 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConDo: Continual Domain Expansion for Absolute Pose Regression
Dec 18, 2024



Visual localization is a fundamental machine learning problem. Absolute Pose Regression (APR) trains a scene-dependent model to efficiently map an input image to the camera pose in a pre-defined scene. However, many applications have continually changing environments, where inference data at novel poses or scene conditions (weather, geometry) appear after deployment. Training APR on a fixed dataset leads to overfitting, making it fail catastrophically on challenging novel data. This work proposes Continual Domain Expansion (ConDo), which continually collects unlabeled inference data to update the deployed APR. Instead of applying standard unsupervised domain adaptation methods which are ineffective for APR, ConDo effectively learns from unlabeled data by distilling knowledge from scene-agnostic localization methods. By sampling data uniformly from historical and newly collected data, ConDo can effectively expand the generalization domain of APR. Large-scale benchmarks with various scene types are constructed to evaluate models under practical (long-term) data changes. ConDo consistently and significantly outperforms baselines across architectures, scene types, and data changes. On challenging scenes (Fig.1), it reduces the localization error by >7x (14.8m vs 1.7m). Analysis shows the robustness of ConDo against compute budgets, replay buffer sizes and teacher prediction noise. Comparing to model re-training, ConDo achieves similar performance up to 25x faster.
GIM: Learning Generalizable Image Matcher From Internet Videos
Feb 16, 2024



Image matching is a fundamental computer vision problem. While learning-based methods achieve state-of-the-art performance on existing benchmarks, they generalize poorly to in-the-wild images. Such methods typically need to train separate models for different scene types and are impractical when the scene type is unknown in advance. One of the underlying problems is the limited scalability of existing data construction pipelines, which limits the diversity of standard image matching datasets. To address this problem, we propose GIM, a self-training framework for learning a single generalizable model based on any image matching architecture using internet videos, an abundant and diverse data source. Given an architecture, GIM first trains it on standard domain-specific datasets and then combines it with complementary matching methods to create dense labels on nearby frames of novel videos. These labels are filtered by robust fitting, and then enhanced by propagating them to distant frames. The final model is trained on propagated data with strong augmentations. We also propose ZEB, the first zero-shot evaluation benchmark for image matching. By mixing data from diverse domains, ZEB can thoroughly assess the cross-domain generalization performance of different methods. Applying GIM consistently improves the zero-shot performance of 3 state-of-the-art image matching architectures; with 50 hours of YouTube videos, the relative zero-shot performance improves by 8.4%-18.1%. GIM also enables generalization to extreme cross-domain data such as Bird Eye View (BEV) images of projected 3D point clouds (Fig. 1(c)). More importantly, our single zero-shot model consistently outperforms domain-specific baselines when evaluated on downstream tasks inherent to their respective domains. The video presentation is available at https://www.youtube.com/watch?v=FU_MJLD8LeY.
DLA-Net: Learning Dual Local Attention Features for Semantic Segmentation of Large-Scale Building Facade Point Clouds
Jun 01, 2021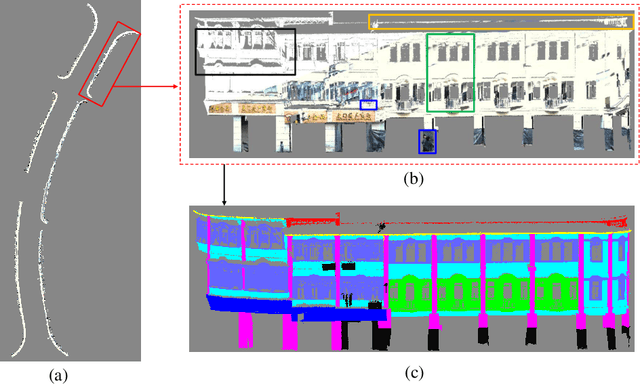
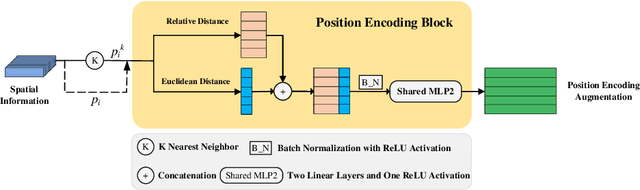
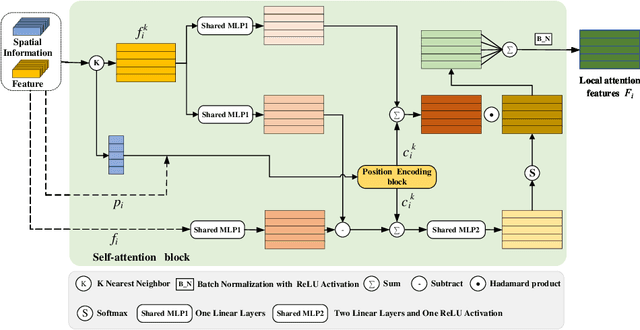
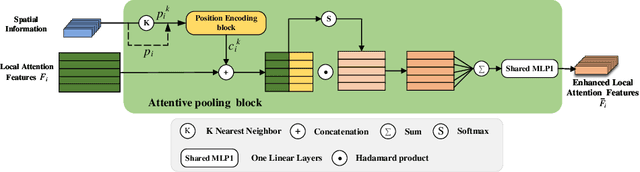
Semantic segmentation of building facade is significant in various applications, such as urban building reconstruction and damage assessment. As there is a lack of 3D point clouds datasets related to the fine-grained building facade, we construct the first large-scale building facade point clouds benchmark dataset for semantic segmentation. The existing methods of semantic segmentation cannot fully mine the local neighborhood information of point clouds. Addressing this problem, we propose a learnable attention module that learns Dual Local Attention features, called DLA in this paper. The proposed DLA module consists of two blocks, including the self-attention block and attentive pooling block, which both embed an enhanced position encoding block. The DLA module could be easily embedded into various network architectures for point cloud segmentation, naturally resulting in a new 3D semantic segmentation network with an encoder-decoder architecture, called DLA-Net in this work. Extensive experimental results on our constructed building facade dataset demonstrate that the proposed DLA-Net achieves better performance than the state-of-the-art methods for semantic segmentation.
A Detector-oblivious Multi-arm Network for Keypoint Matching
Apr 05, 2021


