 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Accurate Siamese Tracking
Apr 04, 2022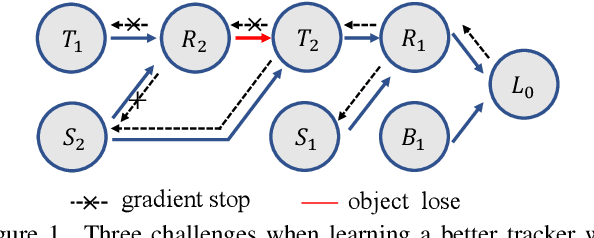
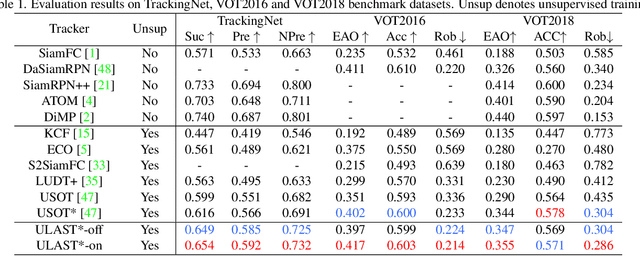
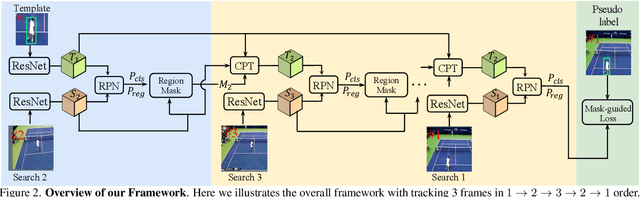
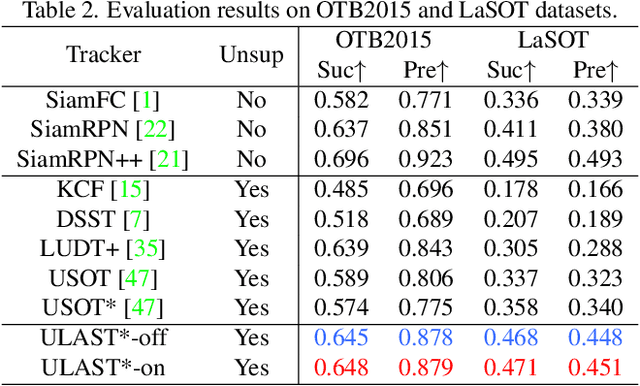
Unsupervised learning has been popular in various computer vision tasks, including visual object tracking. However, prior unsupervised tracking approaches rely heavily on spatial supervision from template-search pairs and are still unable to track objects with strong variation over a long time span. As unlimited self-supervision signals can be obtained by tracking a video along a cycle in time, we investigate evolving a Siamese tracker by tracking videos forward-backward. We present a novel unsupervised tracking framework, in which we can learn temporal correspondence both on the classification branch and regression branch. Specifically, to propagate reliable template feature in the forward propagation process so that the tracker can be trained in the cycle, we first propose a consistency propagation transformation. We then identify an ill-posed penalty problem in conventional cycle training in backward propagation process. Thus, a differentiable region mask is proposed to select features as well as to implicitly penalize tracking errors on intermediate frames. Moreover, since noisy labels may degrade training, we propose a mask-guided loss reweighting strategy to assign dynamic weights based on the quality of pseudo labels. In extensive experiments, our tracker outperforms preceding unsupervised methods by a substantial margin, performing on par with supervised methods on large-scale datasets such as TrackingNet and LaSOT. Code is available at https://github.com/FlorinShum/ULAST.
Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking
Mar 10, 2022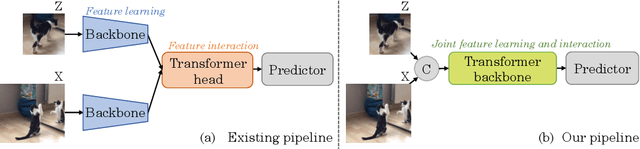
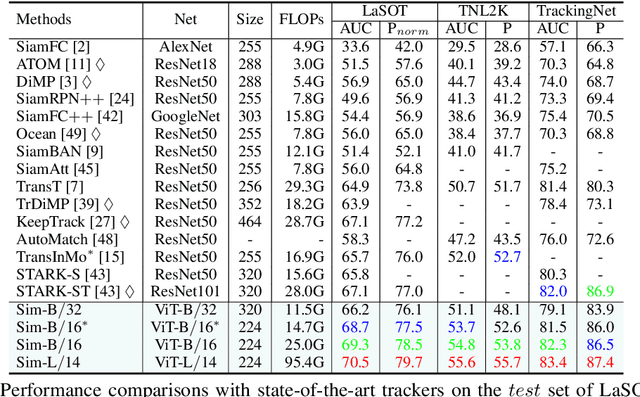
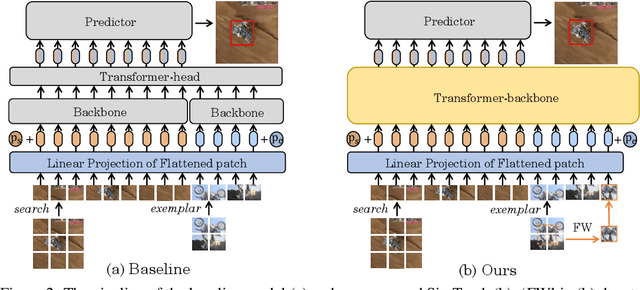
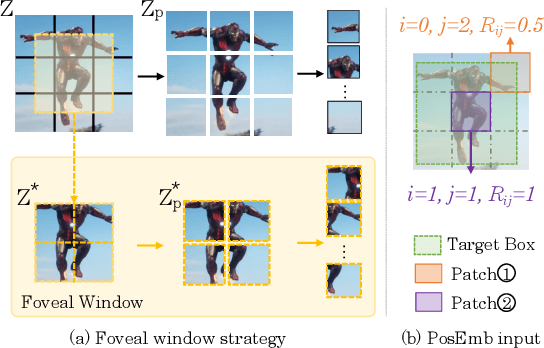
Exploiting a general-purpose neural architecture to replace hand-wired designs or inductive biases has recently drawn extensive interest. However, existing tracking approaches rely on customized sub-modules and need prior knowledge for architecture selection, hindering the tracking development in a more general system. This paper presents a Simplified Tracking architecture (SimTrack) by leveraging a transformer backbone for joint feature extraction and interaction. Unlike existing Siamese trackers, we serialize the input images and concatenate them directly before the one-branch backbone. Feature interaction in the backbone helps to remove well-designed interaction modules and produce a more efficient and effective framework. To reduce the information loss from down-sampling in vision transformers, we further propose a foveal window strategy, providing more diverse input patches with acceptable computational costs. Our SimTrack improves the baseline with 2.5%/2.6% AUC gains on LaSOT/TNL2K and gets results competitive with other specialized tracking algorithms without bells and whistles.
