 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLSE: A Lightweight and Robust Hybrid Learned Model for Single-Table Cardinality Estimation using Joint CDF
Dec 14, 2025Cardinality estimation (CE), the task of predicting the result size of queries is a critical component of query optimization. Accurate estimates are essential for generating efficient query execution plans. Recently, machine learning techniques have been applied to CE, broadly categorized into query-driven and data-driven approaches. Data-driven methods learn the joint distribution of data, while query-driven methods construct regression models that map query features to cardinalities. Ideally, a CE technique should strike a balance among three key factors: accuracy, efficiency, and memory footprint. However, existing state-of-the-art models often fail to achieve this balance. To address this, we propose CoLSE, a hybrid learned approach for single-table cardinality estimation. CoLSE directly models the joint probability over queried intervals using a novel algorithm based on copula theory and integrates a lightweight neural network to correct residual estimation errors. Experimental results show that CoLSE achieves a favorable trade-off among accuracy, training time, inference latency, and model size, outperforming existing state-of-the-art methods.
Testing the Robustness of Learned Index Structures
Jul 23, 2022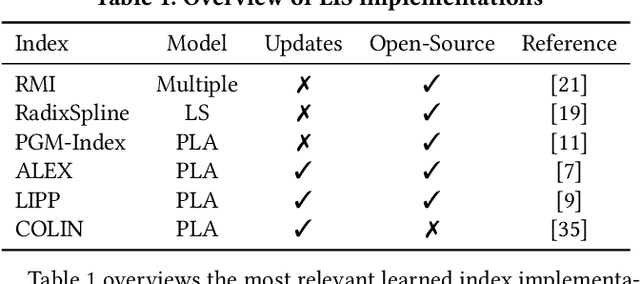


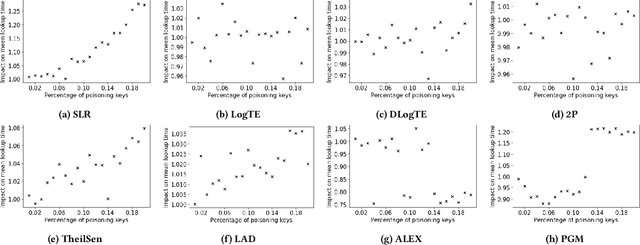
While early empirical evidence has supported the case for learned index structures as having favourable average-case performance, little is known about their worst-case performance. By contrast, classical structures are known to achieve optimal worst-case behaviour. This work evaluates the robustness of learned index structures in the presence of adversarial workloads. To simulate adversarial workloads, we carry out a data poisoning attack on linear regression models that manipulates the cumulative distribution function (CDF) on which the learned index model is trained. The attack deteriorates the fit of the underlying ML model by injecting a set of poisoning keys into the training dataset, which leads to an increase in the prediction error of the model and thus deteriorates the overall performance of the learned index structure. We assess the performance of various regression methods and the learned index implementations ALEX and PGM-Index. We show that learned index structures can suffer from a significant performance deterioration of up to 20% when evaluated on poisoned vs. non-poisoned datasets.
