 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIRD: A Trustworthy Bayesian Inference Framework for Large Language Models
Apr 18, 2024



Large language models primarily rely on inductive reasoning for decision making. This results in unreliable decisions when applied to real-world tasks that often present incomplete contexts and conditions. Thus, accurate probability estimation and appropriate interpretations are required to enhance decision-making reliability. In this paper, we propose a Bayesian inference framework called BIRD for large language models. BIRD provides controllable and interpretable probability estimation for model decisions, based on abductive factors, LLM entailment, as well as learnable deductive Bayesian modeling. Experiments show that BIRD produces probability estimations that align with human judgments over 65% of the time using open-sourced Llama models, outperforming the state-of-the-art GPT-4 by 35%. We also show that BIRD can be directly used for trustworthy decision making on many real-world applications.
CAT: Cross-Attention Transformer for One-Shot Object Detection
Apr 30, 2021
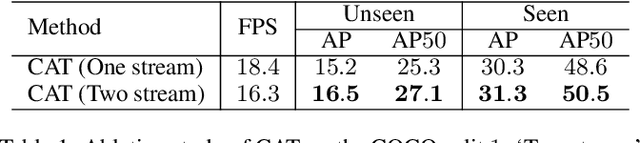
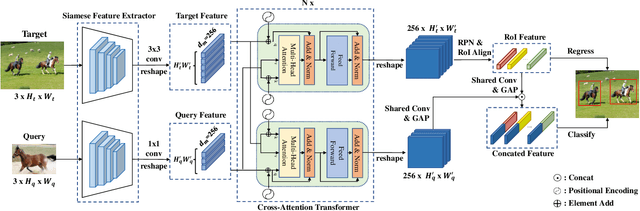
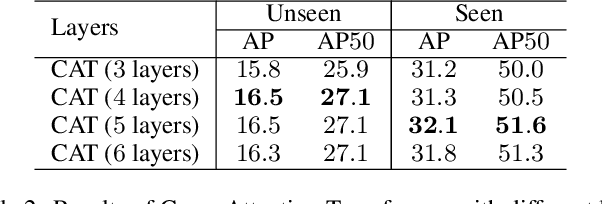
Given a query patch from a novel class, one-shot object detection aims to detect all instances of that class in a target image through the semantic similarity comparison. However, due to the extremely limited guidance in the novel class as well as the unseen appearance difference between query and target instances, it is difficult to appropriately exploit their semantic similarity and generalize well. To mitigate this problem, we present a universal Cross-Attention Transformer (CAT) module for accurate and efficient semantic similarity comparison in one-shot object detection. The proposed CAT utilizes transformer mechanism to comprehensively capture bi-directional correspondence between any paired pixels from the query and the target image, which empowers us to sufficiently exploit their semantic characteristics for accurate similarity comparison. In addition, the proposed CAT enables feature dimensionality compression for inference speedup without performance loss. Extensive experiments on COCO, VOC, and FSOD under one-shot settings demonstrate the effectiveness and efficiency of our method, e.g., it surpasses CoAE, a major baseline in this task by 1.0% in AP on COCO and runs nearly 2.5 times faster. Code will be available in the future.