 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-Conditional 3D Object Stylization and Composition
Dec 19, 2023Recently, 3D generative models have made impressive progress, enabling the generation of almost arbitrary 3D assets from text or image inputs. However, these approaches generate objects in isolation without any consideration for the scene where they will eventually be placed. In this paper, we propose a framework that allows for the stylization of an existing 3D asset to fit into a given 2D scene, and additionally produce a photorealistic composition as if the asset was placed within the environment. This not only opens up a new level of control for object stylization, for example, the same assets can be stylized to reflect changes in the environment, such as summer to winter or fantasy versus futuristic settings-but also makes the object-scene composition more controllable. We achieve this by combining modeling and optimizing the object's texture and environmental lighting through differentiable ray tracing with image priors from pre-trained text-to-image diffusion models. We demonstrate that our method is applicable to a wide variety of indoor and outdoor scenes and arbitrary objects.
Non-Contrastive Learning Meets Language-Image Pre-Training
Oct 17, 2022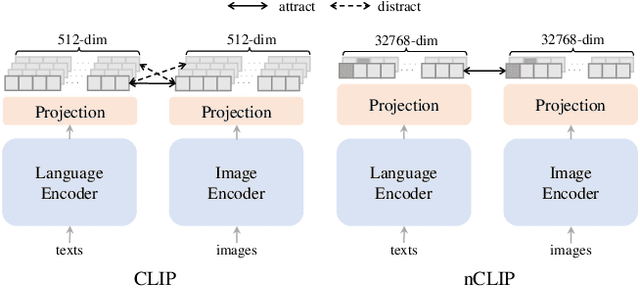

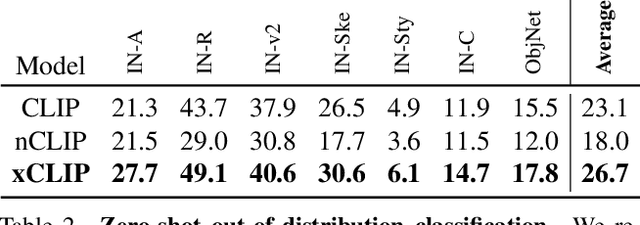
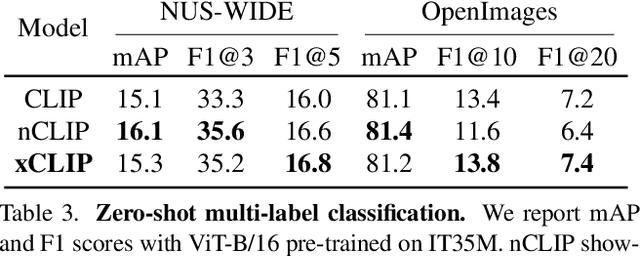
Contrastive language-image pre-training (CLIP) serves as a de-facto standard to align images and texts. Nonetheless, the loose correlation between images and texts of web-crawled data renders the contrastive objective data inefficient and craving for a large training batch size. In this work, we explore the validity of non-contrastive language-image pre-training (nCLIP), and study whether nice properties exhibited in visual self-supervised models can emerge. We empirically observe that the non-contrastive objective nourishes representation learning while sufficiently underperforming under zero-shot recognition. Based on the above study, we further introduce xCLIP, a multi-tasking framework combining CLIP and nCLIP, and show that nCLIP aids CLIP in enhancing feature semantics. The synergy between two objectives lets xCLIP enjoy the best of both worlds: superior performance in both zero-shot transfer and representation learning. Systematic evaluation is conducted spanning a wide variety of downstream tasks including zero-shot classification, out-of-domain classification, retrieval, visual representation learning, and textual representation learning, showcasing a consistent performance gain and validating the effectiveness of xCLIP.