Intelligent Autonomous Intersection Management
Feb 09, 2022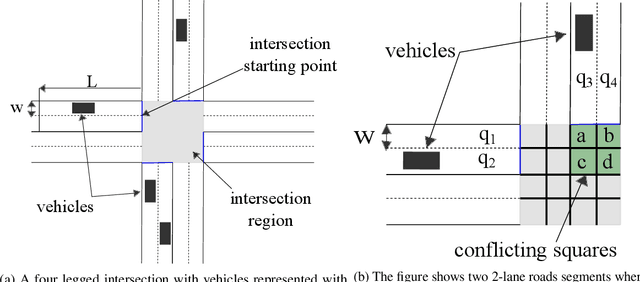
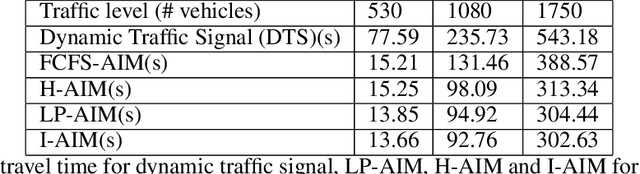
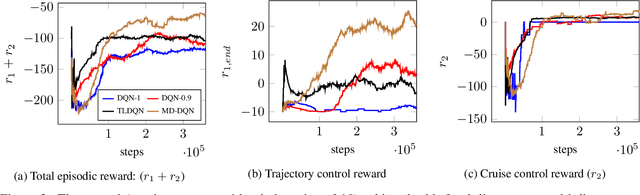
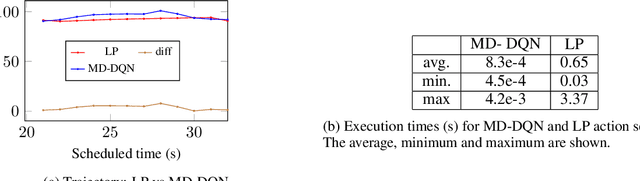
Connected Autonomous Vehicles will make autonomous intersection management a reality replacing traditional traffic signal control. Autonomous intersection management requires time and speed adjustment of vehicles arriving at an intersection for collision-free passing through the intersection. Due to its computational complexity, this problem has been studied only when vehicle arrival times towards the vicinity of the intersection are known beforehand, which limits the applicability of these solutions for real-time deployment. To solve the real-time autonomous traffic intersection management problem, we propose a reinforcement learning (RL) based multiagent architecture and a novel RL algorithm coined multi-discount Q-learning. In multi-discount Q-learning, we introduce a simple yet effective way to solve a Markov Decision Process by preserving both short-term and long-term goals, which is crucial for collision-free speed control. Our empirical results show that our RL-based multiagent solution can achieve near-optimal performance efficiently when minimizing the travel time through an intersection.
Solving Dynamic Graph Problems with Multi-Attention Deep Reinforcement Learning
Jan 13, 2022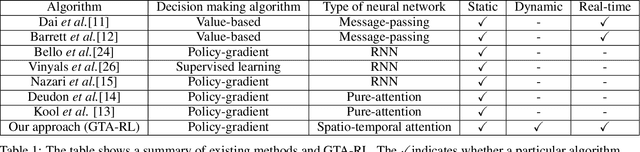
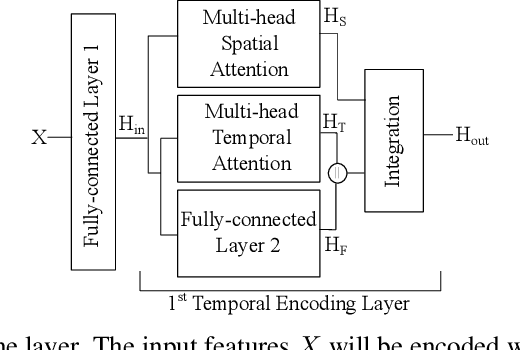
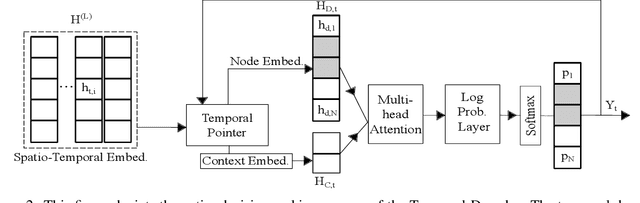
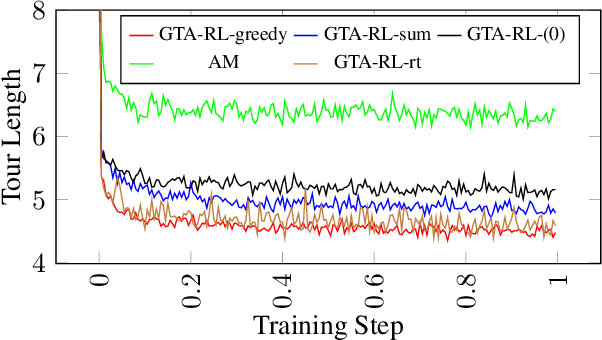
Graph problems such as traveling salesman problem, or finding minimal Steiner trees are widely studied and used in data engineering and computer science. Typically, in real-world applications, the features of the graph tend to change over time, thus, finding a solution to the problem becomes challenging. The dynamic version of many graph problems are the key for a plethora of real-world problems in transportation, telecommunication, and social networks. In recent years, using deep learning techniques to find heuristic solutions for NP-hard graph combinatorial problems has gained much interest as these learned heuristics can find near-optimal solutions efficiently. However, most of the existing methods for learning heuristics focus on static graph problems. The dynamic nature makes NP-hard graph problems much more challenging to learn, and the existing methods fail