 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-guided Translator Boosts Synthetic-to-Real Unsupervised Domain Adaptive Segmentation of 3D Point Clouds
Mar 27, 20243D synthetic-to-real unsupervised domain adaptive segmentation is crucial to annotating new domains. Self-training is a competitive approach for this task, but its performance is limited by different sensor sampling patterns (i.e., variations in point density) and incomplete training strategies. In this work, we propose a density-guided translator (DGT), which translates point density between domains, and integrates it into a two-stage self-training pipeline named DGT-ST. First, in contrast to existing works that simultaneously conduct data generation and feature/output alignment within unstable adversarial training, we employ the non-learnable DGT to bridge the domain gap at the input level. Second, to provide a well-initialized model for self-training, we propose a category-level adversarial network in stage one that utilizes the prototype to prevent negative transfer. Finally, by leveraging the designs above, a domain-mixed self-training method with source-aware consistency loss is proposed in stage two to narrow the domain gap further. Experiments on two synthetic-to-real segmentation tasks (SynLiDAR $\rightarrow$ semanticKITTI and SynLiDAR $\rightarrow$ semanticPOSS) demonstrate that DGT-ST outperforms state-of-the-art methods, achieving 9.4$\%$ and 4.3$\%$ mIoU improvements, respectively. Code is available at \url{https://github.com/yuan-zm/DGT-ST}.
DLA-Net: Learning Dual Local Attention Features for Semantic Segmentation of Large-Scale Building Facade Point Clouds
Jun 01, 2021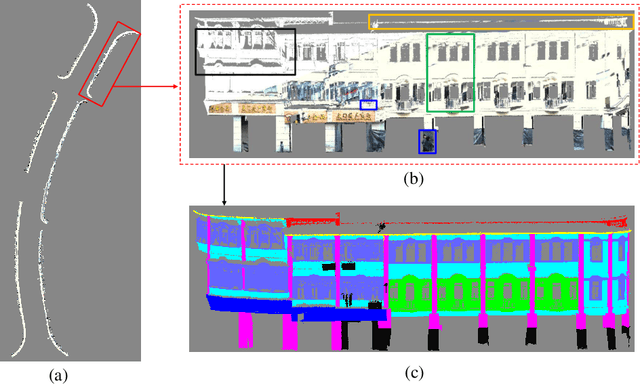
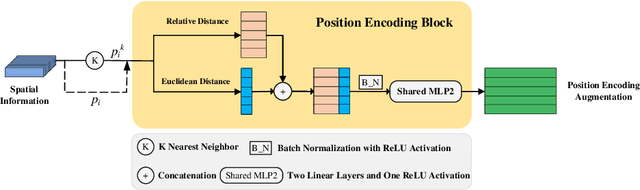
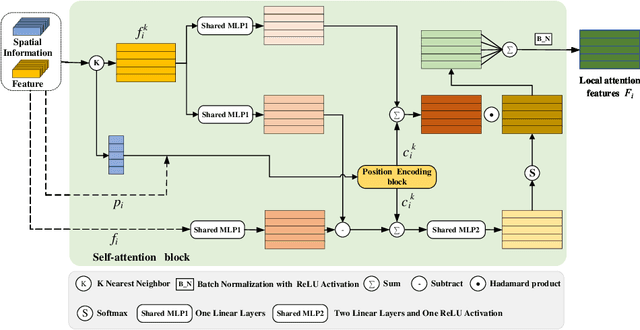
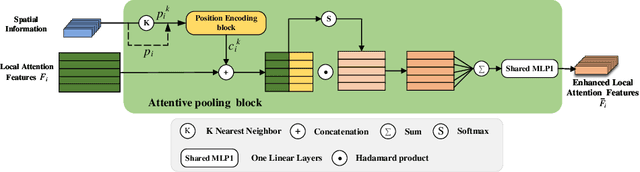
Semantic segmentation of building facade is significant in various applications, such as urban building reconstruction and damage assessment. As there is a lack of 3D point clouds datasets related to the fine-grained building facade, we construct the first large-scale building facade point clouds benchmark dataset for semantic segmentation. The existing methods of semantic segmentation cannot fully mine the local neighborhood information of point clouds. Addressing this problem, we propose a learnable attention module that learns Dual Local Attention features, called DLA in this paper. The proposed DLA module consists of two blocks, including the self-attention block and attentive pooling block, which both embed an enhanced position encoding block. The DLA module could be easily embedded into various network architectures for point cloud segmentation, naturally resulting in a new 3D semantic segmentation network with an encoder-decoder architecture, called DLA-Net in this work. Extensive experimental results on our constructed building facade dataset demonstrate that the proposed DLA-Net achieves better performance than the state-of-the-art methods for semantic segmentation.
