 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat-If Analysis of Large Language Models: Explore the Game World Using Proactive Thinking
Sep 05, 2025Large language models (LLMs) excel at processing information reactively but lack the ability to systemically explore hypothetical futures. They cannot ask, "what if we take this action? how will it affect the final outcome" and forecast its potential consequences before acting. This critical gap limits their utility in dynamic, high-stakes scenarios like strategic planning, risk assessment, and real-time decision making. To bridge this gap, we propose WiA-LLM, a new paradigm that equips LLMs with proactive thinking capabilities. Our approach integrates What-If Analysis (WIA), a systematic approach for evaluating hypothetical scenarios by changing input variables. By leveraging environmental feedback via reinforcement learning, WiA-LLM moves beyond reactive thinking. It dynamically simulates the outcomes of each potential action, enabling the model to anticipate future states rather than merely react to the present conditions. We validate WiA-LLM in Honor of Kings (HoK), a complex multiplayer game environment characterized by rapid state changes and intricate interactions. The game's real-time state changes require precise multi-step consequence prediction, making it an ideal testbed for our approach. Experimental results demonstrate WiA-LLM achieves a remarkable 74.2% accuracy in forecasting game-state changes (up to two times gain over baselines). The model shows particularly significant gains in high-difficulty scenarios where accurate foresight is critical. To our knowledge, this is the first work to formally explore and integrate what-if analysis capabilities within LLMs. WiA-LLM represents a fundamental advance toward proactive reasoning in LLMs, providing a scalable framework for robust decision-making in dynamic environments with broad implications for strategic applications.
Yan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
ProGDF: Progressive Gaussian Differential Field for Controllable and Flexible 3D Editing
Dec 11, 2024



3D editing plays a crucial role in editing and reusing existing 3D assets, thereby enhancing productivity. Recently, 3DGS-based methods have gained increasing attention due to their efficient rendering and flexibility. However, achieving desired 3D editing results often requires multiple adjustments in an iterative loop, resulting in tens of minutes of training time cost for each attempt and a cumbersome trial-and-error cycle for users. This in-the-loop training paradigm results in a poor user experience. To address this issue, we introduce the concept of process-oriented modelling for 3D editing and propose the Progressive Gaussian Differential Field (ProGDF), an out-of-loop training approach that requires only a single training session to provide users with controllable editing capability and variable editing results through a user-friendly interface in real-time. ProGDF consists of two key components: Progressive Gaussian Splatting (PGS) and Gaussian Differential Field (GDF). PGS introduces the progressive constraint to extract the diverse intermediate results of the editing process and employs rendering quality regularization to improve the quality of these results. Based on these intermediate results, GDF leverages a lightweight neural network to model the editing process. Extensive results on two novel applications, namely controllable 3D editing and flexible fine-grained 3D manipulation, demonstrate the effectiveness, practicality and flexibility of the proposed ProGDF.
GUESS:GradUally Enriching SyntheSis for Text-Driven Human Motion Generation
Jan 06, 2024In this paper, we propose a novel cascaded diffusion-based generative framework for text-driven human motion synthesis, which exploits a strategy named GradUally Enriching SyntheSis (GUESS as its abbreviation). The strategy sets up generation objectives by grouping body joints of detailed skeletons in close semantic proximity together and then replacing each of such joint group with a single body-part node. Such an operation recursively abstracts a human pose to coarser and coarser skeletons at multiple granularity levels. With gradually increasing the abstraction level, human motion becomes more and more concise and stable, significantly benefiting the cross-modal motion synthesis task. The whole text-driven human motion synthesis problem is then divided into multiple abstraction levels and solved with a multi-stage generation framework with a cascaded latent diffusion model: an initial generator first generates the coarsest human motion guess from a given text description; then, a series of successive generators gradually enrich the motion details based on the textual description and the previous synthesized results. Notably, we further integrate GUESS with the proposed dynamic multi-condition fusion mechanism to dynamically balance the cooperative effects of the given textual condition and synthesized coarse motion prompt in different generation stages. Extensive experiments on large-scale datasets verify that GUESS outperforms existing state-of-the-art methods by large margins in terms of accuracy, realisticness, and diversity. Code is available at https://github.com/Xuehao-Gao/GUESS.
