 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUMO: Search-Based Uncertainty Estimation for Model-Based Offline Reinforcement Learning
Paper and Code
Aug 23, 2024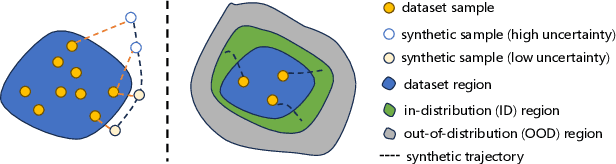
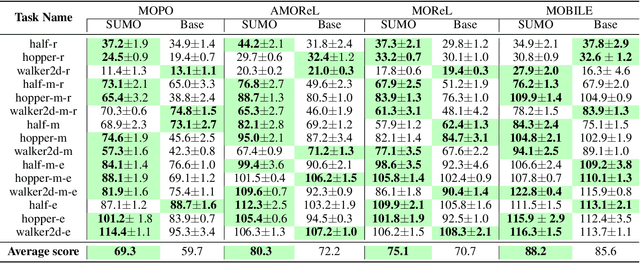
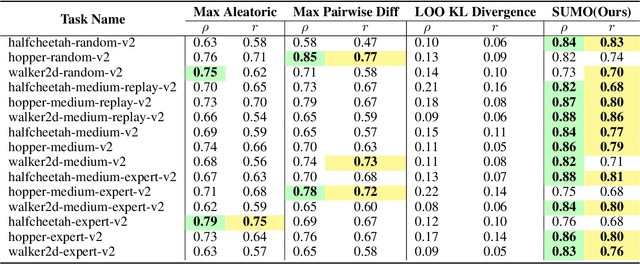

The performance of offline reinforcement learning (RL) suffers from the limited size and quality of static datasets. Model-based offline RL addresses this issue by generating synthetic samples through a dynamics model to enhance overall performance. To evaluate the reliability of the generated samples, uncertainty estimation methods are often employed. However, model ensemble, the most commonly used uncertainty estimation method, is not always the best choice. In this paper, we propose a \textbf{S}earch-based \textbf{U}ncertainty estimation method for \textbf{M}odel-based \textbf{O}ffline RL (SUMO) as an alternative. SUMO characterizes the uncertainty of synthetic samples by measuring their cross entropy against the in-distribution dataset samples, and uses an efficient search-based method for implementation. In this way, SUMO can achieve trustworthy uncertainty estimation. We integrate SUMO into several model-based offline RL algorithms including MOPO and Adapted MOReL (AMOReL), and provide theoretical analysis for them. Extensive experimental results on D4RL datasets demonstrate that SUMO can provide more accurate uncertainty estimation and boost the performance of base algorithms. These indicate that SUMO could be a better uncertainty estimator for model-based offline RL when used in either reward penalty or trajectory truncation. Our code is available and will be open-source for further research and development.