 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Value Alignment and Assignment in Cross-Domain Offline Reinforcement Learning with Heterogeneous Datasets
May 24, 2026Cross-domain offline reinforcement learning (RL) aims to learn a policy in the target domain with a limited target domain dataset and a source domain dataset that exhibits a dynamics shift. Training directly on the original source dataset typically leads to performance collapse. Recent studies perform data filtering from the perspective of dynamics alignment or value alignment to enable efficient policy transfer. However, these studies are typically validated on single-domain or single-behavior-policy source datasets. In this work, we explore a more general heterogeneous cross-domain offline RL setting, where the source datasets may be collected from multiple source domains by diverse behavior policies. We first uncover a critical yet overlooked issue in this setting: value misassignment. Empirically and theoretically, we demonstrate that value misassignment can undermine value alignment, mislead data filtering toward selecting suboptimal samples, and loosen the suboptimality gap, thereby degrading the agent's performance. To address this issue, we propose V2A, which integrates dynamics alignment, value alignment, and value assignment. V2A first employs temporally-consistent modality representation learning to extract dynamics modalities from the source dataset, followed by modality-aware advantage learning to rectify value alignment. Finally, it adopts a data filtering paradigm to selectively share source data for policy learning. Empirical results show that V2A significantly outperforms strong baseline methods under general heterogeneous cross-domain offline RL settings.
Model-based Offline RL via Robust Value-Aware Model Learning with Implicitly Differentiable Adaptive Weighting
Mar 09, 2026Model-based offline reinforcement learning (RL) aims to enhance offline RL with a dynamics model that facilitates policy exploration. However, \textit{model exploitation} could occur due to inevitable model errors, degrading algorithm performance. Adversarial model learning offers a theoretical framework to mitigate model exploitation by solving a maximin formulation. Within such a paradigm, RAMBO~\citep{rigter2022rambo} has emerged as a representative and most popular method that provides a practical implementation with model gradient. However, we empirically reveal that severe Q-value underestimation and gradient explosion can occur in RAMBO with only slight hyperparameter tuning, suggesting that it tends to be overly conservative and suffers from unstable model updates. To address these issues, we propose \textbf{RO}bust value-aware \textbf{M}odel learning with \textbf{I}mplicitly differentiable adaptive weighting (ROMI). Instead of updating the dynamics model with model gradient, ROMI introduces a novel robust value-aware model learning approach. This approach requires the dynamics model to predict future states with values close to the minimum Q-value within a scale-adjustable state uncertainty set, enabling controllable conservatism and stable model updates. To further improve out-of-distribution (OOD) generalization during multi-step rollouts, we propose implicitly differentiable adaptive weighting, a bi-level optimization scheme that adaptively achieves dynamics- and value-aware model learning. Empirical results on D4RL and NeoRL datasets show that ROMI significantly outperforms RAMBO and achieves competitive or superior performance compared to other state-of-the-art methods on datasets where RAMBO typically underperforms. Code is available at https://github.com/zq2r/ROMI.git.
Deep Dense Exploration for LLM Reinforcement Learning via Pivot-Driven Resampling
Feb 15, 2026Effective exploration is a key challenge in reinforcement learning for large language models: discovering high-quality trajectories within a limited sampling budget from the vast natural language sequence space. Existing methods face notable limitations: GRPO samples exclusively from the root, saturating high-probability trajectories while leaving deep, error-prone states under-explored. Tree-based methods blindly disperse budgets across trivial or unrecoverable states, causing sampling dilution that fails to uncover rare correct suffixes and destabilizes local baselines. To address this, we propose Deep Dense Exploration (DDE), a strategy that focuses exploration on $\textit{pivots}$-deep, recoverable states within unsuccessful trajectories. We instantiate DDE with DEEP-GRPO, which introduces three key innovations: (1) a lightweight data-driven utility function that automatically balances recoverability and depth bias to identify pivot states; (2) local dense resampling at each pivot to increase the probability of discovering correct subsequent trajectories; and (3) a dual-stream optimization objective that decouples global policy learning from local corrective updates. Experiments on mathematical reasoning benchmarks demonstrate that our method consistently outperforms GRPO, tree-based methods, and other strong baselines.
