 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reasoning to Generalization: Knowledge-Augmented LLMs for ARC Benchmark
May 23, 2025Recent reasoning-oriented LLMs have demonstrated strong performance on challenging tasks such as mathematics and science examinations. However, core cognitive faculties of human intelligence, such as abstract reasoning and generalization, remain underexplored. To address this, we evaluate recent reasoning-oriented LLMs on the Abstraction and Reasoning Corpus (ARC) benchmark, which explicitly demands both faculties. We formulate ARC as a program synthesis task and propose nine candidate solvers. Experimental results show that repeated-sampling planning-aided code generation (RSPC) achieves the highest test accuracy and demonstrates consistent generalization across most LLMs. To further improve performance, we introduce an ARC solver, Knowledge Augmentation for Abstract Reasoning (KAAR), which encodes core knowledge priors within an ontology that classifies priors into three hierarchical levels based on their dependencies. KAAR progressively expands LLM reasoning capacity by gradually augmenting priors at each level, and invokes RSPC to generate candidate solutions after each augmentation stage. This stage-wise reasoning reduces interference from irrelevant priors and improves LLM performance. Empirical results show that KAAR maintains strong generalization and consistently outperforms non-augmented RSPC across all evaluated LLMs, achieving around 5% absolute gains and up to 64.52% relative improvement. Despite these achievements, ARC remains a challenging benchmark for reasoning-oriented LLMs, highlighting future avenues of progress in LLMs.
Urban Region Representation Learning: A Flexible Approach
Mar 12, 2025



The increasing availability of urban data offers new opportunities for learning region representations, which can be used as input to machine learning models for downstream tasks such as check-in or crime prediction. While existing solutions have produced promising results, an issue is their fixed formation of regions and fixed input region features, which may not suit the needs of different downstream tasks. To address this limitation, we propose a model named FlexiReg for urban region representation learning that is flexible with both the formation of urban regions and the input region features. FlexiReg is based on a spatial grid partitioning over the spatial area of interest. It learns representations for the grid cells, leveraging publicly accessible data, including POI, land use, satellite imagery, and street view imagery. We propose adaptive aggregation to fuse the cell representations and prompt learning techniques to tailor the representations towards different tasks, addressing the needs of varying formations of urban regions and downstream tasks. Extensive experiments on five real-world datasets demonstrate that FlexiReg outperforms state-of-the-art models by up to 202% in term of the accuracy of four diverse downstream tasks using the produced urban region representations.
DualCast: Disentangling Aperiodic Events from Traffic Series with a Dual-Branch Model
Nov 27, 2024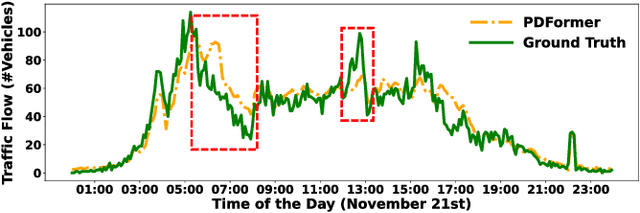
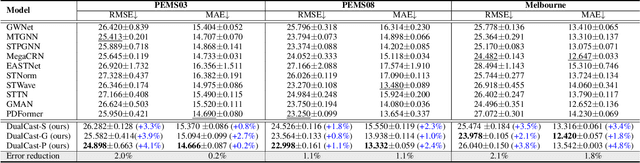
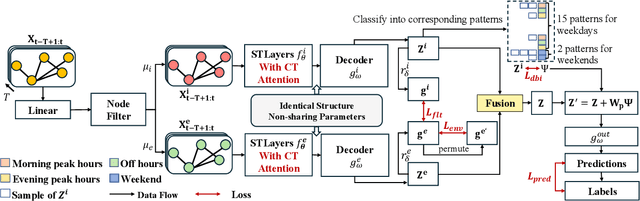
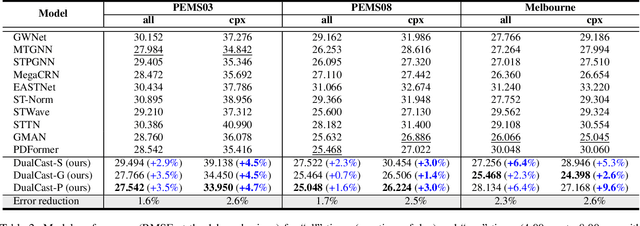
Traffic forecasting is an important problem in the operation and optimisation of transportation systems. State-of-the-art solutions train machine learning models by minimising the mean forecasting errors on the training data. The trained models often favour periodic events instead of aperiodic ones in their prediction results, as periodic events often prevail in the training data. While offering critical optimisation opportunities, aperiodic events such as traffic incidents may be missed by the existing models. To address this issue, we propose DualCast -- a model framework to enhance the learning capability of traffic forecasting models, especially for aperiodic events. DualCast takes a dual-branch architecture, to disentangle traffic signals into two types, one reflecting intrinsic {spatial-temporal} patterns and the other reflecting external environment contexts including aperiodic events. We further propose a cross-time attention mechanism, to capture high-order spatial-temporal relationships from both periodic and aperiodic patterns. DualCast is versatile. We integrate it with recent traffic forecasting models, consistently reducing their forecasting errors by up to 9.6% on multiple real datasets.
Planning-Driven Programming: A Large Language Model Programming Workflow
Nov 21, 2024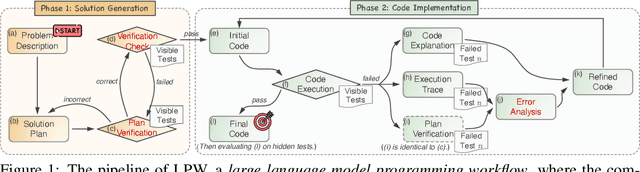
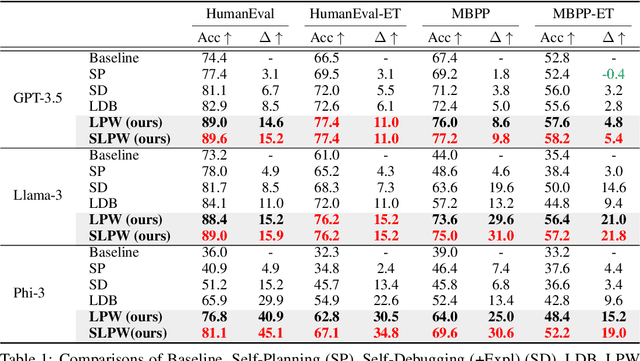


