 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-guided Translator Boosts Synthetic-to-Real Unsupervised Domain Adaptive Segmentation of 3D Point Clouds
Mar 27, 20243D synthetic-to-real unsupervised domain adaptive segmentation is crucial to annotating new domains. Self-training is a competitive approach for this task, but its performance is limited by different sensor sampling patterns (i.e., variations in point density) and incomplete training strategies. In this work, we propose a density-guided translator (DGT), which translates point density between domains, and integrates it into a two-stage self-training pipeline named DGT-ST. First, in contrast to existing works that simultaneously conduct data generation and feature/output alignment within unstable adversarial training, we employ the non-learnable DGT to bridge the domain gap at the input level. Second, to provide a well-initialized model for self-training, we propose a category-level adversarial network in stage one that utilizes the prototype to prevent negative transfer. Finally, by leveraging the designs above, a domain-mixed self-training method with source-aware consistency loss is proposed in stage two to narrow the domain gap further. Experiments on two synthetic-to-real segmentation tasks (SynLiDAR $\rightarrow$ semanticKITTI and SynLiDAR $\rightarrow$ semanticPOSS) demonstrate that DGT-ST outperforms state-of-the-art methods, achieving 9.4$\%$ and 4.3$\%$ mIoU improvements, respectively. Code is available at \url{https://github.com/yuan-zm/DGT-ST}.
DLA-Net: Learning Dual Local Attention Features for Semantic Segmentation of Large-Scale Building Facade Point Clouds
Jun 01, 2021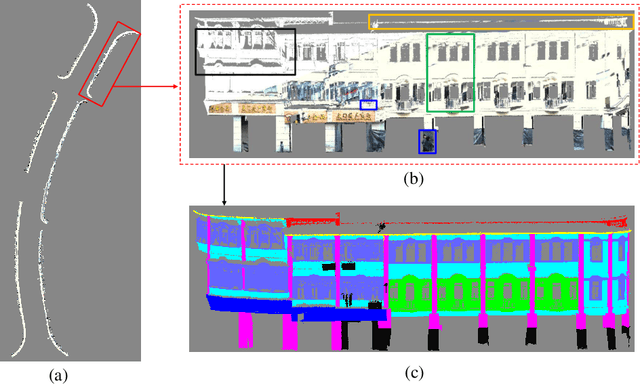
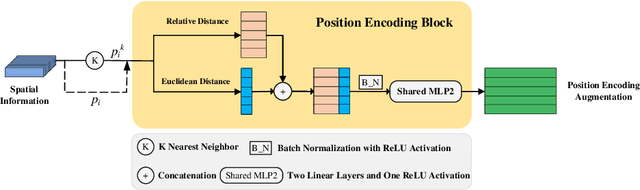
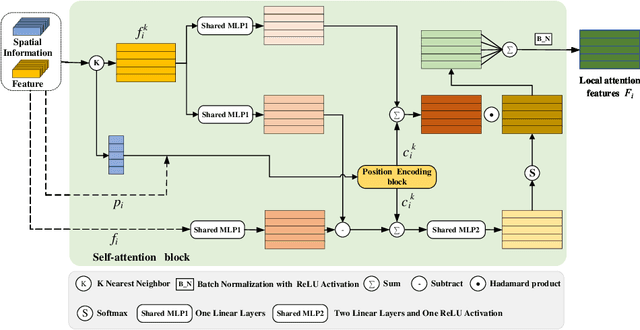
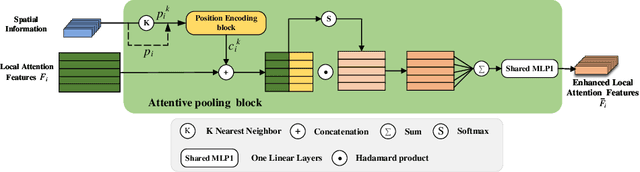
Semantic segmentation of building facade is significant in various applications, such as urban building reconstruction and damage assessment. As there is a lack of 3D point clouds datasets related to the fine-grained building facade, we construct the first large-scale building facade point clouds benchmark dataset for semantic segmentation. The existing methods of semantic segmentation cannot fully mine the local neighborhood information of point clouds. Addressing this problem, we propose a learnable attention module that learns Dual Local Attention features, called DLA in this paper. The proposed DLA module consists of two blocks, including the self-attention block and attentive pooling block, which both embed an enhanced position encoding block. The DLA module could be easily embedded into various network architectures for point cloud segmentation, naturally resulting in a new 3D semantic segmentation network with an encoder-decoder architecture, called DLA-Net in this work. Extensive experimental results on our constructed building facade dataset demonstrate that the proposed DLA-Net achieves better performance than the state-of-the-art methods for semantic segmentation.