Temporal Difference Learning with Constrained Initial Representations
Feb 12, 2026Recently, there have been numerous attempts to enhance the sample efficiency of off-policy reinforcement learning (RL) agents when interacting with the environment, including architecture improvements and new algorithms. Despite these advances, they overlook the potential of directly constraining the initial representations of the input data, which can intuitively alleviate the distribution shift issue and stabilize training. In this paper, we introduce the Tanh function into the initial layer to fulfill such a constraint. We theoretically unpack the convergence property of the temporal difference learning with the Tanh function under linear function approximation. Motivated by theoretical insights, we present our Constrained Initial Representations framework, tagged CIR, which is made up of three components: (i) the Tanh activation along with normalization methods to stabilize representations; (ii) the skip connection module to provide a linear pathway from the shallow layer to the deep layer; (iii) the convex Q-learning that allows a more flexible value estimate and mitigates potential conservatism. Empirical results show that CIR exhibits strong performance on numerous continuous control tasks, even being competitive or surpassing existing strong baseline methods.
Cross-Domain Offline Policy Adaptation via Selective Transition Correction
Feb 05, 2026It remains a critical challenge to adapt policies across domains with mismatched dynamics in reinforcement learning (RL). In this paper, we study cross-domain offline RL, where an offline dataset from another similar source domain can be accessed to enhance policy learning upon a target domain dataset. Directly merging the two datasets may lead to suboptimal performance due to potential dynamics mismatches. Existing approaches typically mitigate this issue through source domain transition filtering or reward modification, which, however, may lead to insufficient exploitation of the valuable source domain data. Instead, we propose to modify the source domain data into the target domain data. To that end, we leverage an inverse policy model and a reward model to correct the actions and rewards of source transitions, explicitly achieving alignment with the target dynamics. Since limited data may result in inaccurate model training, we further employ a forward dynamics model to retain corrected samples that better match the target dynamics than the original transitions. Consequently, we propose the Selective Transition Correction (STC) algorithm, which enables reliable usage of source domain data for policy adaptation. Experiments on various environments with dynamics shifts demonstrate that STC achieves superior performance against existing baselines.
Sample-Efficient Policy Constraint Offline Deep Reinforcement Learning based on Sample Filtering
Dec 23, 2025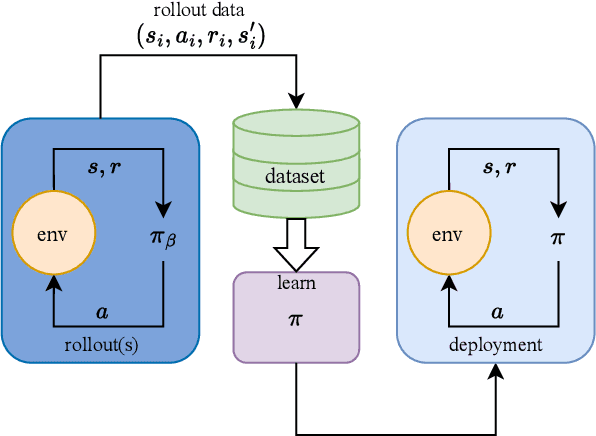
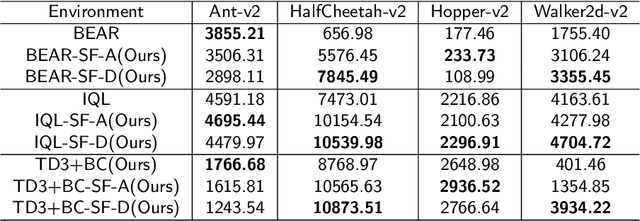
Offline reinforcement learning (RL) aims to learn a policy that maximizes the expected return using a given static dataset of transitions. However, offline RL faces the distribution shift problem. The policy constraint offline RL method is proposed to solve the distribution shift problem. During the policy constraint offline RL training, it is important to ensure the difference between the learned policy and behavior policy within a given threshold. Thus, the learned policy heavily relies on the quality of the behavior policy. However, a problem exists in existing policy constraint methods: if the dataset contains many low-reward transitions, the learned will be contained with a suboptimal reference policy, leading to slow learning speed, low sample efficiency, and inferior