HIVE-Net: Centerline-Aware HIerarchical View-Ensemble Convolutional Network for Mitochondria Segmentation in EM Images
Jan 08, 2021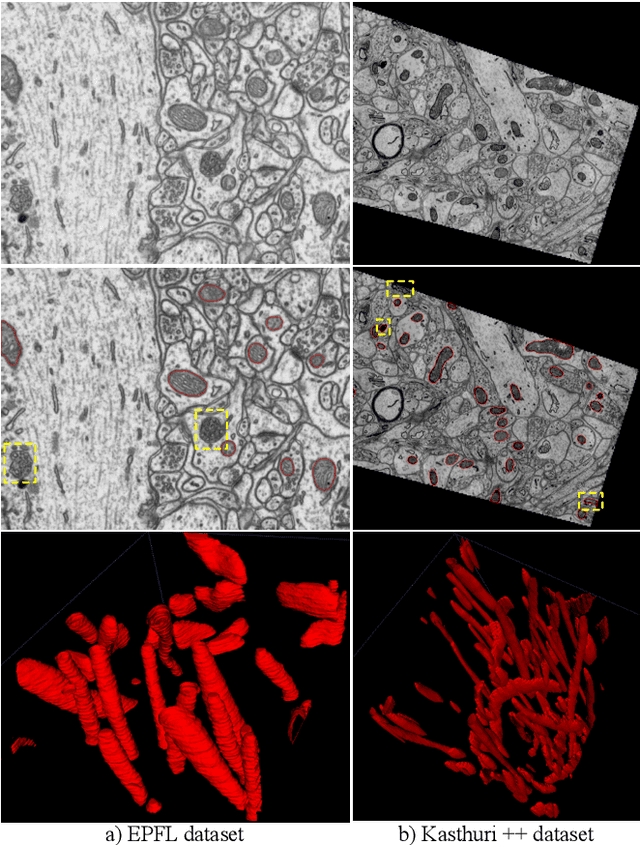
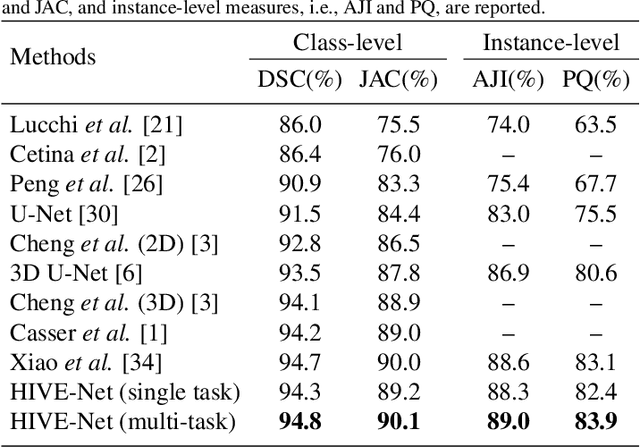
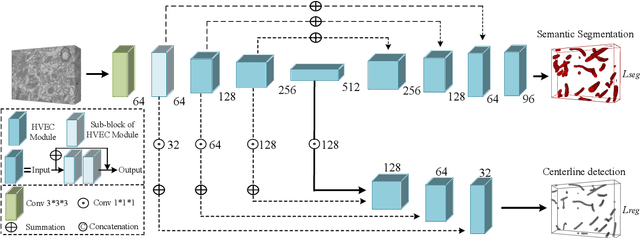

Semantic segmentation of electron microscopy (EM) is an essential step to efficiently obtain reliable morphological statistics. Despite the great success achieved using deep convolutional neural networks (CNNs), they still produce coarse segmentations with lots of discontinuities and false positives for mitochondria segmentation. In this study, we introduce a centerline-aware multitask network by utilizing centerline as an intrinsic shape cue of mitochondria to regularize the segmentation. Since the application of 3D CNNs on large medical volumes is usually hindered by their substantial computational cost and storage overhead, we introduce a novel hierarchical view-ensemble convolution (HVEC), a simple alternative of 3D convolution to learn 3D spatial contexts using more efficient 2D convolutions. The HVEC enables both decomposing and sharing multi-view information, leading to increased learning capacity. Extensive validation results on two challenging benchmarks show that, the proposed method performs favorably against the state-of-the-art methods in accuracy and visual quality but with a greatly reduced model size. Moreover, the proposed model also shows significantly improved generalization ability, especially when training with quite limited amount of training data.