Towards Detailed Text-to-Motion Synthesis via Basic-to-Advanced Hierarchical Diffusion Model
Dec 18, 2023



Text-guided motion synthesis aims to generate 3D human motion that not only precisely reflects the textual description but reveals the motion details as much as possible. Pioneering methods explore the diffusion model for text-to-motion synthesis and obtain significant superiority. However, these methods conduct diffusion processes either on the raw data distribution or the low-dimensional latent space, which typically suffer from the problem of modality inconsistency or detail-scarce. To tackle this problem, we propose a novel Basic-to-Advanced Hierarchical Diffusion Model, named B2A-HDM, to collaboratively exploit low-dimensional and high-dimensional diffusion models for high quality detailed motion synthesis. Specifically, the basic diffusion model in low-dimensional latent space provides the intermediate denoising result that to be consistent with the textual description, while the advanced diffusion model in high-dimensional latent space focuses on the following detail-enhancing denoising process. Besides, we introduce a multi-denoiser framework for the advanced diffusion model to ease the learning of high-dimensional model and fully explore the generative potential of the diffusion model. Quantitative and qualitative experiment results on two text-to-motion benchmarks (HumanML3D and KIT-ML) demonstrate that B2A-HDM can outperform existing state-of-the-art methods in terms of fidelity, modality consistency, and diversity.
Act As You Wish: Fine-Grained Control of Motion Diffusion Model with Hierarchical Semantic Graphs
Nov 02, 2023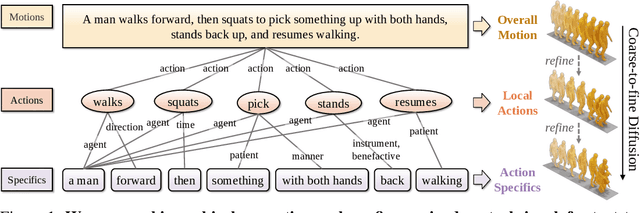

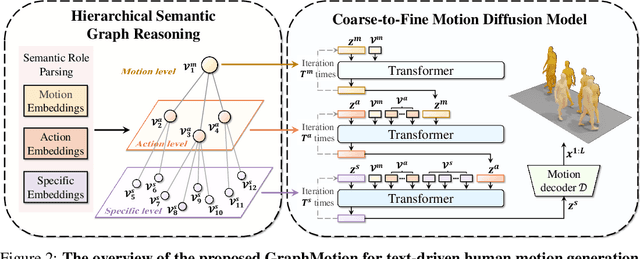
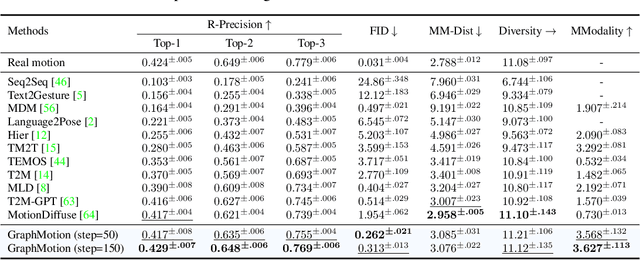
Most text-driven human motion generation methods employ sequential modeling approaches, e.g., transformer, to extract sentence-level text representations automatically and implicitly for human motion synthesis. However, these compact text representations may overemphasize the action names at the expense of other important properties and lack fine-grained details to guide the synthesis of subtly distinct motion. In this paper, we propose hierarchical semantic graphs for fine-grained control over motion generation. Specifically, we disentangle motion descriptions into hierarchical semantic graphs including three levels of motions, actions, and specifics. Such global-to-local structures facilitate a comprehensive understanding of motion description and fine-grained control of motion generation. Correspondingly, to leverage the coarse-to-fine topology of hierarchical semantic graphs, we decompose the text-to-motion diffusion process into three semantic levels, which correspond to capturing the overall motion, local actions, and action specifics. Extensive experiments on two benchmark human motion datasets, including HumanML3D and KIT, with superior performances, justify the efficacy of our method. More encouragingly, by modifying the edge weights of hierarchical semantic graphs, our method can continuously refine the generated motion, which may have a far-reaching impact on the community. Code and pre-training weights are available at https://github.com/jpthu17/GraphMotion.
