 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanVerse: Learning Urban Region Representation Across Cities and Tasks
Feb 17, 2026Recent advances in urban region representation learning have enabled a wide range of applications in urban analytics, yet existing methods remain limited in their capabilities to generalize across cities and analytic tasks. We aim to generalize urban representation learning beyond city- and task-specific settings, towards a foundation-style model for urban analytics. To this end, we propose UrbanVerse, a model for cross-city urban representation learning and cross-task urban analytics. For cross-city generalization, UrbanVerse focuses on features local to the target regions and structural features of the nearby regions rather than the entire city. We model regions as nodes on a graph, which enables a random walk-based procedure to form "sequences of regions" that reflect both local and neighborhood structural features for urban region representation learning. For cross-task generalization, we propose a cross-task learning module named HCondDiffCT. This module integrates region-conditioned prior knowledge and task-conditioned semantics into the diffusion process to jointly model multiple downstream urban prediction tasks. HCondDiffCT is generic. It can also be integrated with existing urban representation learning models to enhance their downstream task effectiveness. Experiments on real-world datasets show that UrbanVerse consistently outperforms state-of-the-art methods across six tasks under cross-city settings, achieving up to 35.89% improvements in prediction accuracy.
SEAFormer: A Spatial Proximity and Edge-Aware Transformer for Real-World Vehicle Routing Problems
Jan 27, 2026Real-world Vehicle Routing Problems (RWVRPs) require solving complex, sequence-dependent challenges at scale with constraints such as delivery time window, replenishment or recharging stops, asymmetric travel cost, etc. While recent neural methods achieve strong results on large-scale classical VRP benchmarks, they struggle to address RWVRPs because their strategies overlook sequence dependencies and underutilize edge-level information, which are precisely the characteristics that define the complexity of RWVRPs. We present SEAFormer, a novel transformer that incorporates both node-level and edge-level information in decision-making through two key innovations. First, our Clustered Proximity Attention (CPA) exploits locality-aware clustering to reduce the complexity of attention from $O(n^2)$ to $O(n)$ while preserving global perspective, allowing SEAFormer to efficiently train on large instances. Second, our lightweight edge-aware module captures pairwise features through residual fusion, enabling effective incorporation of edge-based information and faster convergence. Extensive experiments across four RWVRP variants with various scales demonstrate that SEAFormer achieves superior results over state-of-the-art methods. Notably, SEAFormer is the first neural method to solve 1,000+ node RWVRPs effectively, while also achieving superior performance on classic VRPs, making it a versatile solution for both research benchmarks and real-world applications.
Generalising Traffic Forecasting to Regions without Traffic Observations
Aug 12, 2025Traffic forecasting is essential for intelligent transportation systems. Accurate forecasting relies on continuous observations collected by traffic sensors. However, due to high deployment and maintenance costs, not all regions are equipped with such sensors. This paper aims to forecast for regions without traffic sensors, where the lack of historical traffic observations challenges the generalisability of existing models. We propose a model named GenCast, the core idea of which is to exploit external knowledge to compensate for the missing observations and to enhance generalisation. We integrate physics-informed neural networks into GenCast, enabling physical principles to regularise the learning process. We introduce an external signal learning module to explore correlations between traffic states and external signals such as weather conditions, further improving model generalisability. Additionally, we design a spatial grouping module to filter localised features that hinder model generalisability. Extensive experiments show that GenCast consistently reduces forecasting errors on multiple real-world datasets.
Urban Region Representation Learning: A Flexible Approach
Mar 12, 2025



The increasing availability of urban data offers new opportunities for learning region representations, which can be used as input to machine learning models for downstream tasks such as check-in or crime prediction. While existing solutions have produced promising results, an issue is their fixed formation of regions and fixed input region features, which may not suit the needs of different downstream tasks. To address this limitation, we propose a model named FlexiReg for urban region representation learning that is flexible with both the formation of urban regions and the input region features. FlexiReg is based on a spatial grid partitioning over the spatial area of interest. It learns representations for the grid cells, leveraging publicly accessible data, including POI, land use, satellite imagery, and street view imagery. We propose adaptive aggregation to fuse the cell representations and prompt learning techniques to tailor the representations towards different tasks, addressing the needs of varying formations of urban regions and downstream tasks. Extensive experiments on five real-world datasets demonstrate that FlexiReg outperforms state-of-the-art models by up to 202% in term of the accuracy of four diverse downstream tasks using the produced urban region representations.