Exploring Target Representations for Masked Autoencoders
Sep 08, 2022
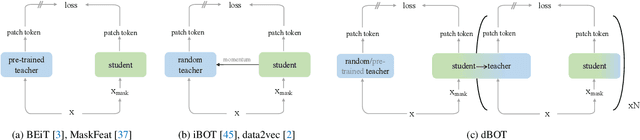
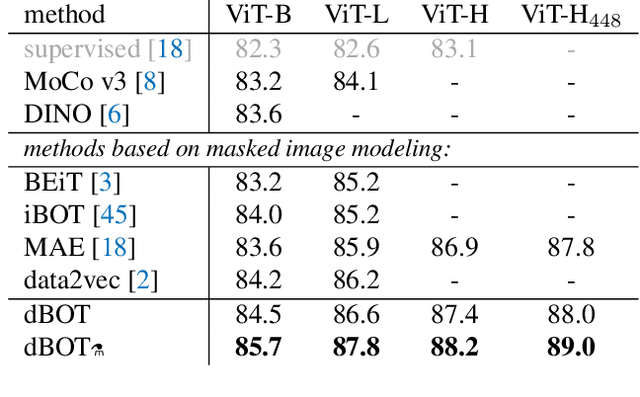
Masked autoencoders have become popular training paradigms for self-supervised visual representation learning. These models randomly mask a portion of the input and reconstruct the masked portion according to the target representations. In this paper, we first show that a careful choice of the target representation is unnecessary for learning good representations, since different targets tend to derive similarly behaved models. Driven by this observation, we propose a multi-stage masked distillation pipeline and use a randomly initialized model as the teacher, enabling us to effectively train high-capacity models without any efforts to carefully design target representations. Interestingly, we further explore using teachers of larger capacity, obtaining distilled students with remarkable transferring ability. On different tasks of classification, transfer learning, object detection, and semantic segmentation, the proposed method to perform masked knowledge distillation with bootstrapped teachers (dBOT) outperforms previous self-supervised methods by nontrivial margins. We hope our findings, as well as the proposed method, could motivate people to rethink the roles of target representations in pre-training masked autoencoders.
iBOT: Image BERT Pre-Training with Online Tokenizer
Nov 15, 2021
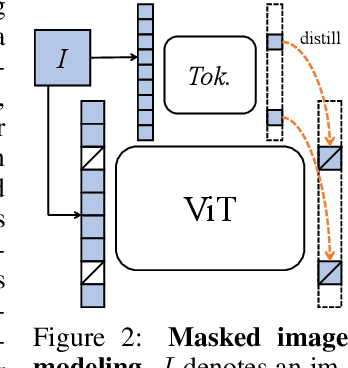
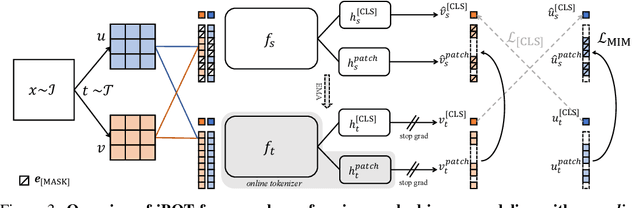
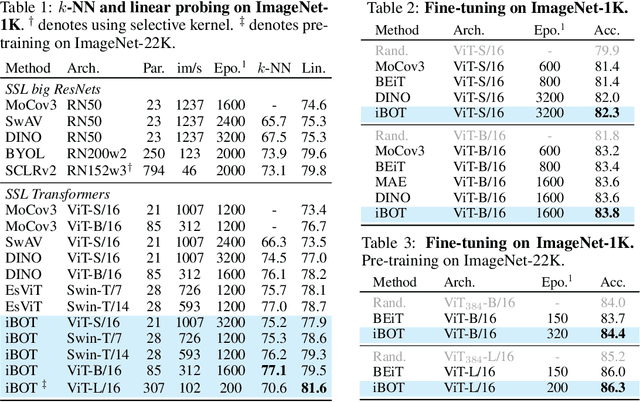
The success of language Transformers is primarily attributed to the pretext task of masked language modeling (MLM), where texts are first tokenized into semantically meaningful pieces. In this work, we study masked image modeling (MIM) and indicate the advantages and challenges of using a semantically meaningful visual tokenizer. We present a self-supervised framework iBOT that can perform masked prediction with an online tokenizer. Specifically, we perform self-distillation on masked patch tokens and take the teacher network as the online tokenizer, along with self-distillation on the class token to acquire visual semantics. The online tokenizer is jointly learnable with the MIM objective and dispenses with a multi-stage training pipeline where the tokenizer needs to be pre-trained beforehand. We show the prominence of iBOT by achieving an 81.6% linear probing accuracy and an 86.3% fine-tuning accuracy evaluated on ImageNet-1K. Beyond the state-of-the-art image classification results, we underline emerging local semantic patterns, which helps the models to obtain strong robustness against common corruptions and achieve leading results on dense downstream tasks, eg., object detection, instance segmentation, and semantic segmentation.
