 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINCREASE: Inductive Graph Representation Learning for Spatio-Temporal Kriging
Feb 06, 2023Spatio-temporal kriging is an important problem in web and social applications, such as Web or Internet of Things, where things (e.g., sensors) connected into a web often come with spatial and temporal properties. It aims to infer knowledge for (the things at) unobserved locations using the data from (the things at) observed locations during a given time period of interest. This problem essentially requires \emph{inductive learning}. Once trained, the model should be able to perform kriging for different locations including newly given ones, without retraining. However, it is challenging to perform accurate kriging results because of the heterogeneous spatial relations and diverse temporal patterns. In this paper, we propose a novel inductive graph representation learning model for spatio-temporal kriging. We first encode heterogeneous spatial relations between the unobserved and observed locations by their spatial proximity, functional similarity, and transition probability. Based on each relation, we accurately aggregate the information of most correlated observed locations to produce inductive representations for the unobserved locations, by jointly modeling their similarities and differences. Then, we design relation-aware gated recurrent unit (GRU) networks to adaptively capture the temporal correlations in the generated sequence representations for each relation. Finally, we propose a multi-relation attention mechanism to dynamically fuse the complex spatio-temporal information at different time steps from multiple relations to compute the kriging output. Experimental results on three real-world datasets show that our proposed model outperforms state-of-the-art methods consistently, and the advantage is more significant when there are fewer observed locations. Our code is available at https://github.com/zhengchuanpan/INCREASE.
Multi-Graph Fusion Networks for Urban Region Embedding
Jan 24, 2022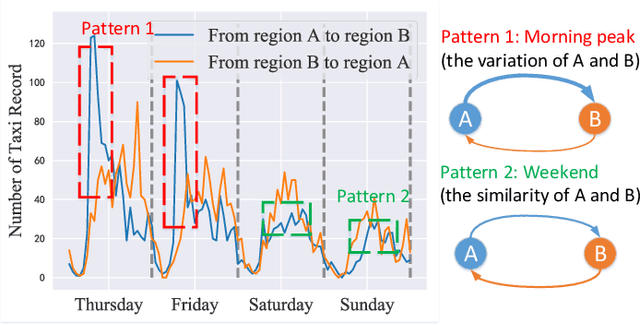
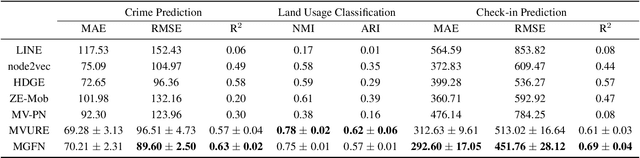
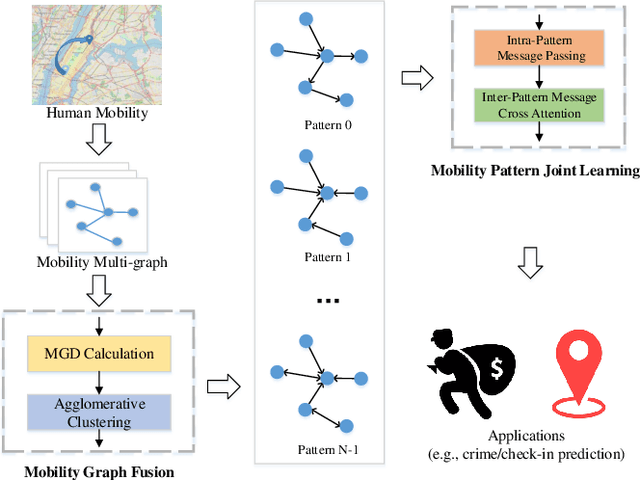

Learning the embeddings for urban regions from human mobility data can reveal the functionality of regions, and then enables the correlated but distinct tasks such as crime prediction. Human mobility data contains rich but abundant information, which yields to the comprehensive region embeddings for cross domain tasks. In this paper, we propose multi-graph fusion networks (MGFN) to enable the cross domain prediction tasks. First, we integrate the graphs with spatio-temporal similarity as mobility patterns through a mobility graph fusion module. Then, in the mobility pattern joint learning module, we design the multi-level cross-attention mechanism to learn the comprehensive embeddings from multiple mobility patterns based on intra-pattern and inter-pattern messages. Finally, we conduct extensive experiments on real-world urban datasets. Experimental results demonstrate that the proposed MGFN outperforms the state-of-the-art methods by up to 12.35% improvement.