DualCast: Disentangling Aperiodic Events from Traffic Series with a Dual-Branch Model
Nov 27, 2024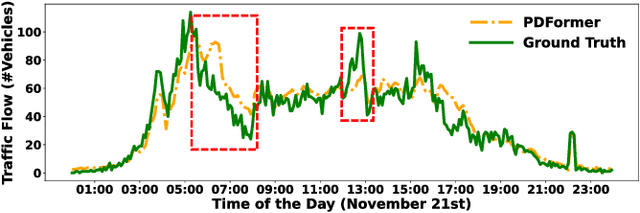
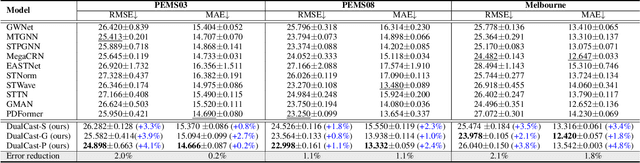
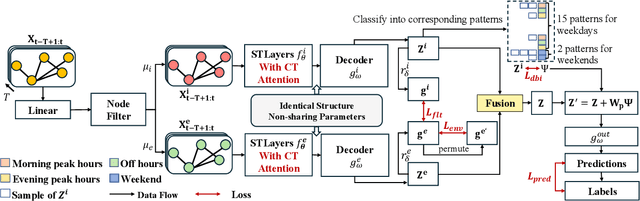
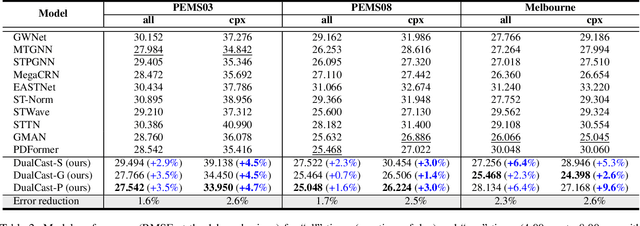
Traffic forecasting is an important problem in the operation and optimisation of transportation systems. State-of-the-art solutions train machine learning models by minimising the mean forecasting errors on the training data. The trained models often favour periodic events instead of aperiodic ones in their prediction results, as periodic events often prevail in the training data. While offering critical optimisation opportunities, aperiodic events such as traffic incidents may be missed by the existing models. To address this issue, we propose DualCast -- a model framework to enhance the learning capability of traffic forecasting models, especially for aperiodic events. DualCast takes a dual-branch architecture, to disentangle traffic signals into two types, one reflecting intrinsic {spatial-temporal} patterns and the other reflecting external environment contexts including aperiodic events. We further propose a cross-time attention mechanism, to capture high-order spatial-temporal relationships from both periodic and aperiodic patterns. DualCast is versatile. We integrate it with recent traffic forecasting models, consistently reducing their forecasting errors by up to 9.6% on multiple real datasets.
DeepMDV: Learning Global Matching for Multi-depot Vehicle Routing Problems
Nov 26, 2024



Due to the substantial rise in online retail and e-commerce in recent years, the demand for efficient and fast solutions to Vehicle Routing Problems (VRP) has become critical. To manage the increasing demand, companies have adopted the strategy of adding more depots. However, the presence of multiple depots introduces additional complexities, making existing VRP solutions suboptimal for addressing the Multi-depot Vehicle Routing Problem (MDVRP). Traditional methods for solving the MDVRP often require significant computation time, making them unsuitable for large-scale instances. Additionally, existing learning-based solutions for the MDVRP struggle with generalizability and fail to deliver high-quality results for scenarios involving a large number of customers. In this paper, we propose a novel solution for MDVRP. Our approach employs an attention mechanism, featuring a decoder with two key layers: one layer to consider the states of all vehicles and learn to select the most suitable vehicle based on the proximity of unassigned customers, and another layer to focus on assigning a customer to the selected vehicle. This approach delivers high-quality solutions for large-scale MDVRP instances and demonstrates remarkable generalizability across varying numbers of customers and depots. Its adaptability and performance make it a practical and deployable solution for real-world logistics challenges.
