 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo DBA? No regret! Multi-armed bandits for index tuning of analytical and HTAP workloads with provable guarantees
Aug 23, 2021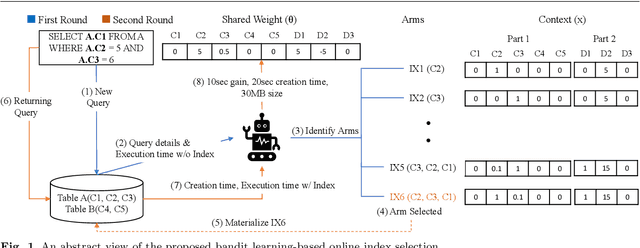
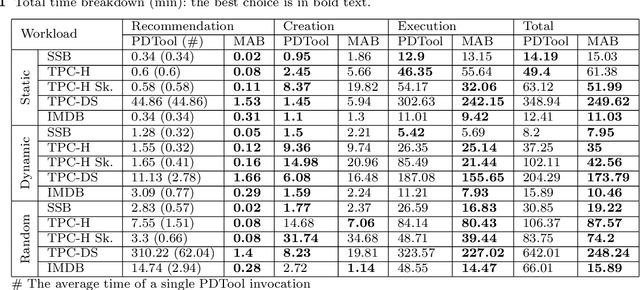
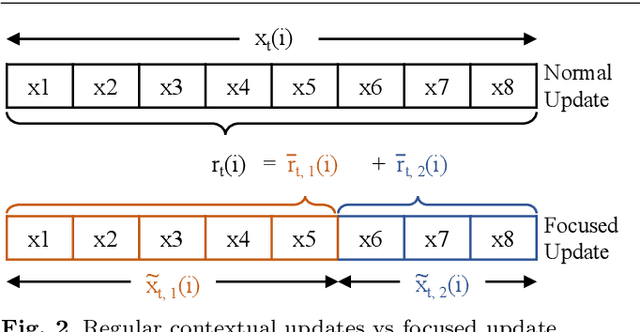
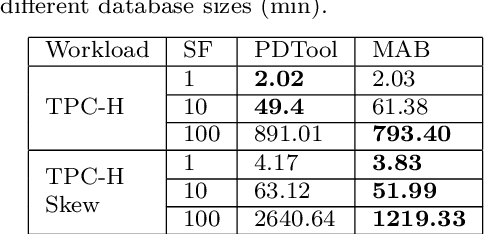
Automating physical database design has remained a long-term interest in database research due to substantial performance gains afforded by optimised structures. Despite significant progress, a majority of today's commercial solutions are highly manual, requiring offline invocation by database administrators (DBAs) who are expected to identify and supply representative training workloads. Even the latest advancements like query stores provide only limited support for dynamic environments. This status quo is untenable: identifying representative static workloads is no longer realistic; and physical design tools remain susceptible to the query optimiser's cost misestimates. Furthermore, modern application environments such as hybrid transactional and analytical processing (HTAP) systems render analytical modelling next to impossible. We propose a self-driving approach to online index selection that eschews the DBA and query optimiser, and instead learns the benefits of viable structures through strategic exploration and direct performance observation. We view the problem as one of sequential decision making under uncertainty, specifically within the bandit learning setting. Multi-armed bandits balance exploration and exploitation to provably guarantee average performance that converges to policies that are optimal with perfect hindsight. Our comprehensive empirical evaluation against a state-of-the-art commercial tuning tool demonstrates up to 75% speed-up on shifting and ad-hoc workloads and up to 28% speed-up on static workloads in analytical processing environments. In HTAP environments, our solution provides up to 59% speed-up on shifting and 51% speed-up on static workloads. Furthermore, our bandit framework outperforms deep reinforcement learning (RL) in terms of convergence speed and performance volatility (providing up to 58% speed-up).
DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees
Oct 20, 2020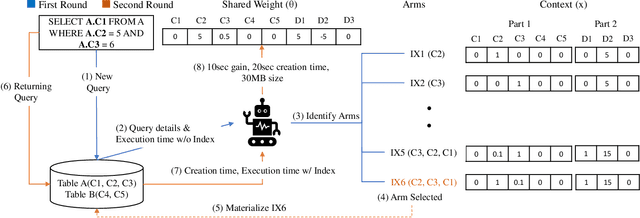
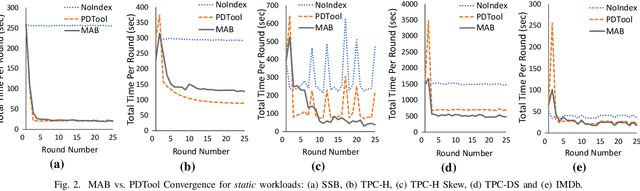
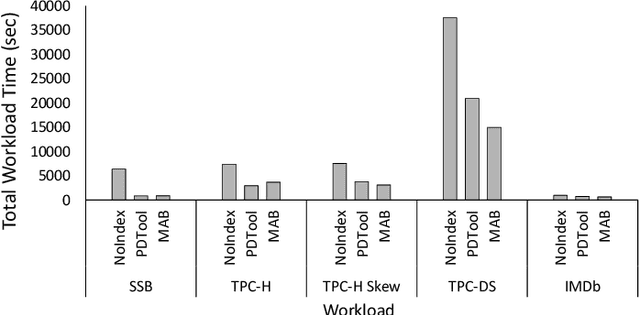
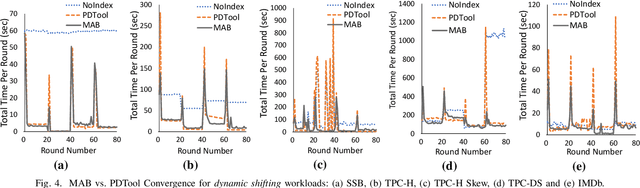
Automating physical database design has remained a long-term interest in database research due to substantial performance gains afforded by optimised structures. Despite significant progress, a majority of today's commercial solutions are highly manual, requiring offline invocation by database administrators (DBAs) who are expected to identify and supply representative training workloads. Unfortunately, the latest advancements like query stores provide only limited support for dynamic environments. This status quo is untenable: identifying representative static workloads is no longer realistic; and physical design tools remain susceptible to the query optimiser's cost misestimates (stemming from unrealistic assumptions such as attribute value independence and uniformity of data distribution). We propose a self-driving approach to online index selection that eschews the DBA and query optimiser, and instead learns the benefits of viable structures through strategic exploration and direct performance observation. We view the problem as one of sequential decision making under uncertainty, specifically within the bandit learning setting. Multi-armed bandits balance exploration and exploitation to provably guarantee average performance that converges to a fixed policy that is optimal with perfect hindsight. Our comprehensive empirical results demonstrate up to 75% speed-up on shifting and ad-hoc workloads and 28% speed-up on static workloads compared against a state-of-the-art commercial tuning tool.