 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEMC: Embedding Enhanced Multi-tag Classification
Paper and Code
Sep 29, 2020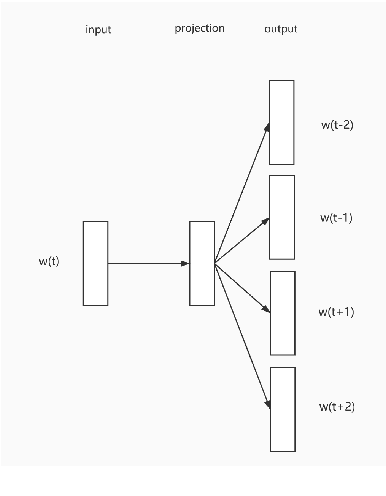
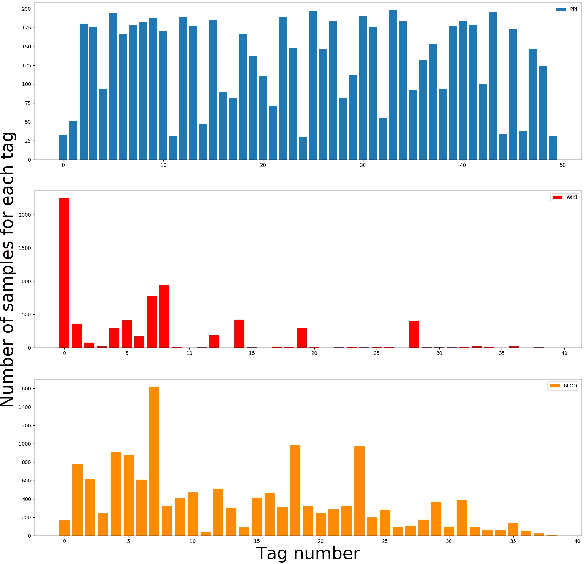
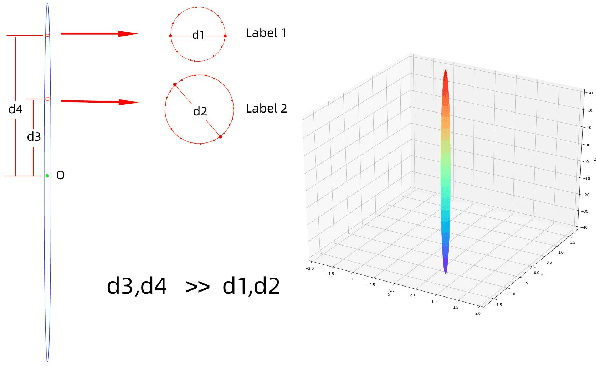
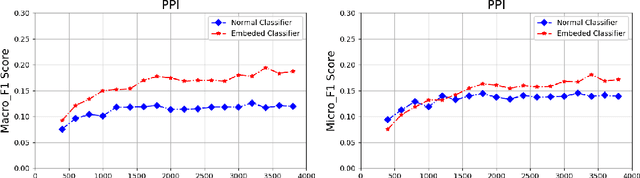
The recently occurred representation learning make an attractive performance in NLP and complex network, it is becoming a fundamental technology in machine learning and data mining. How to use representation learning to improve the performance of classifiers is a very significance research direction. We using representation learning technology to map raw data(node of graph) to a low-dimensional feature space. In this space, each raw data obtained a lower dimensional vector representation, we do some simple linear operations for those vectors to produce some virtual data, using those vectors and virtual data to training multi-tag classifier. After that we measured the performance of classifier by F1 score(Macro% F1 and Micro% F1). Our method make Macro F1 rise from 28 % - 450% and make average F1 score rise from 12 % - 224%. By contrast, we trained the classifier directly with the lower dimensional vector, and measured the performance of classifiers. We validate our algorithm on three public data sets, we found that the virtual data helped the classifier greatly improve the F1 score. Therefore, our algorithm is a effective way to improve the performance of classifier. These result suggest that the virtual data generated by simple linear operation, in representation space, still retains the information of the raw data. It's also have great significance to the learning of small sample data sets.