Semi-Supervised Segmentation of Radiation-Induced Pulmonary Fibrosis from Lung CT Scans with Multi-Scale Guided Dense Attention
Sep 29, 2021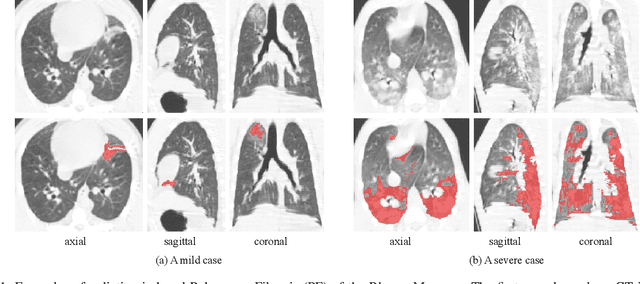
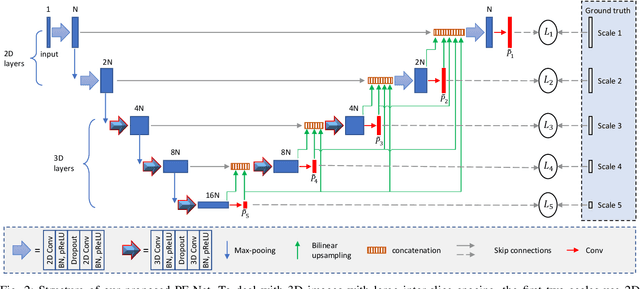
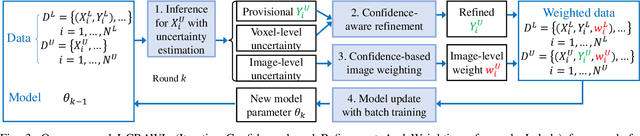
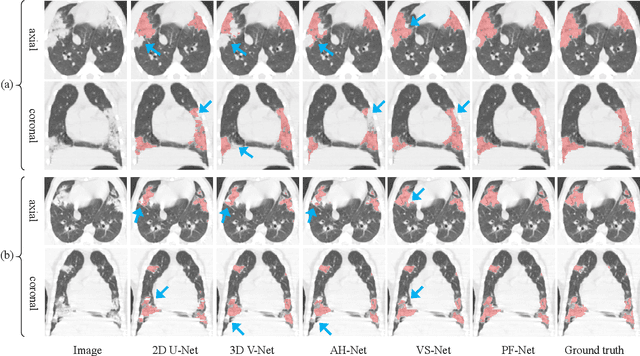
Computed Tomography (CT) plays an important role in monitoring radiation-induced Pulmonary Fibrosis (PF), where accurate segmentation of the PF lesions is highly desired for diagnosis and treatment follow-up. However, the task is challenged by ambiguous boundary, irregular shape, various position and size of the lesions, as well as the difficulty in acquiring a large set of annotated volumetric images for training. To overcome these problems, we propose a novel convolutional neural network called PF-Net and incorporate it into a semi-supervised learning framework based on Iterative Confidence-based Refinement And Weighting of pseudo Labels (I-CRAWL). Our PF-Net combines 2D and 3D convolutions to deal with CT volumes with large inter-slice spacing, and uses multi-scale guided dense attention to segment complex PF lesions. For semi-supervised learning, our I-CRAWL employs pixel-level uncertainty-based confidence-aware refinement to improve the accuracy of pseudo labels of unannotated images, and uses image-level uncertainty for confidence-based image weighting to suppress low-quality pseudo labels in an iterative training process. Extensive experiments with CT scans of Rhesus Macaques with radiation-induced PF showed that: 1) PF-Net achieved higher segmentation accuracy than existing 2D, 3D and 2.5D neural networks, and 2) I-CRAWL outperformed state-of-the-art semi-supervised learning methods for the PF lesion segmentation task. Our method has a potential to improve the diagnosis of PF and clinical assessment of side effects of radiotherapy for lung cancers.