to find reasonable solutions. In this paper, we propose a novel architecture named Graph Temporal Attention with Reinforcement Learning (GTA-RL) to learn heuristic solutions for graph-based dynamic combinatorial optimization problems. The GTA-RL architecture consists of an encoder capable of embedding temporal features of a combinatorial problem instance and a decoder capable of dynamically focusing on the embedded features to find a solution to a given combinatorial problem instance. We then extend our architecture to learn heuristics for the real-time version of combinatorial optimization problems where all input features of a problem are not known a prior, but rather learned in real-time. Our experimental results against several state-of-the-art learning-based algorithms and optimal solvers demonstrate that our approach outperforms the state-of-the-art learning-based approaches in terms of effectiveness and optimal solvers in terms of efficiency on dynamic and real-time graph combinatorial optimization.
No DBA? No regret! Multi-armed bandits for index tuning of analytical and HTAP workloads with provable guarantees
Aug 23, 2021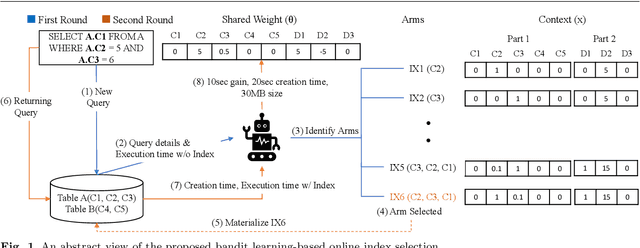
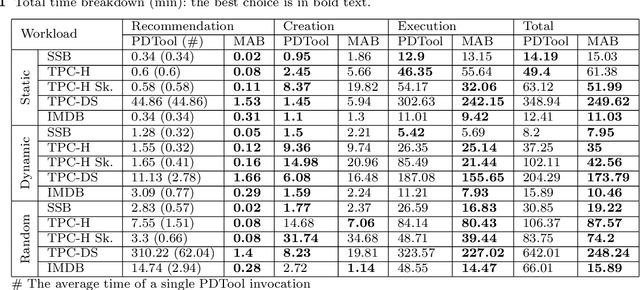
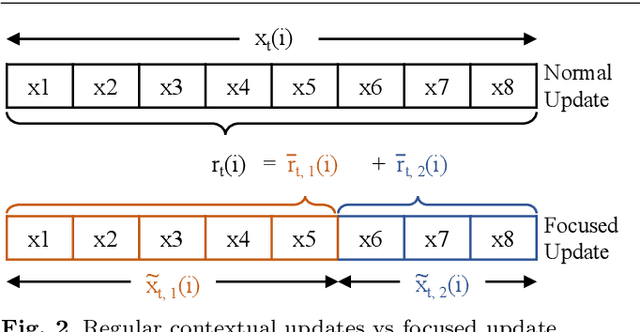
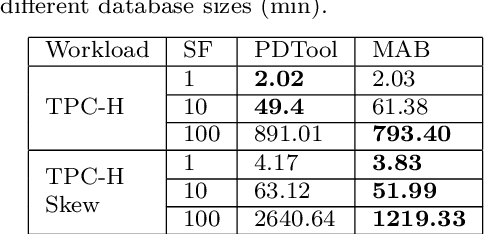
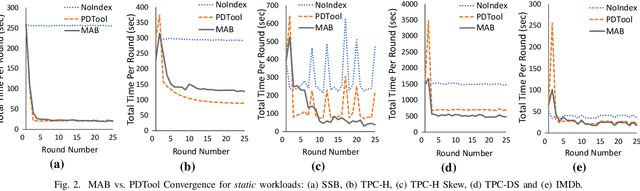
Automating physical database design has remained a long-term interest in database research due to substantial performance gains afforded by optimised structures. Despite significant progress, a majority of today's commercial solutions are highly manual, requiring offline invocation by database administrators (DBAs) who are expected to identify and supply representative training workloads. Even the latest advancements like query stores provide only limited support for dynamic environments. This status quo is untenable: identifying representative static workloads is no longer realistic; and physical design tools remain susceptible to the query optimiser's cost misestimates. Furthermore, modern application environments such as hybrid transactional and analytical processing (HTAP) systems render analytical modelling next to impossible. We propose a self-driving approach to online index selection that eschews the DBA and query optimiser, and instead learns the benefits of viable structures through strategic exploration and direct performance observation. We view the problem as one of sequential decision