BN-NAS: Neural Architecture Search with Batch Normalization
Aug 16, 2021
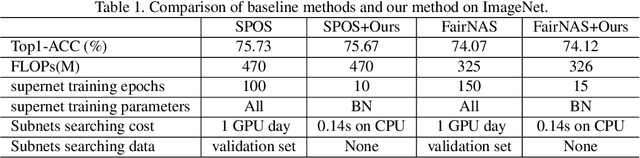
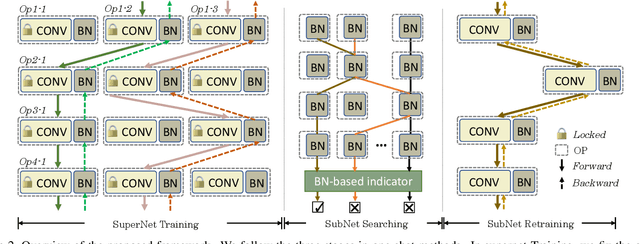
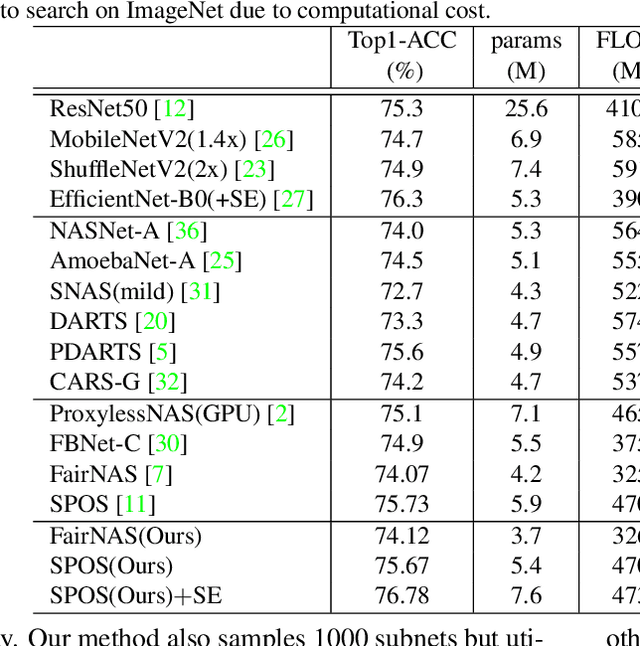
We present BN-NAS, neural architecture search with Batch Normalization (BN-NAS), to accelerate neural architecture search (NAS). BN-NAS can significantly reduce the time required by model training and evaluation in NAS. Specifically, for fast evaluation, we propose a BN-based indicator for predicting subnet performance at a very early training stage. The BN-based indicator further facilitates us to improve the training efficiency by only training the BN parameters during the supernet training. This is based on our observation that training the whole supernet is not necessary while training only BN parameters accelerates network convergence for network architecture search. Extensive experiments show that our method can significantly shorten the time of training supernet by more than 10 times and shorten the time of evaluating subnets by more than 600,000 times without losing accuracy.
PSViT: Better Vision Transformer via Token Pooling and Attention Sharing
Aug 07, 2021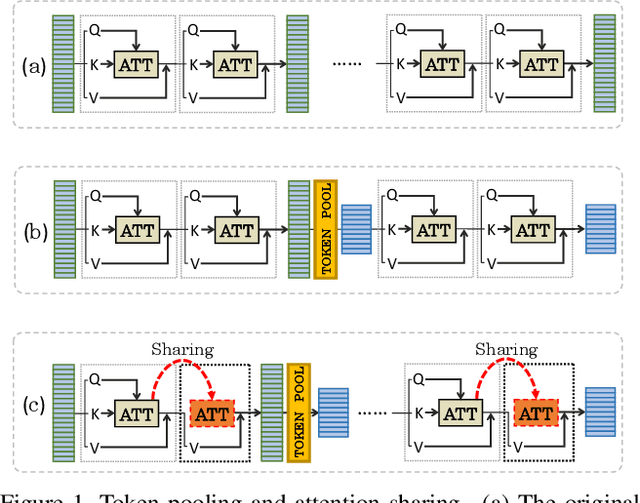



In this paper, we observe two levels of redundancies when applying vision transformers (ViT) for image recognition. First, fixing the number of tokens through the whole network produces redundant features at the spatial level. Second, the attention maps among different transformer layers are redundant. Based on the observations above, we propose a PSViT: a ViT with token Pooling and attention Sharing to reduce the redundancy, effectively enhancing the feature representation ability, and achieving a better speed-accuracy trade-off. Specifically, in our PSViT, token pooling can be defined as the operation that decreases the number of tokens at the spatial level. Besides, attention sharing will be built between the neighboring transformer layers for reusing the attention maps having a strong correlation among adjacent layers. Then, a compact set of the possible combinations for different token pooling and attention sharing mechanisms are constructed. Based on the proposed compact set, the number of tokens in each layer and the choices of layers sharing attention can be treated as hyper-parameters that are learned from data automatically. Experimental results show that the proposed scheme can achieve up to 6.6% accuracy improvement in ImageNet classification compared with the DeiT.