The strong performance of large language models (LLMs) on natural language processing tasks raises extensive discussion on their application to code generation. Recent work suggests multiple sampling approaches to improve initial code generation accuracy or program repair approaches to refine the code. However, these methods suffer from LLMs' inefficiencies and limited reasoning capacity. In this work, we propose an LLM programming workflow (LPW) designed to improve both initial code generation and subsequent refinements within a structured two-phase workflow. Specifically, in the solution generation phase, the LLM first outlines a solution plan that decomposes the problem into manageable sub-problems and then verifies the generated solution plan through visible test cases. Subsequently, in the code implementation phase, the LLM initially drafts a code according to the solution plan and its verification. If the generated code fails the visible tests, the plan verification serves as the intended natural language solution to inform the refinement process for correcting bugs. We further introduce SLPW, a sampling variant of LPW, which initially generates multiple solution plans and plan verifications, produces a program for each plan and its verification, and refines each program as necessary until one successfully passes the visible tests. Compared to the state-of-the-art methods across various existing LLMs, our experimental results show that LPW significantly improves the Pass@1 accuracy by up to 16.4% on well-established text-to-code generation benchmarks, especially with a notable improvement of around 10% on challenging benchmarks. Additionally, SLPW demonstrates up to a 5.6% improvement over LPW and sets new state-of-the-art Pass@1 accuracy on various benchmarks, e.g., 98.2% on HumanEval, 84.8% on MBPP, 64.0% on APPS, and 35.3% on CodeContest, using GPT-4o as the backbone.
Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond
Mar 21, 2024



Trajectory computing is a pivotal domain encompassing trajectory data management and mining, garnering widespread attention due to its crucial role in various practical applications such as location services, urban traffic, and public safety. Traditional methods, focusing on simplistic spatio-temporal features, face challenges of complex calculations, limited scalability, and inadequate adaptability to real-world complexities. In this paper, we present a comprehensive review of the development and recent advances in deep learning for trajectory computing (DL4Traj). We first define trajectory data and provide a brief overview of widely-used deep learning models. Systematically, we explore deep learning applications in trajectory management (pre-processing, storage, analysis, and visualization) and mining (trajectory-related forecasting, trajectory-related recommendation, trajectory classification, travel time estimation, anomaly detection, and mobility generation). Notably, we encapsulate recent advancements in Large Language Models (LLMs) that hold the potential to augment trajectory computing. Additionally, we summarize application scenarios, public datasets, and toolkits. Finally, we outline current challenges in DL4Traj research and propose future directions. Relevant papers and open-source resources have been collated and are continuously updated at: \href{https://github.com/yoshall/Awesome-Trajectory-Computing}{DL4Traj Repo}.
Spatial-temporal Forecasting for Regions without Observations
Jan 19, 2024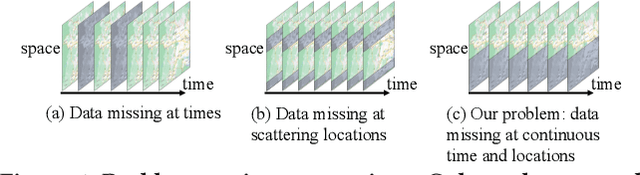
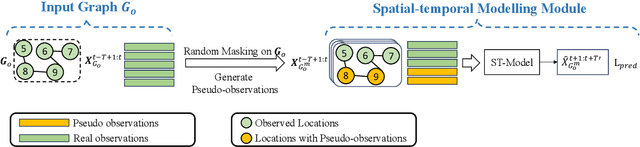
Spatial-temporal forecasting plays an important role in many real-world applications, such as traffic forecasting, air pollutant forecasting, crowd-flow forecasting, and so on. State-of-the-art spatial-temporal forecasting models take data-driven approaches and rely heavily on data availability. Such models suffer from accuracy issues when data is incomplete, which is common in reality due to the heavy costs of deploying and maintaining sensors for data collection. A few recent studies attempted to address the issue of incomplete data. They typically assume some data availability in a region of interest either for a short period or at a few locations. In this paper, we further study spatial-temporal forecasting for a region of interest without any historical observations, to address scenarios such as unbalanced region development, progressive deployment of sensors or lack of open data. We propose a model named STSM for the task. The model takes a contrastive learning-based approach to learn spatial-temporal patterns from adjacent regions that have recorded data. Our key insight is to learn from the locations that resemble those in the region of interest, and we propose a selective masking strategy to enable the learning. As a result, our model outperforms adapted state-of-the-art models, reducing errors consistently over both traffic and air pollutant forecasting tasks. The source code is available at https://github.com/suzy0223/STSM.
Urban Region Representation Learning with Attentive Fusion
Dec 07, 2023