Speech2Lip: High-fidelity Speech to Lip Generation by Learning from a Short Video
Sep 09, 2023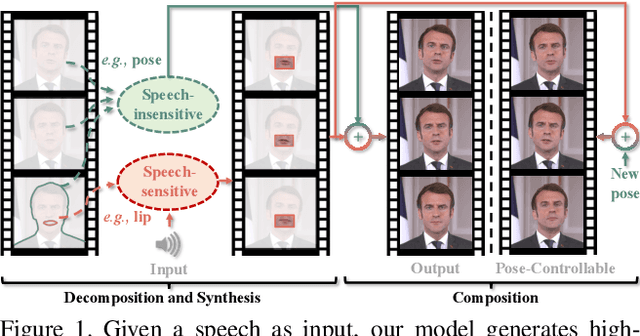
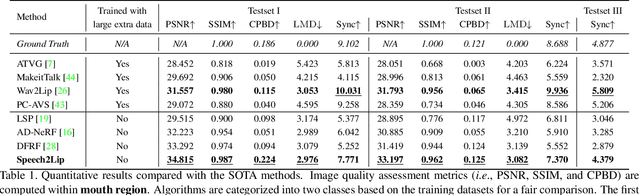

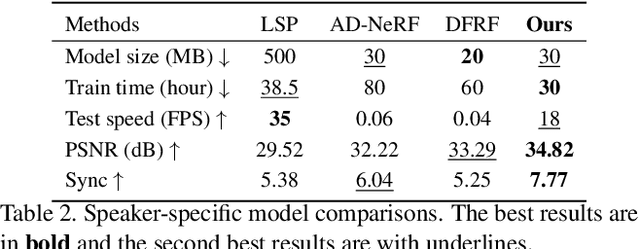
Synthesizing realistic videos according to a given speech is still an open challenge. Previous works have been plagued by issues such as inaccurate lip shape generation and poor image quality. The key reason is that only motions and appearances on limited facial areas (e.g., lip area) are mainly driven by the input speech. Therefore, directly learning a mapping function from speech to the entire head image is prone to ambiguity, particularly when using a short video for training. We thus propose a decomposition-synthesis-composition framework named Speech to Lip (Speech2Lip) that disentangles speech-sensitive and speech-insensitive motion/appearance to facilitate effective learning from limited training data, resulting in the generation of natural-looking videos. First, given a fixed head pose (i.e., canonical space), we present a speech-driven implicit model for lip image generation which concentrates on learning speech-sensitive motion and appearance. Next, to model the major speech-insensitive motion (i.e., head movement), we introduce a geometry-aware mutual explicit mapping (GAMEM) module that establishes geometric mappings between different head poses. This allows us to paste generated lip images at the canonical space onto head images with arbitrary poses and synthesize talking videos with natural head movements. In addition, a Blend-Net and a contrastive sync loss are introduced to enhance the overall synthesis performance. Quantitative and qualitative results on three benchmarks demonstrate that our model can be trained by a video of just a few minutes in length and achieve state-of-the-art performance in both visual quality and speech-visual synchronization. Code: https://github.com/CVMI-Lab/Speech2Lip.
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Jul 07, 20233D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.
EE-TTS: Emphatic Expressive TTS with Linguistic Information
May 20, 2023While Current TTS systems perform well in synthesizing high-quality speech, producing highly expressive speech remains a challenge. Emphasis, as a critical factor in determining the expressiveness of speech, has attracted more attention nowadays. Previous works usually enhance the emphasis by adding intermediate features, but they can not guarantee the overall expressiveness of the speech. To resolve this matter, we propose Emphatic Expressive TTS (EE-TTS), which leverages multi-level linguistic information from syntax and semantics. EE-TTS contains an emphasis predictor that can identify appropriate emphasis positions from text and a conditioned acoustic model to synthesize expressive speech with emphasis and linguistic information. Experimental results indicate that EE-TTS outperforms baseline with MOS improvements of 0.49 and 0.67 in expressiveness and naturalness. EE-TTS also shows strong generalization across different datasets according to AB test results.
ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling
Apr 19, 2023The research fields of parametric face models and 3D face reconstruction have been extensively studied. However, a critical question remains unanswered: how to tailor the face model for specific reconstruction settings. We argue that reconstruction with multi-view uncalibrated images demands a new model with stronger capacity. Our study shifts attention from data-dependent 3D Morphable Models (3DMM) to an understudied human-designed skinning model. We propose Adaptive Skinning Model (ASM), which redefines the skinning model with more compact and fully tunable parameters. With extensive experiments, we demonstrate that ASM achieves significantly improved capacity than 3DMM, with the additional advantage of model size and easy implementation for new topology. We achieve state-of-the-art performance with ASM for multi-view reconstruction on the Florence MICC Coop benchmark. Our quantitative analysis demonstrates the importance of a high-capacity model for fully exploiting abundant information from multi-view input in reconstruction. Furthermore, our model with physical-semantic parameters can be directly utilized for real-world applications, such as in-game avatar creation. As a result, our work opens up new research directions for the parametric face models and facilitates future research on multi-view reconstruction.