Spatial-temporal Forecasting for Regions without Observations
Jan 19, 2024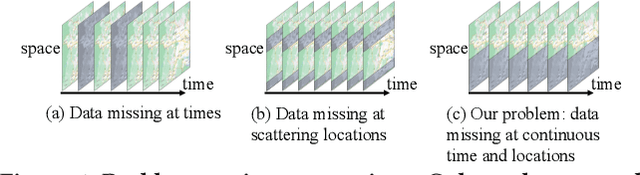
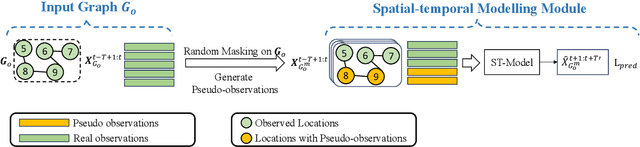
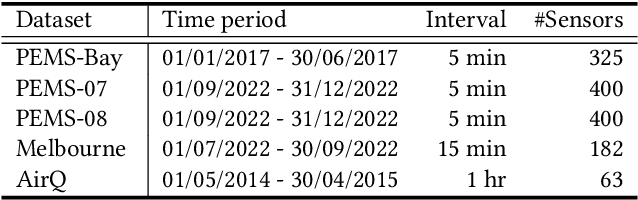
Spatial-temporal forecasting plays an important role in many real-world applications, such as traffic forecasting, air pollutant forecasting, crowd-flow forecasting, and so on. State-of-the-art spatial-temporal forecasting models take data-driven approaches and rely heavily on data availability. Such models suffer from accuracy issues when data is incomplete, which is common in reality due to the heavy costs of deploying and maintaining sensors for data collection. A few recent studies attempted to address the issue of incomplete data. They typically assume some data availability in a region of interest either for a short period or at a few locations. In this paper, we further study spatial-temporal forecasting for a region of interest without any historical observations, to address scenarios such as unbalanced region development, progressive deployment of sensors or lack of open data. We propose a model named STSM for the task. The model takes a contrastive learning-based approach to learn spatial-temporal patterns from adjacent regions that have recorded data. Our key insight is to learn from the locations that resemble those in the region of interest, and we propose a selective masking strategy to enable the learning. As a result, our model outperforms adapted state-of-the-art models, reducing errors consistently over both traffic and air pollutant forecasting tasks. The source code is available at https://github.com/suzy0223/STSM.
Urban Region Representation Learning with Attentive Fusion
Dec 07, 2023



An increasing number of related urban data sources have brought forth novel opportunities for learning urban region representations, i.e., embeddings. The embeddings describe latent features of urban regions and enable discovering similar regions for urban planning applications. Existing methods learn an embedding for a region using every different type of region feature data, and subsequently fuse all learned embeddings of a region to generate a unified region embedding. However, these studies often overlook the significance of the fusion process. The typical fusion methods rely on simple aggregation, such as summation and concatenation, thereby disregarding correlations within the fused region embeddings. To address this limitation, we propose a novel model named HAFusion. Our model is powered by a dual-feature attentive fusion module named DAFusion, which fuses embeddings from different region features to learn higher-order correlations between the regions as well as between the different types of region features. DAFusion is generic - it can be integrated into existing models to enhance their fusion process. Further, motivated by the effective fusion capability of an attentive module, we propose a hybrid attentive feature learning module named HALearning to enhance the embedding learning from each individual type of region features. Extensive experiments on three real-world datasets demonstrate that our model HAFusion outperforms state-of-the-art methods across three different prediction tasks. Using our learned region embedding leads to consistent and up to 31% improvements in the prediction accuracy.
Contrastive Trajectory Similarity Learning with Dual-Feature Attention
Oct 11, 2022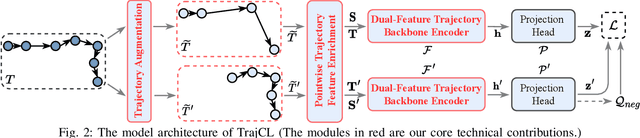
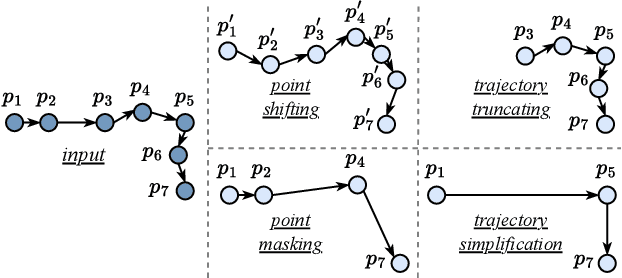

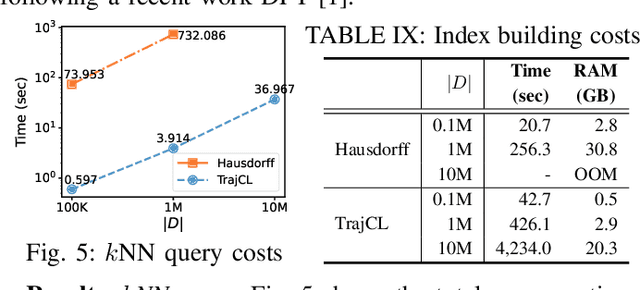
Trajectory similarity measures act as query predicates in trajectory databases, making them the key player in determining the query results. They also have a heavy impact on the query efficiency. An ideal measure should have the capability to accurately evaluate the similarity between any two trajectories in a very short amount of time. However, existing heuristic measures are mainly based on pointwise comparisons following hand-crafted rules, thus resulting in either poor quality results or low efficiency in many cases. Although several deep learning-based measures have recently aimed at these problems, their improvements are limited by the difficulties to learn the fine-grained spatial patterns of trajectories. To address these issues, we propose a contrastive learning-based trajectory modelling method named TrajCL, which is robust in application scenarios where the data set contains low-quality trajectories. Specifically, we present four trajectory augmentation methods and a novel dual-feature self-attention-based trajectory backbone encoder. The resultant model can jointly learn both the spatial and the structural patterns of trajectories. Our model does not involve any recurrent structures and thus has a high efficiency. Besides, our pre-trained backbone encoder can be fine-tuned towards other computationally expensive measures with minimal supervision data. Experimental results show that TrajCL is consistently and significantly more accurate and faster than the state-of-the-art trajectory similarity measures. After fine-tuning, i.e., when being used as an estimator for heuristic measures, TrajCL can even outperform the state-of-the-art supervised method by up to 32% in the accuracy for processing trajectory similarity queries.