An increasing number of related urban data sources have brought forth novel opportunities for learning urban region representations, i.e., embeddings. The embeddings describe latent features of urban regions and enable discovering similar regions for urban planning applications. Existing methods learn an embedding for a region using every different type of region feature data, and subsequently fuse all learned embeddings of a region to generate a unified region embedding. However, these studies often overlook the significance of the fusion process. The typical fusion methods rely on simple aggregation, such as summation and concatenation, thereby disregarding correlations within the fused region embeddings. To address this limitation, we propose a novel model named HAFusion. Our model is powered by a dual-feature attentive fusion module named DAFusion, which fuses embeddings from different region features to learn higher-order correlations between the regions as well as between the different types of region features. DAFusion is generic - it can be integrated into existing models to enhance their fusion process. Further, motivated by the effective fusion capability of an attentive module, we propose a hybrid attentive feature learning module named HALearning to enhance the embedding learning from each individual type of region features. Extensive experiments on three real-world datasets demonstrate that our model HAFusion outperforms state-of-the-art methods across three different prediction tasks. Using our learned region embedding leads to consistent and up to 31% improvements in the prediction accuracy.
Contrastive Trajectory Similarity Learning with Dual-Feature Attention
Oct 11, 2022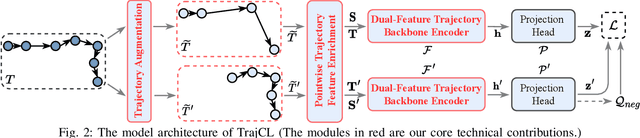
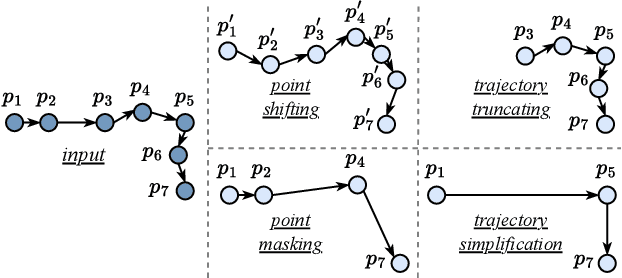

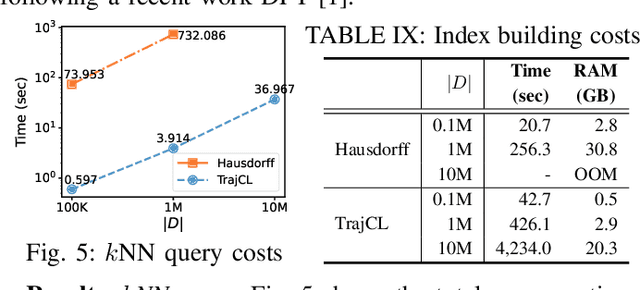
Trajectory similarity measures act as query predicates in trajectory databases, making them the key player in determining the query results. They also have a heavy impact on the query efficiency. An ideal measure should have the capability to accurately evaluate the similarity between any two trajectories in a very short amount of time. However, existing heuristic measures are mainly based on pointwise comparisons following hand-crafted rules, thus resulting in either poor quality results or low efficiency in many cases. Although several deep learning-based measures have recently aimed at these problems, their improvements are limited by the difficulties to learn the fine-grained spatial patterns of trajectories. To address these issues, we propose a contrastive learning-based trajectory modelling method named TrajCL, which is robust in application scenarios where the data set contains low-quality trajectories. Specifically, we present four trajectory augmentation methods and a novel dual-feature self-attention-based trajectory backbone encoder. The resultant model can jointly learn both the spatial and the structural patterns of trajectories. Our model does not involve any recurrent structures and thus has a high efficiency. Besides, our pre-trained backbone encoder can be fine-tuned towards other computationally expensive measures with minimal supervision data. Experimental results show that TrajCL is consistently and significantly more accurate and faster than the state-of-the-art trajectory similarity measures. After fine-tuning, i.e., when being used as an estimator for heuristic measures, TrajCL can even outperform the state-of-the-art supervised method by up to 32% in the accuracy for processing trajectory similarity queries.