 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Cross-Attention Transformer for One-Shot Object Detection
Apr 30, 2021
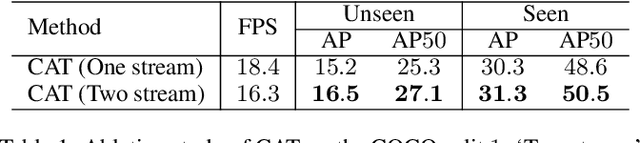
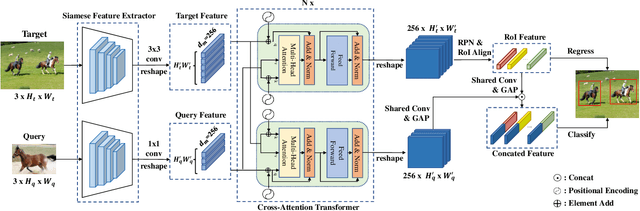
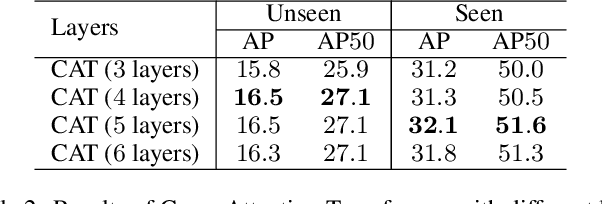
Given a query patch from a novel class, one-shot object detection aims to detect all instances of that class in a target image through the semantic similarity comparison. However, due to the extremely limited guidance in the novel class as well as the unseen appearance difference between query and target instances, it is difficult to appropriately exploit their semantic similarity and generalize well. To mitigate this problem, we present a universal Cross-Attention Transformer (CAT) module for accurate and efficient semantic similarity comparison in one-shot object detection. The proposed CAT utilizes transformer mechanism to comprehensively capture bi-directional correspondence between any paired pixels from the query and the target image, which empowers us to sufficiently exploit their semantic characteristics for accurate similarity comparison. In addition, the proposed CAT enables feature dimensionality compression for inference speedup without performance loss. Extensive experiments on COCO, VOC, and FSOD under one-shot settings demonstrate the effectiveness and efficiency of our method, e.g., it surpasses CoAE, a major baseline in this task by 1.0% in AP on COCO and runs nearly 2.5 times faster. Code will be available in the future.
A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition
Apr 02, 2019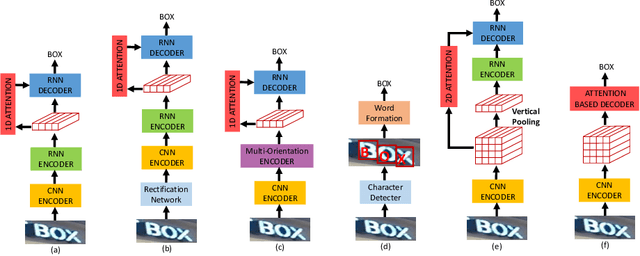
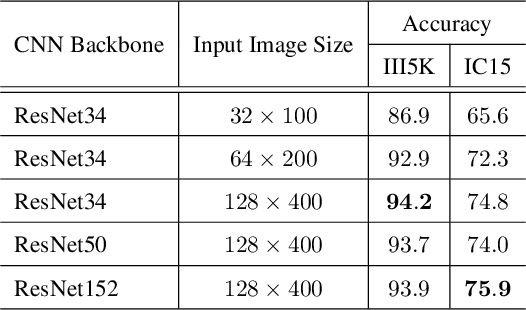
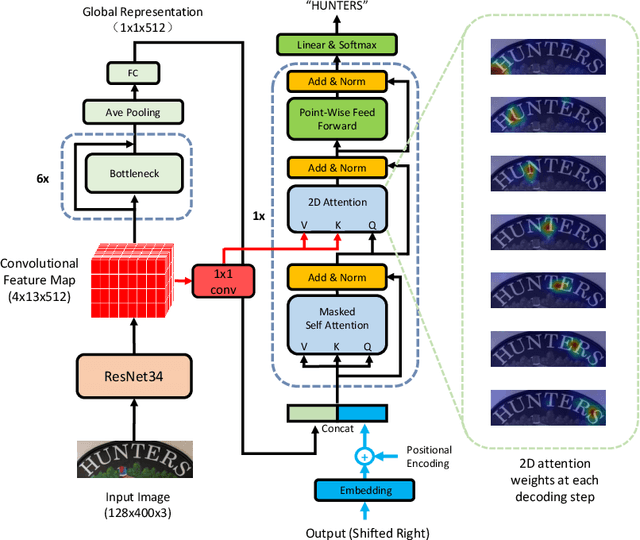
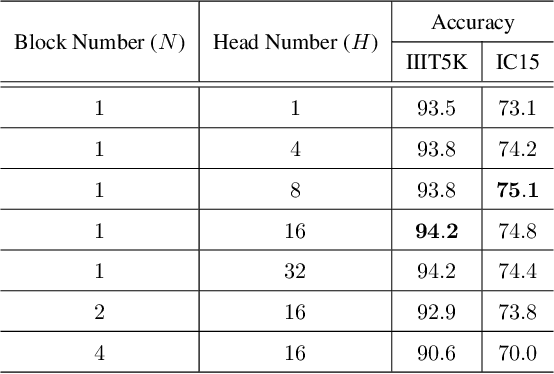
Reading irregular text of arbitrary shape in natural scene images is still a challenging problem. Many existing approaches incorporate sophisticated network structures to handle various shapes, use extra annotations for stronger supervision, or employ hard-to-train recurrent neural networks for sequence modeling. In this work, we propose a simple yet robust approach for irregular text recognition. With no need to convert input images to sequence representations, we directly connect two-dimensional CNN features to an attention-based sequence decoder. As no recurrent module is adopted, our model can be trained in parallel. It achieves 3x to 18x acceleration to backward pass and 2x to 12x acceleration to forward pass, compared with the RNN counterparts. The proposed model is trained with only word-level annotations. With this simple design, our method achieves state-of-the-art or competitive recognition performance on the evaluated regular and irregular scene text benchmark datasets. Furthermore, we show that the recognition performance does not significantly degrade with inaccurate bounding boxes. This is desirable for tasks of end-to-end text detection and recognition: robust recognition performance can still be achieved with an inaccurate text detector. We will release the code.