 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Explanations in Machine Learning Models: A Perturbation Approach
Paper and Code



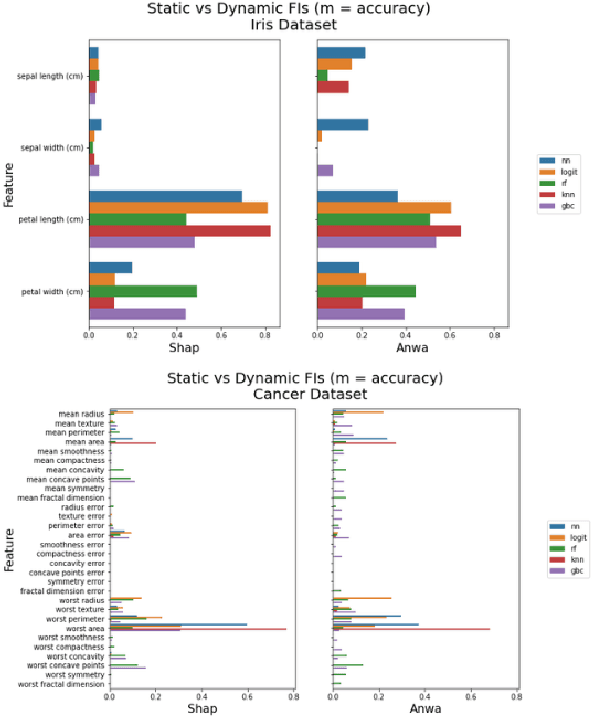
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.