A Graph and Attentive Multi-Path Convolutional Network for Traffic Prediction
May 30, 2022
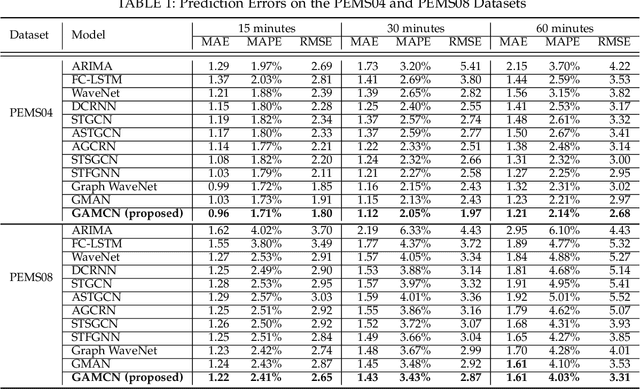
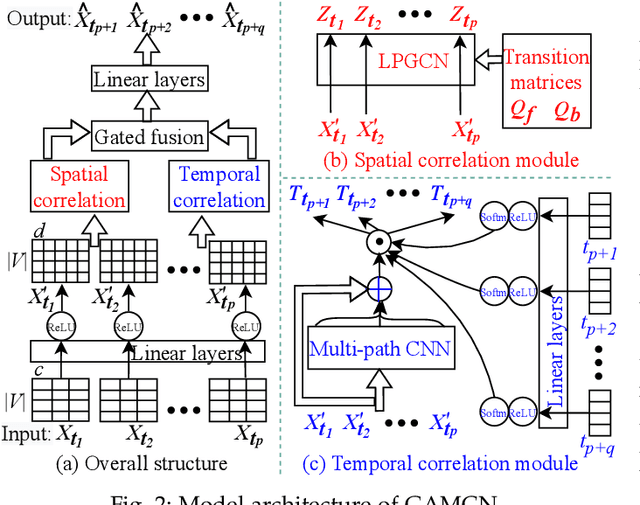
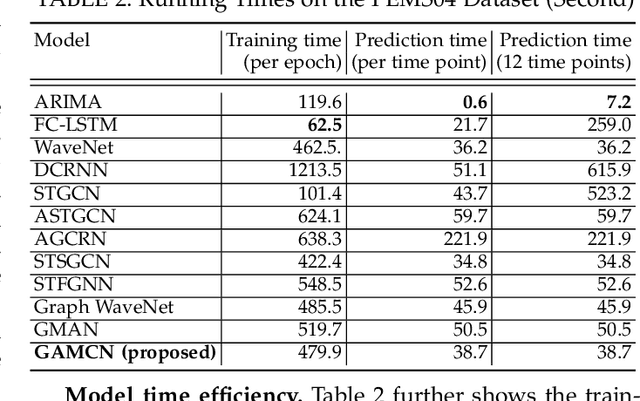
Traffic prediction is an important and yet highly challenging problem due to the complexity and constantly changing nature of traffic systems. To address the challenges, we propose a graph and attentive multi-path convolutional network (GAMCN) model to predict traffic conditions such as traffic speed across a given road network into the future. Our model focuses on the spatial and temporal factors that impact traffic conditions. To model the spatial factors, we propose a variant of the graph convolutional network (GCN) named LPGCN to embed road network graph vertices into a latent space, where vertices with correlated traffic conditions are close to each other. To model the temporal factors, we use a multi-path convolutional neural network (CNN) to learn the joint impact of different combinations of past traffic conditions on the future traffic conditions. Such a joint impact is further modulated by an attention} generated from an embedding of the prediction time, which encodes the periodic patterns of traffic conditions. We evaluate our model on real-world road networks and traffic data. The experimental results show that our model outperforms state-of-art traffic prediction models by up to 18.9% in terms of prediction errors and 23.4% in terms of prediction efficiency.