This paper presents a matching network to establish point correspondence between images. We propose a Multi-Arm Network (MAN) to learn region overlap and depth, which can greatly improve the keypoint matching robustness while bringing little computational cost during the inference stage. Another design that makes this framework different from many existing learning based pipelines that require re-training when a different keypoint detector is adopted, our network can directly work with different keypoint detectors without such a time-consuming re-training process. Comprehensive experiments conducted on outdoor and indoor datasets demonstrated that our proposed MAN outperforms state-of-the-art methods. Code will be made publicly available.
RF-Net: An End-to-End Image Matching Network based on Receptive Field
Jun 03, 2019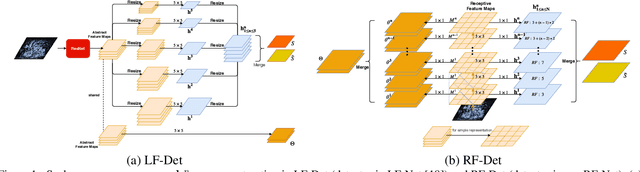
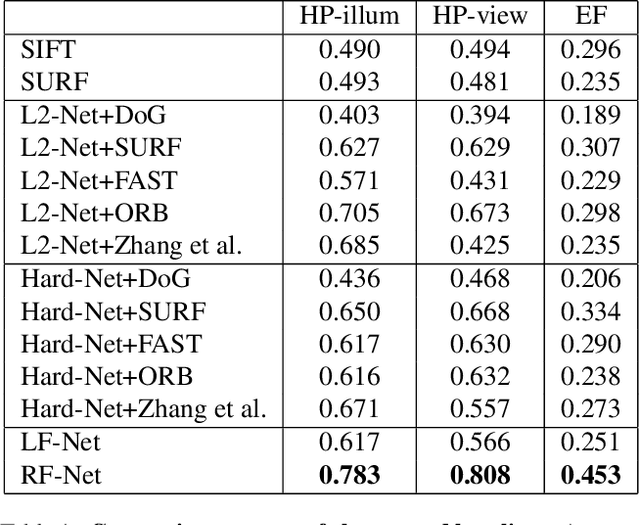
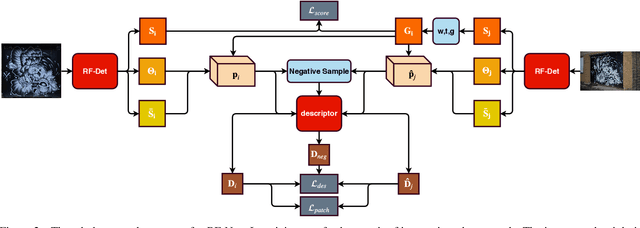
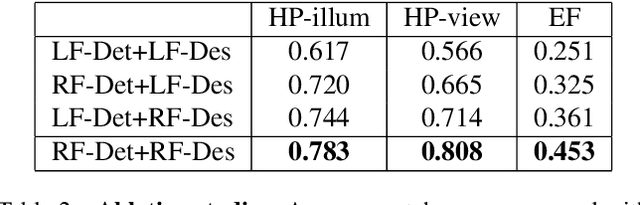
This paper proposes a new end-to-end trainable matching network based on receptive field, RF-Net, to compute sparse correspondence between images. Building end-to-end trainable matching framework is desirable and challenging. The very recent approach, LF-Net, successfully embeds the entire feature extraction pipeline into a jointly trainable pipeline, and produces the state-of-the-art matching results. This paper introduces two modifications to the structure of LF-Net. First, we propose to construct receptive feature maps, which lead to more effective keypoint detection. Second, we introduce a general loss function term, neighbor mask, to facilitate training patch selection. This results in improved stability in descriptor training. We trained RF-Net on the open dataset HPatches, and compared it with other methods on multiple benchmark datasets. Experiments show that RF-Net outperforms existing state-of-the-art methods.