CAT: Cross-Attention Transformer for One-Shot Object Detection
Apr 30, 2021
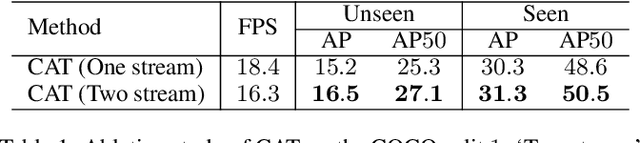
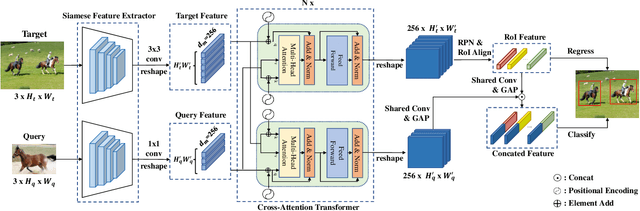
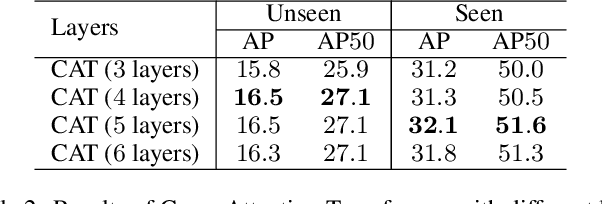
Given a query patch from a novel class, one-shot object detection aims to detect all instances of that class in a target image through the semantic similarity comparison. However, due to the extremely limited guidance in the novel class as well as the unseen appearance difference between query and target instances, it is difficult to appropriately exploit their semantic similarity and generalize well. To mitigate this problem, we present a universal Cross-Attention Transformer (CAT) module for accurate and efficient semantic similarity comparison in one-shot object detection. The proposed CAT utilizes transformer mechanism to comprehensively capture bi-directional correspondence between any paired pixels from the query and the target image, which empowers us to sufficiently exploit their semantic characteristics for accurate similarity comparison. In addition, the proposed CAT enables feature dimensionality compression for inference speedup without performance loss. Extensive experiments on COCO, VOC, and FSOD under one-shot settings demonstrate the effectiveness and efficiency of our method, e.g., it surpasses CoAE, a major baseline in this task by 1.0% in AP on COCO and runs nearly 2.5 times faster. Code will be available in the future.
Instance and Pair-Aware Dynamic Networks for Re-Identification
Mar 29, 2021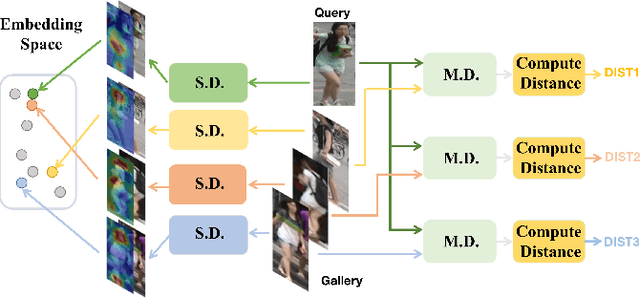
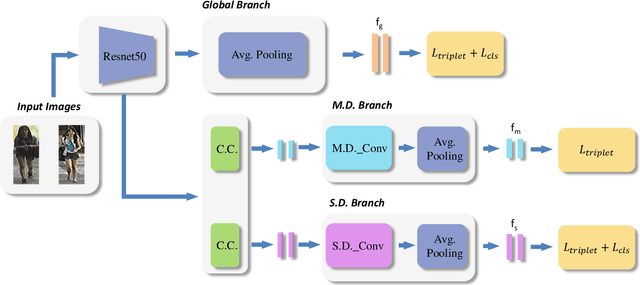
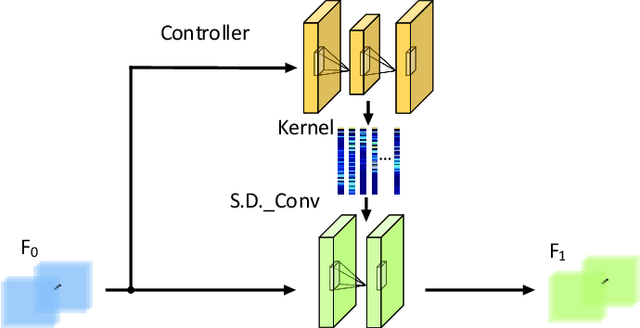
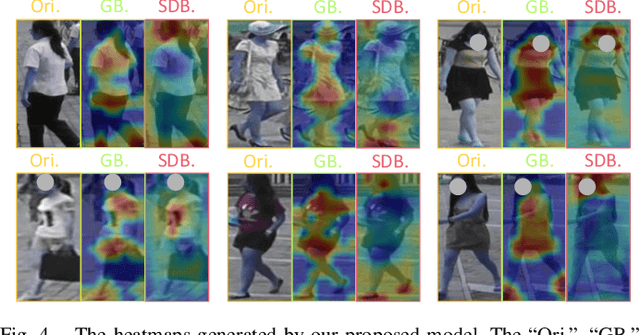