GLiT: Neural Architecture Search for Global and Local Image Transformer
Jul 07, 2021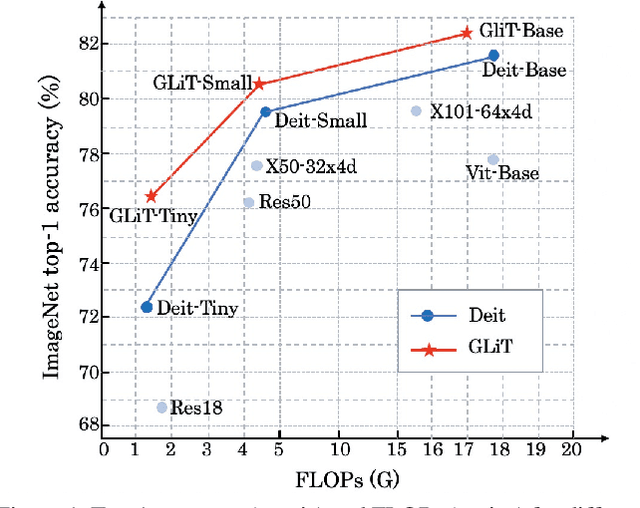

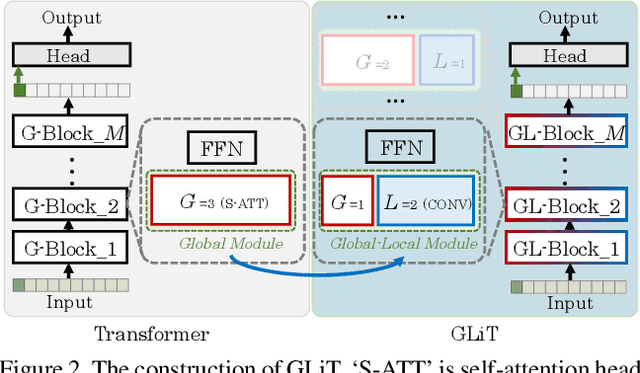

We introduce the first Neural Architecture Search (NAS) method to find a better transformer architecture for image recognition. Recently, transformers without CNN-based backbones are found to achieve impressive performance for image recognition. However, the transformer is designed for NLP tasks and thus could be sub-optimal when directly used for image recognition. In order to improve the visual representation ability for transformers, we propose a new search space and searching algorithm. Specifically, we introduce a locality module that models the local correlations in images explicitly with fewer computational cost. With the locality module, our search space is defined to let the search algorithm freely trade off between global and local information as well as optimizing the low-level design choice in each module. To tackle the problem caused by huge search space, a hierarchical neural architecture search method is proposed to search the optimal vision transformer from two levels separately with the evolutionary algorithm. Extensive experiments on the ImageNet dataset demonstrate that our method can find more discriminative and efficient transformer variants than the ResNet family (e.g., ResNet101) and the baseline ViT for image classification.