making under uncertainty, specifically within the bandit learning setting. Multi-armed bandits balance exploration and exploitation to provably guarantee average performance that converges to policies that are optimal with perfect hindsight. Our comprehensive empirical evaluation against a state-of-the-art commercial tuning tool demonstrates up to 75% speed-up on shifting and ad-hoc workloads and up to 28% speed-up on static workloads in analytical processing environments. In HTAP environments, our solution provides up to 59% speed-up on shifting and 51% speed-up on static workloads. Furthermore, our bandit framework outperforms deep reinforcement learning (RL) in terms of convergence speed and performance volatility (providing up to 58% speed-up).
DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees
Oct 20, 2020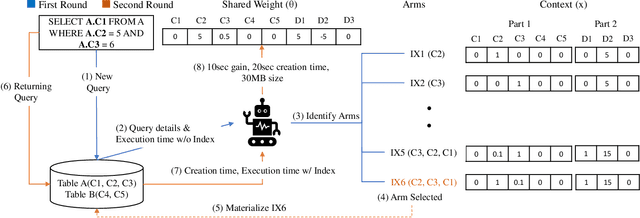
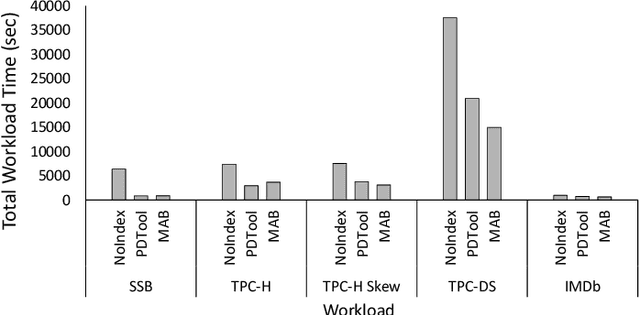
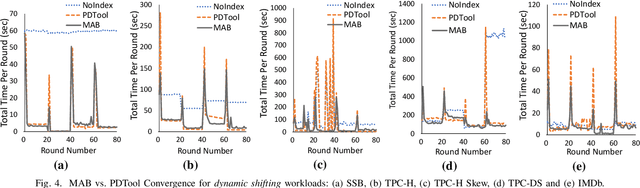
Automating physical database design has remained a long-term interest in database research due to substantial performance gains afforded by optimised structures. Despite significant progress, a majority of today's commercial solutions are highly manual, requiring offline invocation by database administrators (DBAs) who are expected to identify and supply representative training workloads. Unfortunately, the latest advancements like query stores provide only limited support for dynamic environments. This status quo is untenable: identifying representative static workloads is no longer realistic; and physical design tools remain susceptible to the query optimiser's cost misestimates (stemming from unrealistic assumptions such as attribute value independence and uniformity of data distribution). We propose a self-driving approach to online index selection that eschews the DBA and query optimiser, and instead learns the benefits of viable structures through strategic exploration and direct performance observation. We view the problem as one of sequential decision making under uncertainty, specifically within the bandit learning setting. Multi-armed bandits balance exploration and exploitation to provably guarantee average performance that converges to a fixed policy that is optimal with perfect hindsight. Our comprehensive empirical results demonstrate up to 75% speed-up on shifting and ad-hoc workloads and 28% speed-up on static workloads compared against a state-of-the-art commercial tuning tool.
