 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Causal Reasoning Method for Explaining Medical Image Segmentation Models
Feb 24, 2026Medical image segmentation plays a vital role in clinical decision-making, enabling precise localization of lesions and guiding interventions. Despite significant advances in segmentation accuracy, the black-box nature of most deep models has raised growing concerns about their trustworthiness in high-stakes medical scenarios. Current explanation techniques have primarily focused on classification tasks, leaving the segmentation domain relatively underexplored. We introduced an explanation model for segmentation task which employs the causal inference framework and backpropagates the average treatment effect (ATE) into a quantification metric to determine the influence of input regions, as well as network components, on target segmentation areas. Through comparison with recent segmentation explainability techniques on two representative medical imaging datasets, we demonstrated that our approach provides more faithful explanations than existing approaches. Furthermore, we carried out a systematic causal analysis of multiple foundational segmentation models using our method, which reveals significant heterogeneity in perceptual strategies across different models, and even between different inputs for the same model. Suggesting the potential of our method to provide notable insights for optimizing segmentation models. Our code can be found at https://github.com/lcmmai/PdCR.
Attention-MoA: Enhancing Mixture-of-Agents via Inter-Agent Semantic Attention and Deep Residual Synthesis
Jan 23, 2026As the development of Large Language Models (LLMs) shifts from parameter scaling to inference-time collaboration, the Mixture-of-Agents (MoA) framework has emerged as a general paradigm to harness collective intelligence by layering diverse models. While recent MoA variants have introduced dynamic routing and residual connections to improve efficiency, these methods often fail to facilitate deep semantic interaction between agents, limiting the system's ability to actively correct hallucinations and refine logic. In this paper, we introduce Attention-MoA, a novel MoA-based framework that redefines collaboration through Inter-agent Semantic Attention. Complemented by an Inter-layer Residual Module with Adaptive Early Stopping Mechanism, our architecture mitigates information degradation in deep layers while improving computational efficiency. Extensive evaluations across AlpacaEval 2.0, MT-Bench, and FLASK demonstrate that Attention-MoA significantly outperforms state-of-the-art baselines, achieving a 91.15% Length-Controlled Win Rate on AlpacaEval 2.0 and dominating in 10 out of 12 capabilities on FLASK. Notably, Attention-MoA enables an ensemble of small open-source models to outperform massive proprietary models like Claude-4.5-Sonnet and GPT-4.1, achieving an MT-Bench score of 8.83 and an AlpacaEval 2.0 LC Win Rate of 77.36%.
Well Begun, Half Done: Reinforcement Learning with Prefix Optimization for LLM Reasoning
Dec 17, 2025Reinforcement Learning with Verifiable Rewards (RLVR) significantly enhances the reasoning capability of Large Language Models (LLMs). Current RLVR approaches typically conduct training across all generated tokens, but neglect to explore which tokens (e.g., prefix tokens) actually contribute to reasoning. This uniform training strategy spends substantial effort on optimizing low-return tokens, which in turn impedes the potential improvement from high-return tokens and reduces overall training effectiveness. To address this issue, we propose a novel RLVR approach called Progressive Prefix-token Policy Optimization (PPPO), which highlights the significance of the prefix segment of generated outputs. Specifically, inspired by the well-established human thinking theory of Path Dependence, where early-stage thoughts substantially constrain subsequent thinking trajectory, we identify an analogous phenomenon in LLM reasoning termed Beginning Lock-in Effect (BLE). PPPO leverages this finding by focusing its optimization objective on the prefix reasoning process of LLMs. This targeted optimization strategy can positively influence subsequent reasoning processes, and ultimately improve final results. To improve the learning effectiveness of LLMs on how to start reasoning with high quality, PPPO introduces two training strategies: (a) Progressive Prefix Retention, which shapes a progressive learning process by increasing the proportion of retained prefix tokens during training; (b) Continuation Accumulated Reward, which mitigates reward bias by sampling multiple continuations for one prefix token sequence, and accumulating their scores as the reward signal. Extensive experimental results on various reasoning tasks demonstrate that our proposed PPPO outperforms representative RLVR methods, with the accuracy improvements of 18.02% on only 26.17% training tokens.
