 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonAgain: Using Extractable Symbolic Programs to Evaluate Mathematical Reasoning
Paper and Code
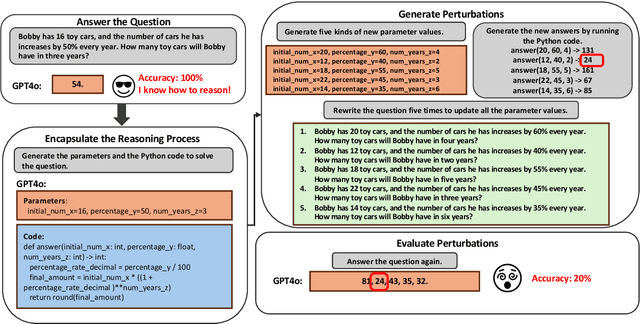
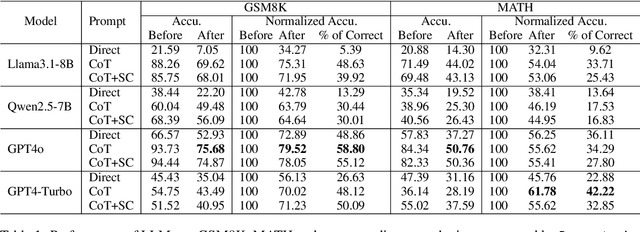
Existing math datasets evaluate the reasoning abilities of large language models (LLMs) by either using the final answer or the intermediate reasoning steps derived from static examples. However, the former approach fails to surface model's uses of shortcuts and wrong reasoning while the later poses challenges in accommodating alternative solutions. In this work, we seek to use symbolic programs as a means for automated evaluation if a model can consistently produce correct final answers across various inputs to the program. We begin by extracting programs for popular math datasets (GSM8K and MATH) using GPT4-o. For those executable programs verified using the original input-output pairs, they are found to encapsulate the proper reasoning required to solve the original text questions. We then prompt GPT4-o to generate new questions using alternative input-output pairs based the extracted program. We apply the resulting datasets to evaluate a collection of LLMs. In our experiments, we observe significant accuracy drops using our proposed evaluation compared with original static examples, suggesting the fragility of math reasoning in state-of-the-art LLMs.