Dynamic Graph Configuration with Reinforcement Learning for Connected Autonomous Vehicle Trajectories
Oct 14, 2019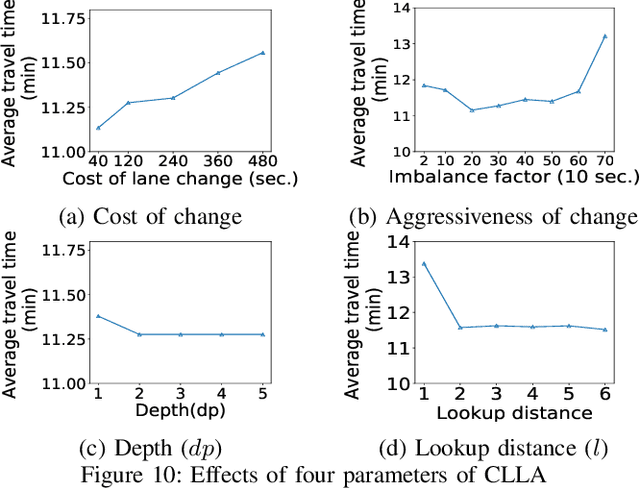
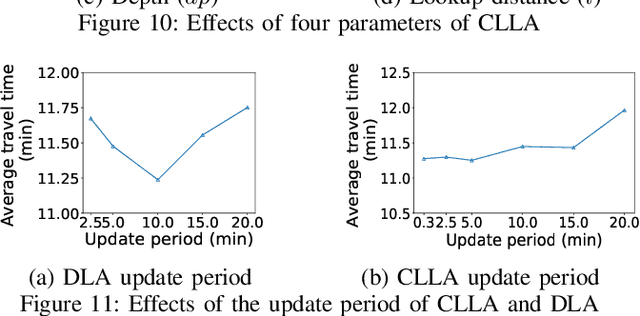
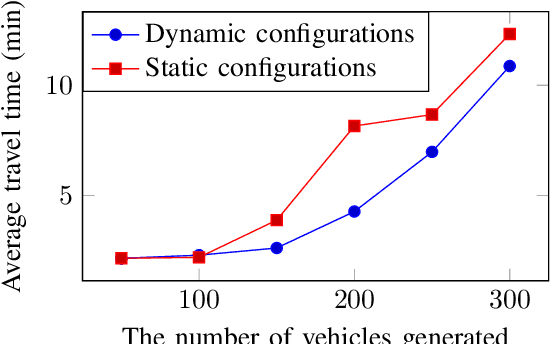

Traditional traffic optimization solutions assume that the graph structure of road networks is static, missing opportunities for further traffic flow optimization. We are interested in optimizing traffic flows as a new type of graph-based problem, where the graph structure of a road network can adapt to traffic conditions in real time. In particular, we focus on the dynamic configuration of traffic-lane directions, which can help balance the usage of traffic lanes in opposite directions. The rise of connected autonomous vehicles offers an opportunity to apply this type of dynamic traffic optimization at a large scale. The existing techniques for optimizing lane-directions are however not suitable for dynamic traffic environments due to their high computational complexity and the static nature. In this paper, we propose an efficient traffic optimization solution, called Coordinated Learning-based Lane Allocation (CLLA), which is suitable for dynamic configuration of lane-directions. CLLA consists of a two-layer multi-agent architecture, where the bottom-layer agents use a machine learning technique to find a suitable configuration of lane-directions around individual road intersections. The lane-direction changes proposed by the learning agents are then coordinated at a higher level to reduce the negative impact of the changes on other parts of the road network. Our experimental results show that CLLA can reduce the average travel time significantly in congested road networks. We believe our method is general enough to be applied to other types of networks as well.
A Note on Bounding Regret of the C$^2$UCB Contextual Combinatorial Bandit
Feb 20, 2019We revisit the proof by Qin et al. (2014) of bounded regret of the C$^2$UCB contextual combinatorial bandit. We demonstrate an error in the proof of volumetric expansion of the moment matrix, used in upper bounding a function of context vector norms. We prove a relaxed inequality that yields the originally-stated regret bound.