 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Fusion for RGB-D Salient Object Detection
Paper and Code

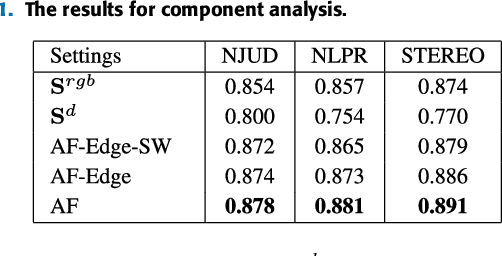
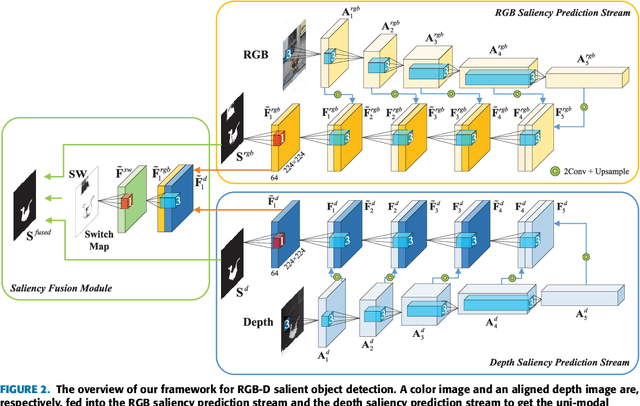
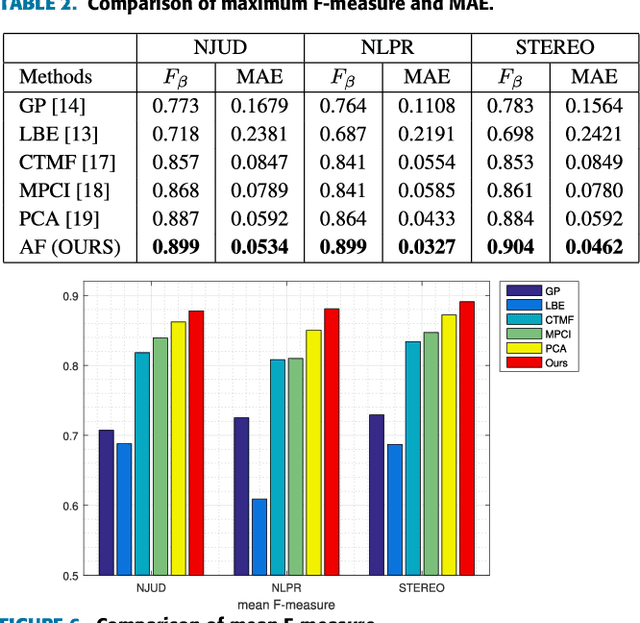
RGB-D salient object detection aims to identify the most visually distinctive objects in a pair of color and depth images. Based upon an observation that most of the salient objects may stand out at least in one modality, this paper proposes an adaptive fusion scheme to fuse saliency predictions generated from two modalities. Specifically, we design a two-streamed convolutional neural network (CNN), each of which extracts features and predicts a saliency map from either RGB or depth modality. Then, a saliency fusion module learns a switch map that is used to adaptively fuse the predicted saliency maps. A loss function composed of saliency supervision, switch map supervision, and edge-preserving constraints is designed to make full supervision, and the entire network is trained in an end-to-end manner. Benefited from the adaptive fusion strategy and the edge-preserving constraint, our approach outperforms state-of-the-art methods on three publicly available datasets.