Real-Time Visual Object Tracking via Few-Shot Learning
Mar 18, 2021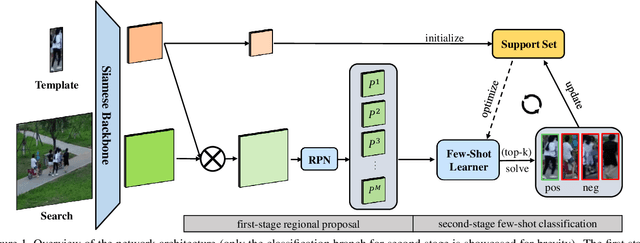
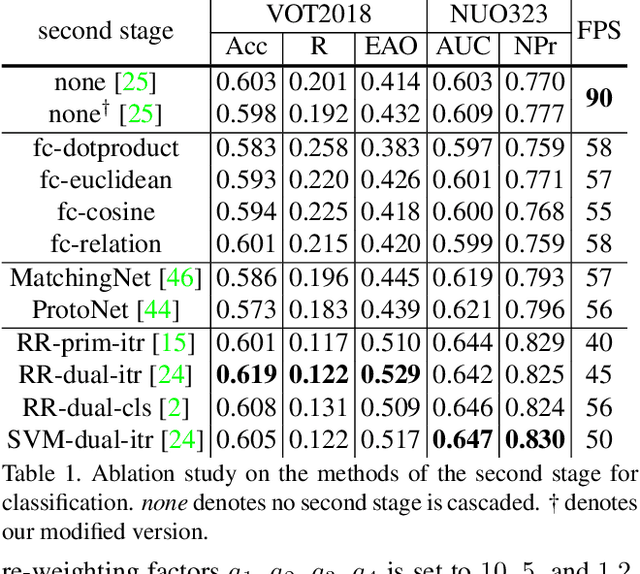
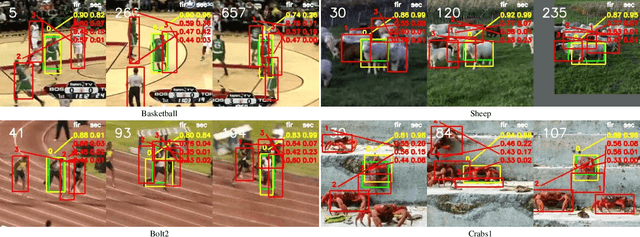

Visual Object Tracking (VOT) can be seen as an extended task of Few-Shot Learning (FSL). While the concept of FSL is not new in tracking and has been previously applied by prior works, most of them are tailored to fit specific types of FSL algorithms and may sacrifice running speed. In this work, we propose a generalized two-stage framework that is capable of employing a large variety of FSL algorithms while presenting faster adaptation speed. The first stage uses a Siamese Regional Proposal Network to efficiently propose the potential candidates and the second stage reformulates the task of classifying these candidates to a few-shot classification problem. Following such a coarse-to-fine pipeline, the first stage proposes informative sparse samples for the second stage, where a large variety of FSL algorithms can be conducted more conveniently and efficiently. As substantiation of the second stage, we systematically investigate several forms of optimization-based few-shot learners from previous works with different objective functions, optimization methods, or solution space. Beyond that, our framework also entails a direct application of the majority of other FSL algorithms to visual tracking, enabling mutual communication between researchers on these two topics. Extensive experiments on the major benchmarks, VOT2018, OTB2015, NFS, UAV123, TrackingNet, and GOT-10k are conducted, demonstrating a desirable performance gain and a real-time speed.
GradNet: Gradient-Guided Network for Visual Object Tracking
Sep 15, 2019



The fully-convolutional siamese network based on template matching has shown great potentials in visual tracking. During testing, the template is fixed with the initial target feature and the performance totally relies on the general matching ability of the siamese network. However, this manner cannot capture the temporal variations of targets or background clutter. In this work, we propose a novel gradient-guided network to exploit the discriminative information in gradients and update the template in the siamese network through feed-forward and backward operations. Our algorithm performs feed-forward and backward operations to exploit the discriminative informaiton in gradients and capture the core attention of the target. To be specific, the algorithm can utilize the information from the gradient to update the template in the current frame. In addition, a template generalization training method is proposed to better use gradient information and avoid overfitting. To our knowledge, this work is the first attempt to exploit the information in the gradient for template update in siamese-based trackers. Extensive experiments on recent benchmarks demonstrate that our method achieves better performance than other state-of-the-art trackers.