 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKNVQA: A Benchmark for evaluation knowledge-based VQA
Nov 21, 2023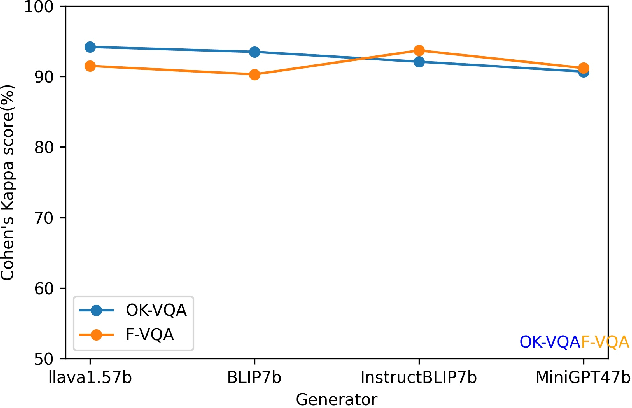

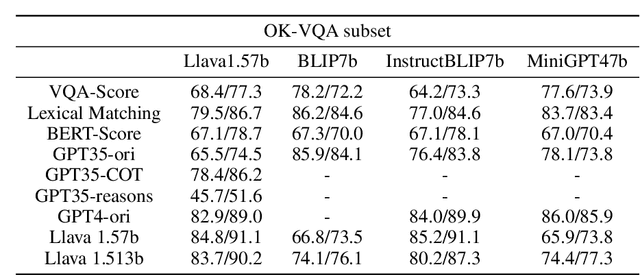
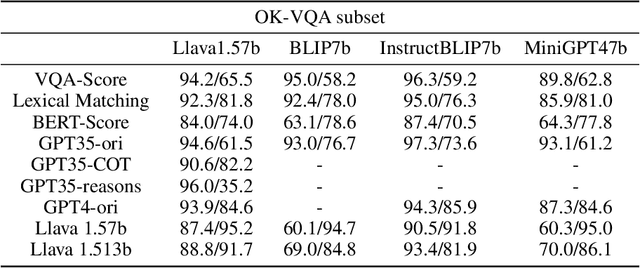
Within the multimodal field, large vision-language models (LVLMs) have made significant progress due to their strong perception and reasoning capabilities in the visual and language systems. However, LVLMs are still plagued by the two critical issues of object hallucination and factual accuracy, which limit the practicality of LVLMs in different scenarios. Furthermore, previous evaluation methods focus more on the comprehension and reasoning of language content but lack a comprehensive evaluation of multimodal interactions, thereby resulting in potential limitations. To this end, we propose a novel KNVQA-Eval, which is devoted to knowledge-based VQA task evaluation to reflect the factuality of multimodal LVLMs. To ensure the robustness and scalability of the evaluation, we develop a new KNVQA dataset by incorporating human judgment and perception, aiming to evaluate the accuracy of standard answers relative to AI-generated answers in knowledge-based VQA. This work not only comprehensively evaluates the contextual information of LVLMs using reliable human annotations, but also further analyzes the fine-grained capabilities of current methods to reveal potential avenues for subsequent optimization of LVLMs-based estimators. Our proposed VQA-Eval and corresponding dataset KNVQA will facilitate the development of automatic evaluation tools with the advantages of low cost, privacy protection, and reproducibility. Our code will be released upon publication.
Multiscale Superpixel Structured Difference Graph Convolutional Network for VL Representation
Oct 25, 2023



Within the multimodal field, the key to integrating vision and language lies in establishing a good alignment strategy. Recently, benefiting from the success of self-supervised learning, significant progress has been made in multimodal semantic representation based on pre-trained models for vision and language. However, there is still room for improvement in visual semantic representation. The lack of spatial semantic coherence and vulnerability to noise makes it challenging for current pixel or patch-based methods to accurately extract complex scene boundaries. To this end, this paper develops superpixel as a comprehensive compact representation of learnable image data, which effectively reduces the number of visual primitives for subsequent processing by clustering perceptually similar pixels. To mine more precise topological relations, we propose a Multiscale Difference Graph Convolutional Network (MDGCN). It parses the entire image as a fine-to-coarse hierarchical structure of constituent visual patterns, and captures multiscale features by progressively merging adjacent superpixels as graph nodes. Moreover, we predict the differences between adjacent nodes through the graph structure, facilitating key information aggregation of graph nodes to reason actual semantic relations. Afterward, we design a multi-level fusion rule in a bottom-up manner to avoid understanding deviation by learning complementary spatial information at different regional scales. Our proposed method can be well applied to multiple downstream task learning. Extensive experiments demonstrate that our method is competitive with other state-of-the-art methods in visual reasoning. Our code will be released upon publication.
Evaluating Open Question Answering Evaluation
May 21, 2023This study focuses on the evaluation of Open Question Answering (Open-QA) tasks, which have become vital in the realm of artificial intelligence. Current automatic evaluation methods have shown limitations, indicating that human evaluation still remains the most reliable approach. We introduce a new task, QA Evaluation (QA-Eval), designed to assess the accuracy of AI-generated answers in relation to standard answers within Open-QA. Our evaluation of these methods utilizes human-annotated results, and we employ accuracy and F1 score to measure their performance. Specifically, the work investigates methods that show high correlation with human evaluations, deeming them more reliable. We also discuss the pitfalls of current methods, such as their inability to accurately judge responses that contain excessive information. The dataset generated from this work is expected to facilitate the development of more effective automatic evaluation tools. We believe this new QA-Eval task and corresponding dataset will prove valuable for future research in this area.