Adversarial-Prediction Guided Multi-task Adaptation for Semantic Segmentation of Electron Microscopy Images
Apr 05, 2020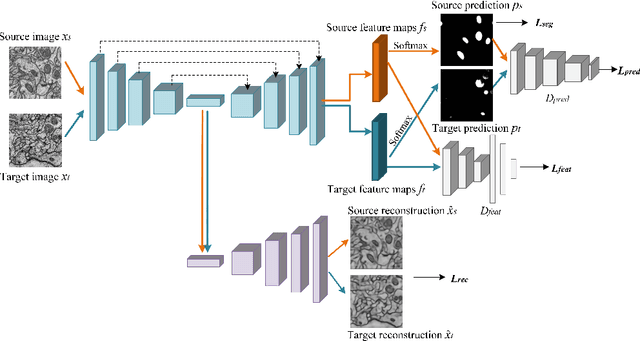
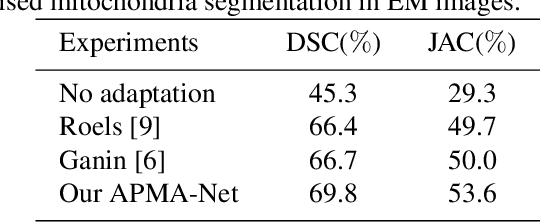


Semantic segmentation is an essential step for electron microscopy (EM) image analysis. Although supervised models have achieved significant progress, the need for labor intensive pixel-wise annotation is a major limitation. To complicate matters further, supervised learning models may not generalize well on a novel dataset due to domain shift. In this study, we introduce an adversarial-prediction guided multi-task network to learn the adaptation of a well-trained model for use on a novel unlabeled target domain. Since no label is available on target domain, we learn an encoding representation not only for the supervised segmentation on source domain but also for unsupervised reconstruction of the target data. To improve the discriminative ability with geometrical cues, we further guide the representation learning by multi-level adversarial learning in semantic prediction space. Comparisons and ablation study on public benchmark demonstrated state-of-the-art performance and effectiveness of our approach.
EM-NET: Centerline-Aware Mitochondria Segmentation in EM Images via Hierarchical View-Ensemble Convolutional Network
Jan 09, 2020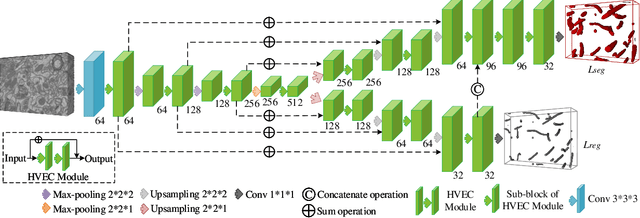
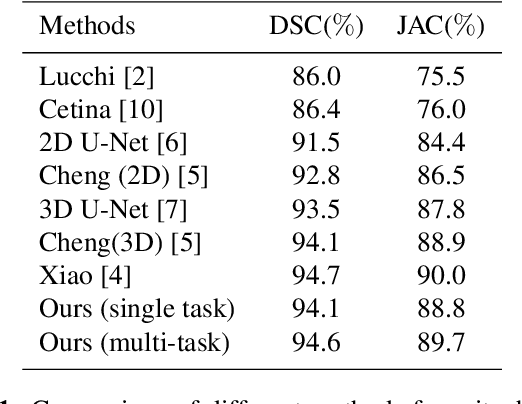
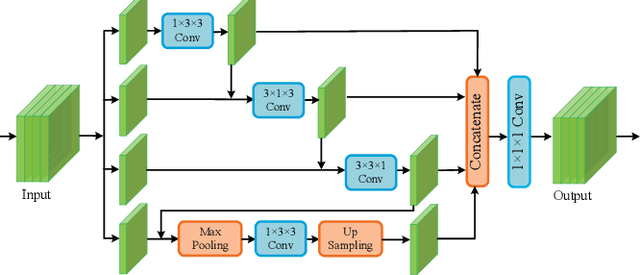
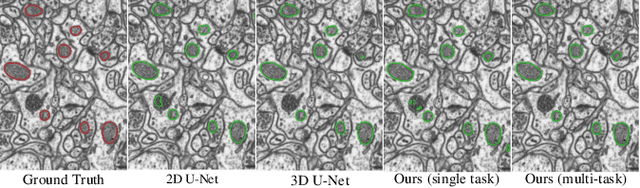
Although deep encoder-decoder networks have achieved astonishing performance for mitochondria segmentation from electron microscopy (EM) images, they still produce coarse segmentations with lots of discontinuities and false positives. Besides, the need for labor intensive annotations of large 3D dataset and huge memory overhead by 3D models are also major limitations. To address these problems, we introduce a multi-task network named EM-Net, which includes an auxiliary centerline detection task to account for shape information of mitochondria represented by centerline. Therefore, the centerline detection sub-network is able to enhance the accuracy and robustness of segmentation task, especially when only a small set of annotated data are available. To achieve a light-weight 3D network, we introduce a novel hierarchical view-ensemble convolution module to reduce number of parameters, and facilitate multi-view information aggregation.Validations on public benchmark showed state-of-the-art performance by EM-Net. Even with significantly reduced training data, our method still showed quite promising results.