performances. This paper shows that the sampling method in policy constraint offline RL that uses all the transitions in the dataset can be improved. A simple but efficient sample filtering method is proposed to improve the sample efficiency and the final performance. First, we evaluate the score of the transitions by average reward and average discounted reward of episodes in the dataset and extract the transition samples of high scores. Second, the high-score transition samples are used to train the offline RL algorithms. We verify the proposed method in a series of offline RL algorithms and benchmark tasks. Experimental results show that the proposed method outperforms baselines.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025
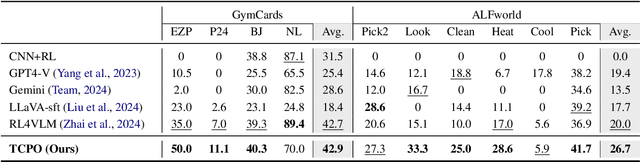
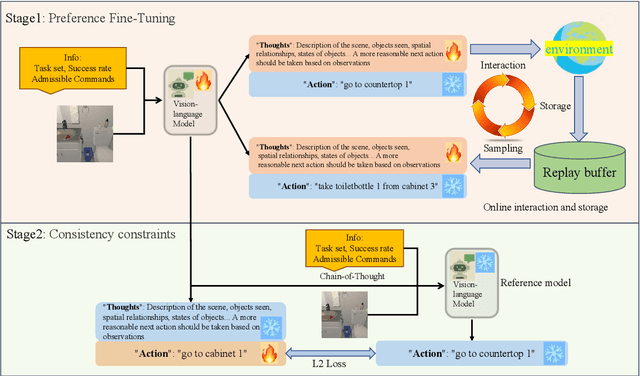

Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
SUMO: Search-Based Uncertainty Estimation for Model-Based Offline Reinforcement Learning
Aug 23, 2024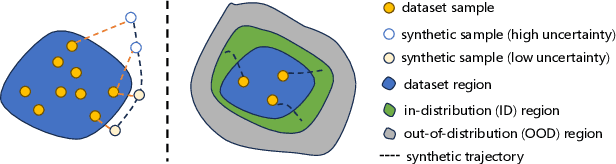
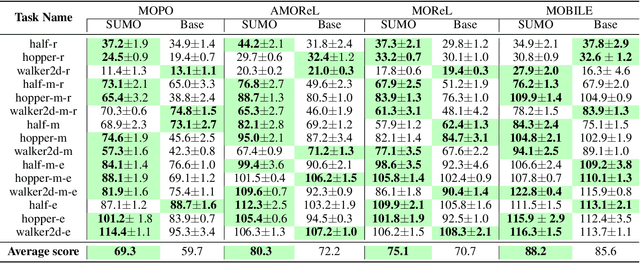
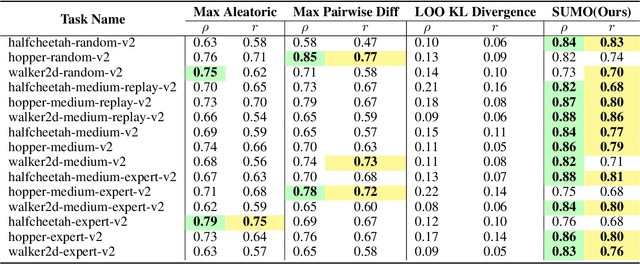

The performance of offline reinforcement learning (RL) suffers from the limited size and quality of static datasets. Model-based offline RL addresses this issue by generating synthetic samples through a dynamics model to enhance overall performance. To evaluate the reliability of the generated samples, uncertainty estimation methods are often employed. However, model ensemble, the most commonly used uncertainty estimation method, is not always the best choice. In this paper, we propose a \textbf{S}earch-based \textbf{U}ncertainty estimation method for \textbf{M}odel-based \textbf{O}ffline RL (SUMO) as an alternative. SUMO characterizes the uncertainty of synthetic samples by measuring their cross entropy against the in-distribution dataset samples, and uses an efficient search-based method for implementation. In this way, SUMO can achieve trustworthy uncertainty estimation. We integrate SUMO into several model-based offline RL algorithms including MOPO and Adapted MOReL (AMOReL), and provide theoretical analysis for them. Extensive experimental results on D4RL datasets demonstrate that SUMO can provide more accurate uncertainty estimation and boost the performance of base algorithms. These indicate that SUMO could be a better uncertainty estimator for model-based offline RL when used in either reward penalty or trajectory truncation. Our code is available and will be open-source for further research and development.
The primacy bias in Model-based RL
Oct 23, 2023The primacy bias in deep reinforcement learning (DRL), which refers to the agent's tendency to overfit early data and lose the ability to learn from new data, can significantly decrease the performance of DRL algorithms. Previous studies have shown that employing simple techniques, such as resetting the agent's parameters, can substantially alleviate the primacy bias. However, we observe that resetting the agent's parameters harms its performance in the context of model-based reinforcement learning (MBRL). In fact, on further investigation, we find that the primacy bias in MBRL differs from that in model-free RL. In this work, we focus on investigating the primacy bias in MBRL and propose world model resetting, which works in MBRL. We apply our method to two different MBRL algorithms, MBPO and DreamerV2. We validate the effectiveness of our method on multiple continuous control tasks on MuJoCo and DeepMind Control Suite, as well as discrete control tasks on Atari 100k benchmark. The results show that world model resetting can significantly alleviate the primacy bias in model-based setting and improve algorithm's performance. We also give a guide on how to perform world model resetting effectively.