Re-identification (ReID) is to identify the same instance across different cameras. Existing ReID methods mostly utilize alignment-based or attention-based strategies to generate effective feature representations. However, most of these methods only extract general feature by employing single input image itself, overlooking the exploration of relevance between comparing images. To fill this gap, we propose a novel end-to-end trainable dynamic convolution framework named Instance and Pair-Aware Dynamic Networks in this paper. The proposed model is composed of three main branches where a self-guided dynamic branch is constructed to strengthen instance-specific features, focusing on every single image. Furthermore, we also design a mutual-guided dynamic branch to generate pair-aware features for each pair of images to be compared. Extensive experiments are conducted in order to verify the effectiveness of our proposed algorithm. We evaluate our algorithm in several mainstream person and vehicle ReID datasets including CUHK03, DukeMTMCreID, Market-1501, VeRi776 and VehicleID. In some datasets our algorithm outperforms state-of-the-art methods and in others, our algorithm achieves a comparable performance.
Real-Time Visual Object Tracking via Few-Shot Learning
Mar 18, 2021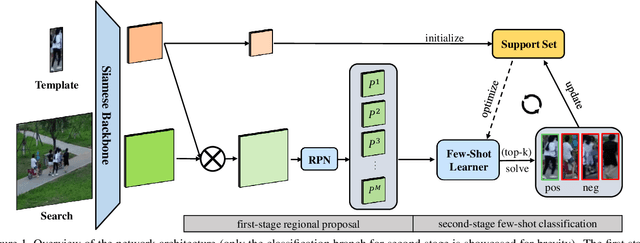
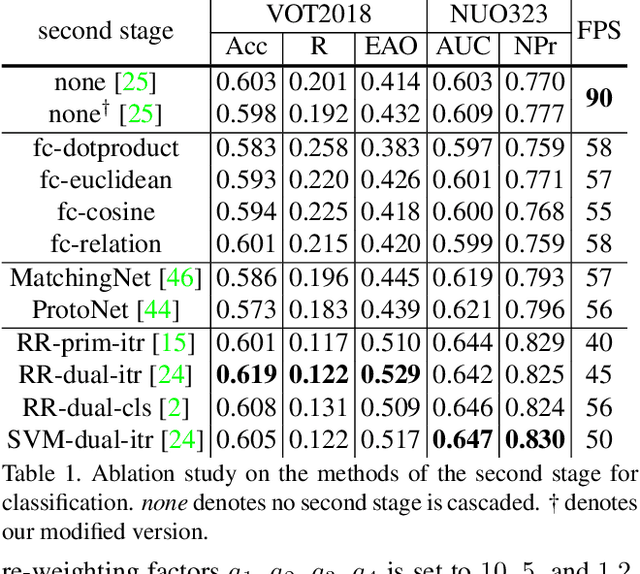
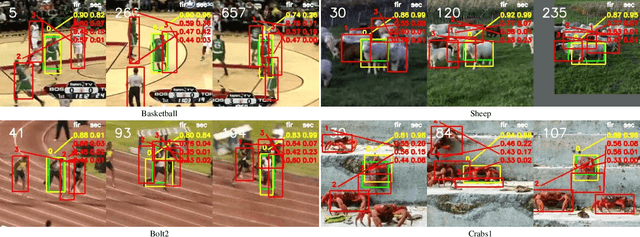

Visual Object Tracking (VOT) can be seen as an extended task of Few-Shot Learning (FSL). While the concept of FSL is not new in tracking and has been previously applied by prior works, most of them are tailored to fit specific types of FSL algorithms and may sacrifice running speed. In this work, we propose a generalized two-stage framework that is capable of employing a large variety of FSL algorithms while presenting faster adaptation speed. The first stage uses a Siamese Regional Proposal Network to efficiently propose the potential candidates and the second stage reformulates the task of classifying these candidates to a few-shot classification problem. Following such a