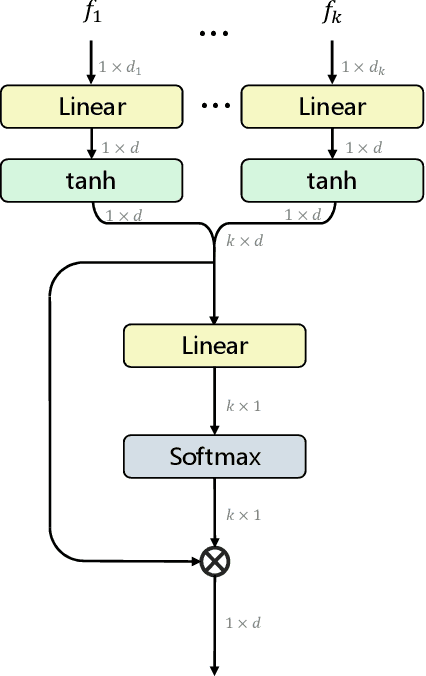


We summarize our TRECVID 2022 Ad-hoc Video Search (AVS) experiments. Our solution is built with two new techniques, namely Lightweight Attentional Feature Fusion (LAFF) for combining diverse visual / textual features and Bidirectional Negation Learning (BNL) for addressing queries that contain negation cues. In particular, LAFF performs feature fusion at both early and late stages and at both text and video ends to exploit diverse (off-the-shelf) features. Compared to multi-head self attention, LAFF is much more compact yet more effective. Its attentional weights can also be used for selecting fewer features, with the retrieval performance mostly preserved. BNL trains a negation-aware video retrieval model by minimizing a bidirectionally constrained loss per triplet, where a triplet consists of a given training video, its original description and a partially negated description. For video feature extraction, we use pre-trained CLIP, BLIP, BEiT, ResNeXt-101 and irCSN. As for text features, we adopt bag-of-words, word2vec, CLIP and BLIP. Our training data consists of MSR-VTT, TGIF and VATEX that were used in our previous participation. In addition, we automatically caption the V3C1 collection for pre-training. The 2022 edition of the TRECVID benchmark has again been a fruitful participation for the RUCMM team. Our best run, with an infAP of 0.262, is ranked at the second place teamwise.
MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection
Dec 16, 2021
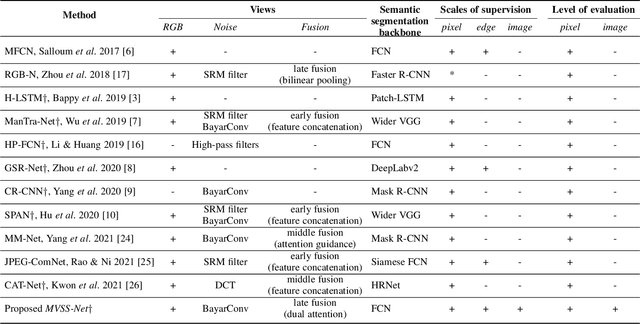
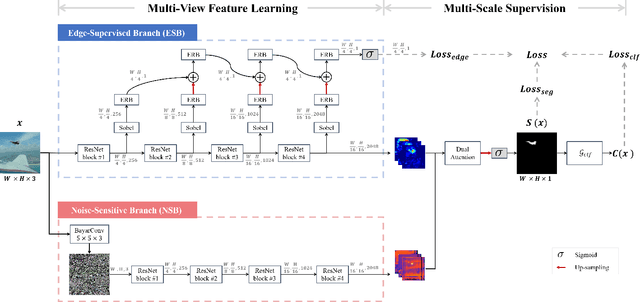
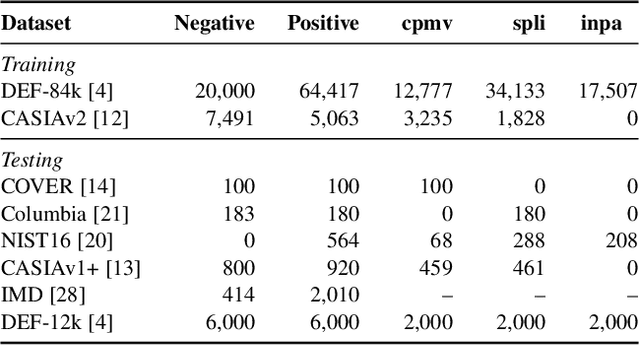
The key research question for image manipulation detection is how to learn generalizable features that are sensitive to manipulations in novel data, whilst specific to prevent false alarms on authentic images. Current research emphasizes the sensitivity, with the specificity mostly ignored. In this paper we address both aspects by multi-view feature learning and multi-scale supervision. By exploiting noise distribution and boundary artifacts surrounding tampered regions, the former aims to learn semantic-agnostic and thus more generalizable features. The latter allows us to learn from authentic images which are nontrivial to be taken into account by the prior art that relies on a semantic segmentation loss. Our thoughts are realized by a new network which we term MVSS-Net and its enhanced version MVSS-Net++. Comprehensive experiments on six public benchmark datasets justify the viability of the MVSS-Net series for both pixel-level and image-level manipulation detection.
Image Manipulation Detection by Multi-View Multi-Scale Supervision
Apr 14, 2021
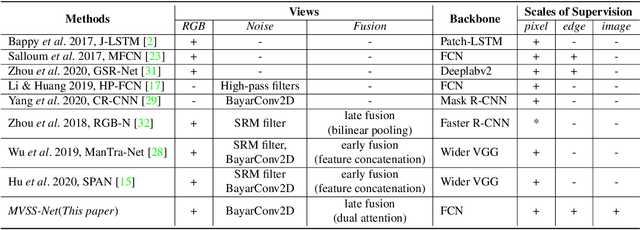
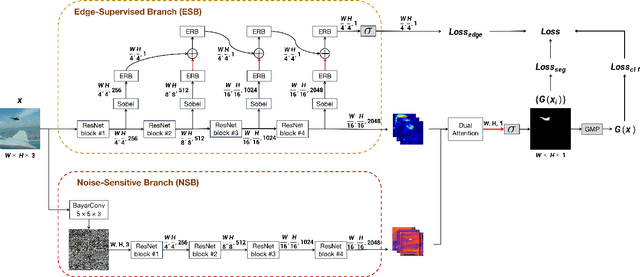
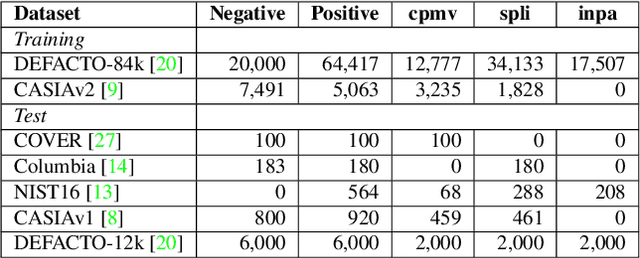
The key challenge of image manipulation detection is how to learn generalizable features that are sensitive to manipulations in novel data, whilst specific to prevent false alarms on authentic images. Current research emphasizes the sensitivity, with the specificity overlooked. In this paper we address both aspects by multi-view feature learning and multi-scale supervision. By exploiting noise distribution and boundary artifact surrounding tampered regions, the former aims to learn semantic-agnostic and thus more generalizable features. The latter allows us to learn from authentic images which are nontrivial to taken into account by current semantic segmentation network based methods. Our thoughts are realized by a new network which we term MVSS-Net. Extensive experiments on five benchmark sets justify the viability of MVSS-Net for both pixel-level and image-level manipulation detection.