 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Attentional Feature Fusion for Video Retrieval by Text
Paper and Code
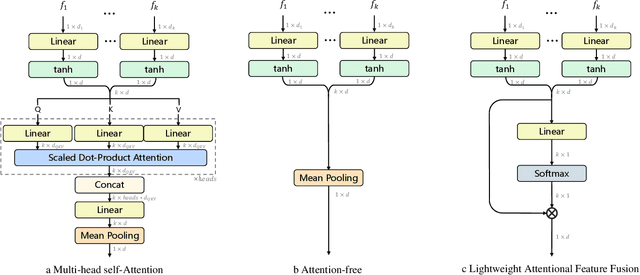

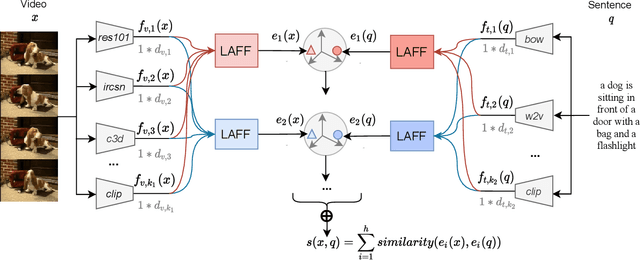
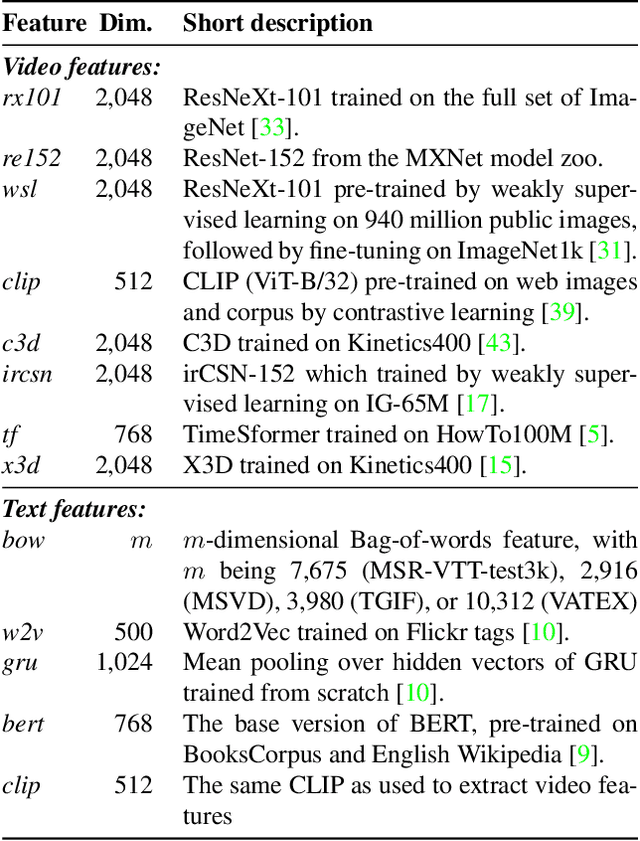
In this paper, we revisit \emph{feature fusion}, an old-fashioned topic, in the new context of video retrieval by text. Different from previous research that considers feature fusion only at one end, let it be video or text, we aim for feature fusion for both ends within a unified framework. We hypothesize that optimizing the convex combination of the features is preferred to modeling their correlations by computationally heavy multi-head self-attention. Accordingly, we propose Lightweight Attentional Feature Fusion (LAFF). LAFF performs feature fusion at both early and late stages and at both video and text ends, making it a powerful method for exploiting diverse (off-the-shelf) features. Extensive experiments on four public datasets, i.e. MSR-VTT, MSVD, TGIF, VATEX, and the large-scale TRECVID AVS benchmark evaluations (2016-2020) show the viability of LAFF. Moreover, LAFF is extremely simple to implement, making it appealing for real-world deployment.