Spatio-Temporal Joint Graph Convolutional Networks for Traffic Forecasting
Dec 02, 2021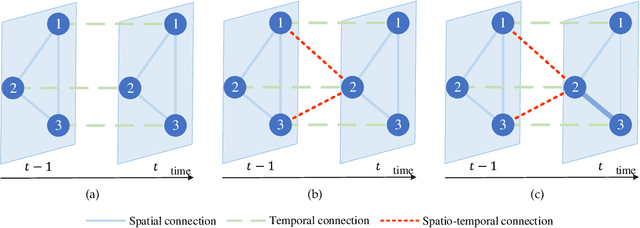
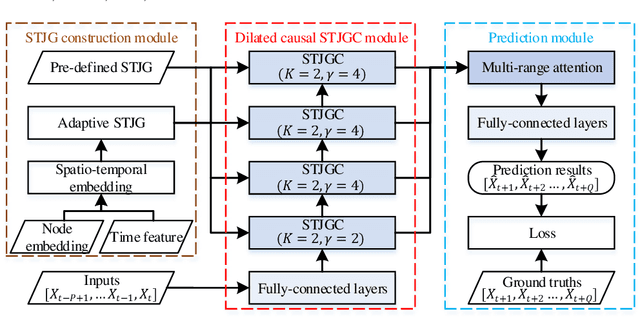

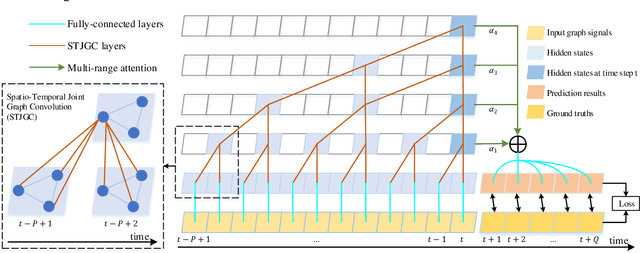
Recent studies focus on formulating the traffic forecasting as a spatio-temporal graph modeling problem. They typically construct a static spatial graph at each time step and then connect each node with itself between adjacent time steps to construct the spatio-temporal graph. In such a graph, the correlations between different nodes at different time steps are not explicitly reflected, which may restrict the learning ability of graph neural networks. Meanwhile, those models ignore the dynamic spatio-temporal correlations among nodes as they use the same adjacency matrix at different time steps. To overcome these limitations, we propose a Spatio-Temporal Joint Graph Convolutional Networks (STJGCN) for traffic forecasting over several time steps ahead on a road network. Specifically, we construct both pre-defined and adaptive spatio-temporal joint graphs (STJGs) between any two time steps, which represent comprehensive and dynamic spatio-temporal correlations. We further design dilated causal spatio-temporal joint graph convolution layers on STJG to capture the spatio-temporal dependencies from distinct perspectives with multiple ranges. A multi-range attention mechanism is proposed to aggregate the information of different ranges. Experiments on four public traffic datasets demonstrate that STJGCN is computationally efficient and outperforms 11 state-of-the-art baseline methods.
GMAN: A Graph Multi-Attention Network for Traffic Prediction
Nov 26, 2019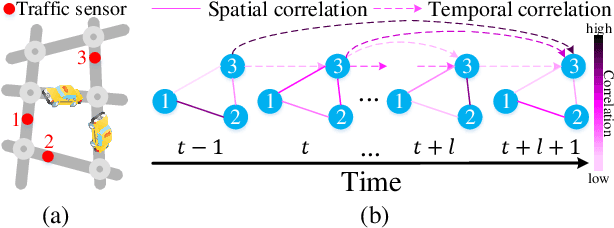
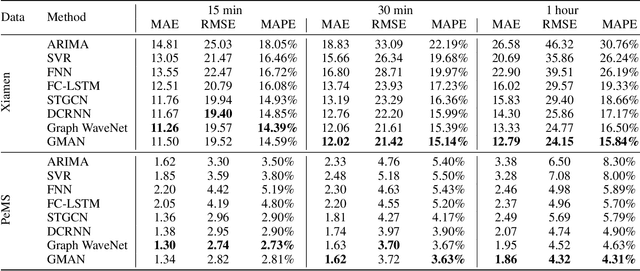
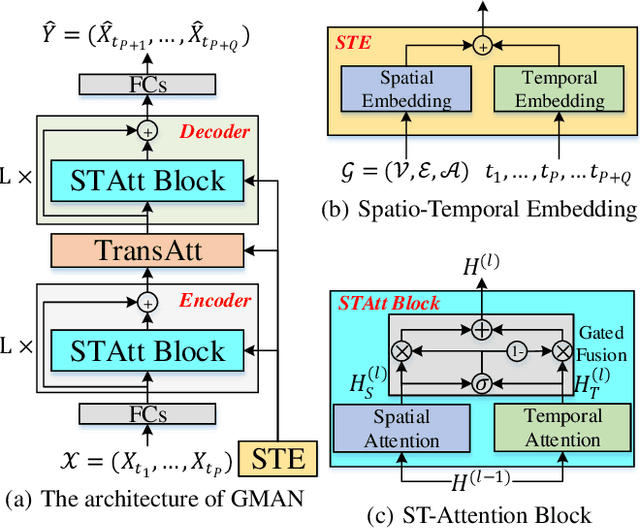
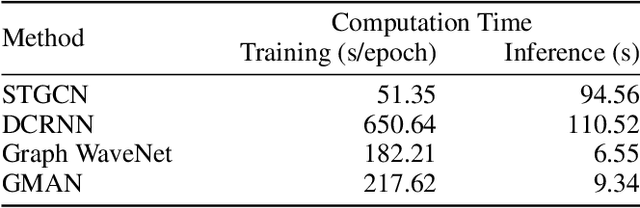
Long-term traffic prediction is highly challenging due to the complexity of traffic systems and the constantly changing nature of many impacting factors. In this paper, we focus on the spatio-temporal factors, and propose a graph multi-attention network (GMAN) to predict traffic conditions for time steps ahead at different locations on a road network graph. GMAN adapts an encoder-decoder architecture, where both the encoder and the decoder consist of multiple spatio-temporal attention blocks to model the impact of the spatio-temporal factors on traffic conditions. The encoder encodes the input traffic features and the decoder predicts the output sequence. Between the encoder and the decoder, a transform attention layer is applied to convert the encoded traffic features to generate the sequence representations of future time steps as the input of the decoder. The transform attention mechanism models the direct relationships between historical and future time steps that helps to alleviate the error propagation problem among prediction time steps. Experimental results on two real-world traffic prediction tasks (i.e., traffic volume prediction and traffic speed prediction) demonstrate the superiority of GMAN. In particular, in the 1 hour ahead prediction, GMAN outperforms state-of-the-art methods by up to 4% improvement in MAE measure. The source code is available at https://github.com/zhengchuanpan/GMAN.