coarse-to-fine pipeline, the first stage proposes informative sparse samples for the second stage, where a large variety of FSL algorithms can be conducted more conveniently and efficiently. As substantiation of the second stage, we systematically investigate several forms of optimization-based few-shot learners from previous works with different objective functions, optimization methods, or solution space. Beyond that, our framework also entails a direct application of the majority of other FSL algorithms to visual tracking, enabling mutual communication between researchers on these two topics. Extensive experiments on the major benchmarks, VOT2018, OTB2015, NFS, UAV123, TrackingNet, and GOT-10k are conducted, demonstrating a desirable performance gain and a real-time speed.
Higher Performance Visual Tracking with Dual-Modal Localization
Mar 18, 2021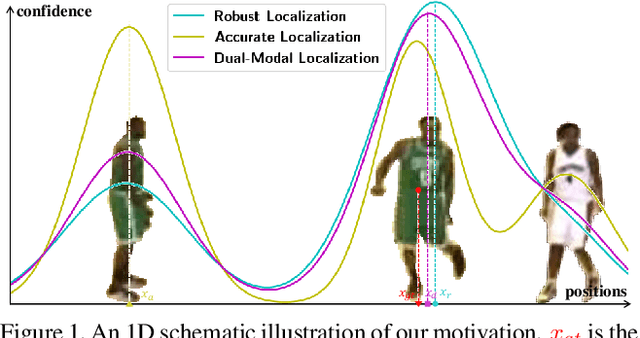

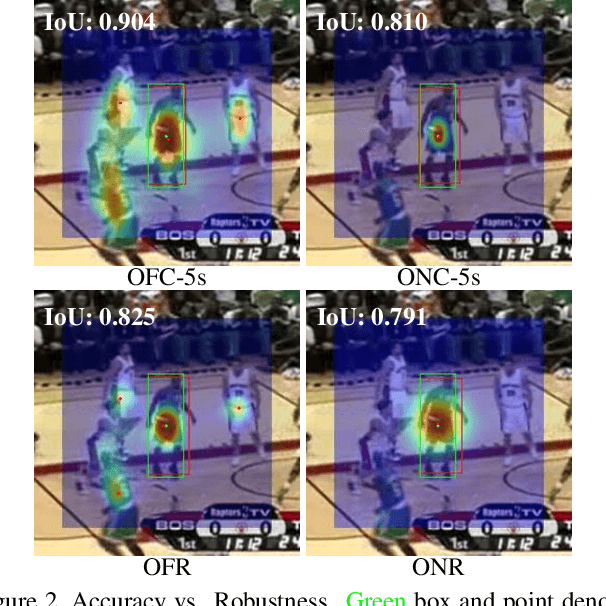
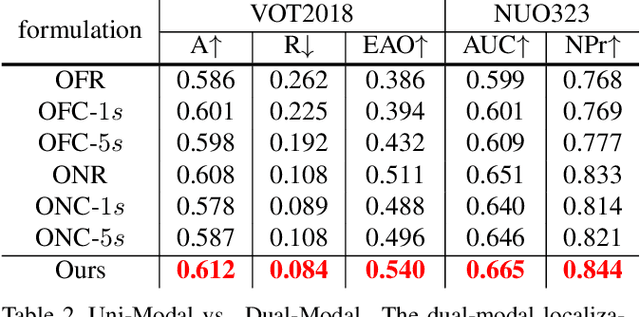
Visual Object Tracking (VOT) has synchronous needs for both robustness and accuracy. While most existing works fail to operate simultaneously on both, we investigate in this work the problem of conflicting performance between accuracy and robustness. We first conduct a systematic comparison among existing methods and analyze their restrictions in terms of accuracy and robustness. Specifically, 4 formulations-offline classification (OFC), offline regression (OFR), online classification (ONC), and online regression (ONR)-are considered, categorized by the existence of online update and the types of supervision signal. To account for the problem, we resort to the idea of ensemble and propose a dual-modal framework for target localization, consisting of robust localization suppressing distractors via ONR and the accurate localization attending to the target center precisely via OFC. To yield a final