 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLA-Net: Learning Dual Local Attention Features for Semantic Segmentation of Large-Scale Building Facade Point Clouds
Paper and Code
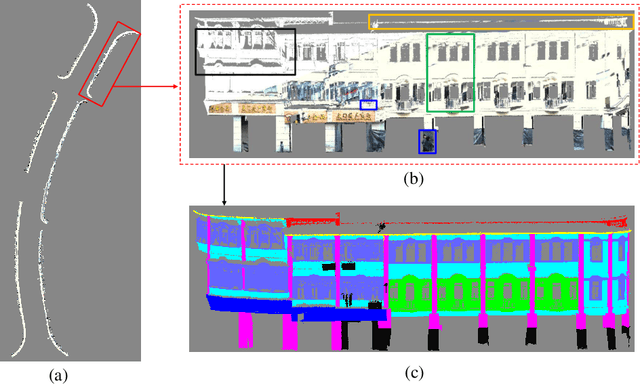
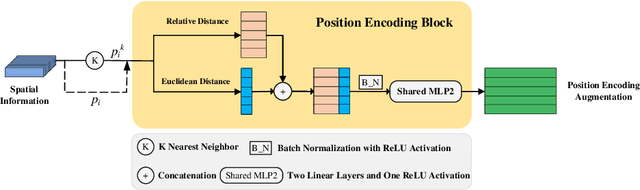
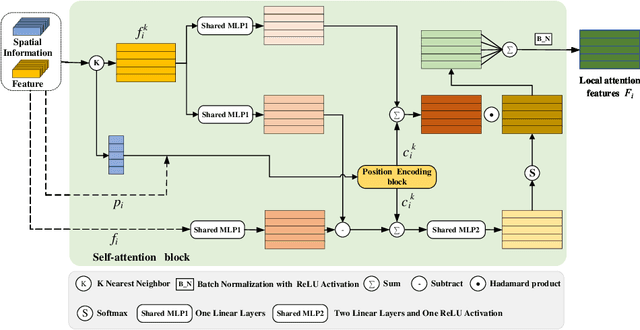
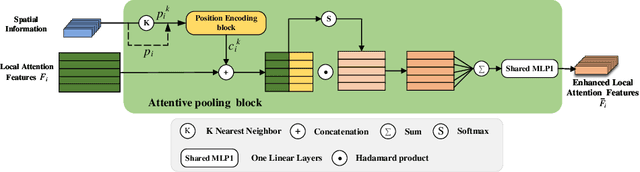
Semantic segmentation of building facade is significant in various applications, such as urban building reconstruction and damage assessment. As there is a lack of 3D point clouds datasets related to the fine-grained building facade, we construct the first large-scale building facade point clouds benchmark dataset for semantic segmentation. The existing methods of semantic segmentation cannot fully mine the local neighborhood information of point clouds. Addressing this problem, we propose a learnable attention module that learns Dual Local Attention features, called DLA in this paper. The proposed DLA module consists of two blocks, including the self-attention block and attentive pooling block, which both embed an enhanced position encoding block. The DLA module could be easily embedded into various network architectures for point cloud segmentation, naturally resulting in a new 3D semantic segmentation network with an encoder-decoder architecture, called DLA-Net in this work. Extensive experimental results on our constructed building facade dataset demonstrate that the proposed DLA-Net achieves better performance than the state-of-the-art methods for semantic segmentation.