representation (i.e, bounding box), we propose a simple but effective score voting strategy to involve adjacent predictions such that the final representation does not commit to a single location. Operating beyond the real-time demand, our proposed method is further validated on 8 datasets-VOT2018, VOT2019, OTB2015, NFS, UAV123, LaSOT, TrackingNet, and GOT-10k, achieving state-of-the-art performance.
Pluggable Weakly-Supervised Cross-View Learning for Accurate Vehicle Re-Identification
Mar 09, 2021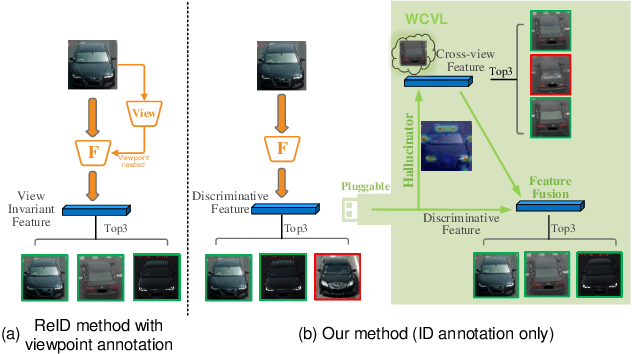

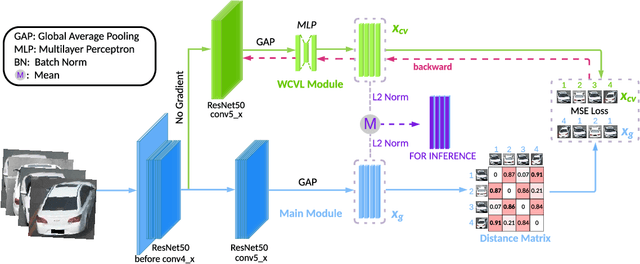
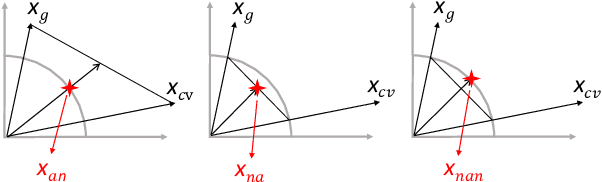
Learning cross-view consistent feature representation is the key for accurate vehicle Re-identification (ReID), since the visual appearance of vehicles changes significantly under different viewpoints. To this end, most existing approaches resort to the supervised cross-view learning using extensive extra viewpoints annotations, which however, is difficult to deploy in real applications due to the expensive labelling cost and the continous viewpoint variation that makes it hard to define discrete viewpoint labels. In this study, we present a pluggable Weakly-supervised Cross-View Learning (WCVL) module for vehicle ReID. Through hallucinating the cross-view samples as the hardest positive counterparts in feature domain, we can learn the consistent feature representation via minimizing the cross-view feature distance based on vehicle IDs only without using any viewpoint annotation. More importantly, the proposed method can be seamlessly plugged into most existing vehicle ReID baselines for cross-view learning without re-training the baselines. To demonstrate its efficacy, we plug the proposed method into a bunch of off-the-shelf baselines and obtain significant performance improvement on four public benchmark datasets, i.e., VeRi-776, VehicleID, VRIC and VRAI.