Clear Nights Ahead: Towards Multi-Weather Nighttime Image Restoration
May 22, 2025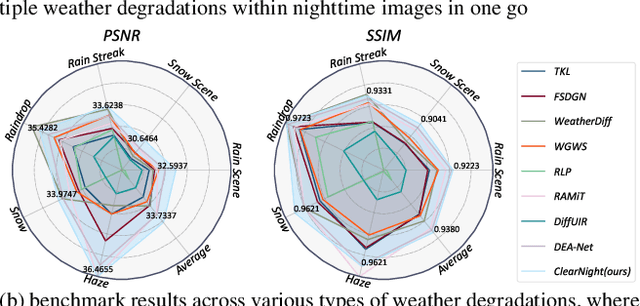
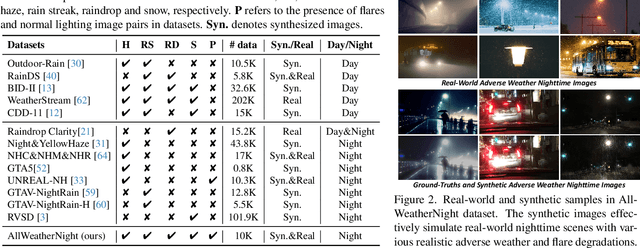

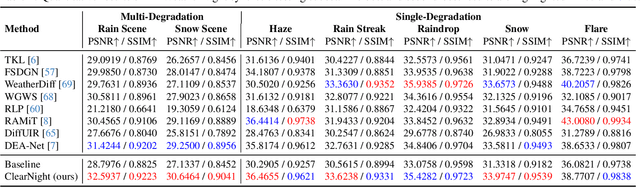
Restoring nighttime images affected by multiple adverse weather conditions is a practical yet under-explored research problem, as multiple weather conditions often coexist in the real world alongside various lighting effects at night. This paper first explores the challenging multi-weather nighttime image restoration task, where various types of weather degradations are intertwined with flare effects. To support the research, we contribute the AllWeatherNight dataset, featuring large-scale high-quality nighttime images with diverse compositional degradations, synthesized using our introduced illumination-aware degradation generation. Moreover, we present ClearNight, a unified nighttime image restoration framework, which effectively removes complex degradations in one go. Specifically, ClearNight extracts Retinex-based dual priors and explicitly guides the network to focus on uneven illumination regions and intrinsic texture contents respectively, thereby enhancing restoration effectiveness in nighttime scenarios. In order to better represent the common and unique characters of multiple weather degradations, we introduce a weather-aware dynamic specific-commonality collaboration method, which identifies weather degradations and adaptively selects optimal candidate units associated with specific weather types. Our ClearNight achieves state-of-the-art performance on both synthetic and real-world images. Comprehensive ablation experiments validate the necessity of AllWeatherNight dataset as well as the effectiveness of ClearNight. Project page: https://henlyta.github.io/ClearNight/mainpage.html
Diverse Policies Recovering via Pointwise Mutual Information Weighted Imitation Learning
Oct 21, 2024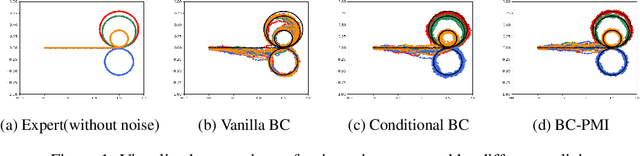
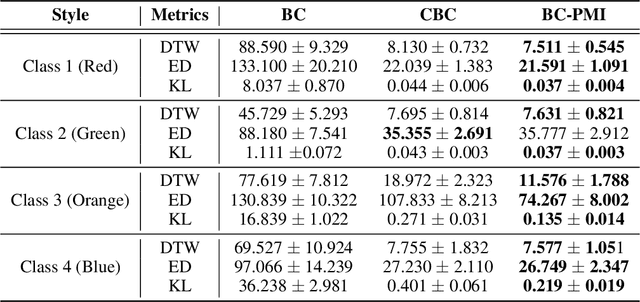
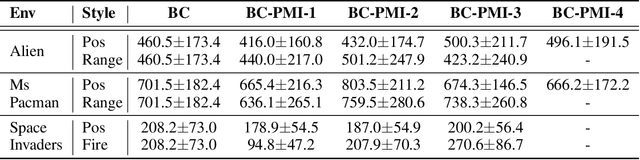
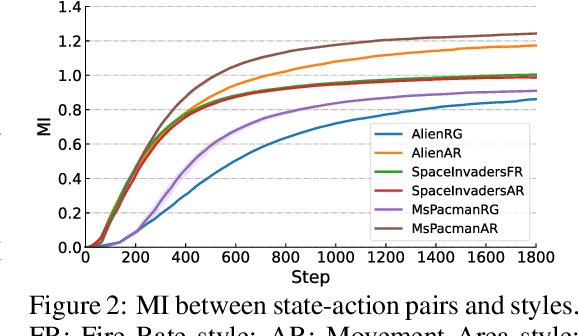
Recovering a spectrum of diverse policies from a set of expert trajectories is an important research topic in imitation learning. After determining a latent style for a trajectory, previous diverse policies recovering methods usually employ a vanilla behavioral cloning learning objective conditioned on the latent style, treating each state-action pair in the trajectory with equal importance. Based on an observation that in many scenarios, behavioral styles are often highly relevant with only a subset of state-action pairs, this paper presents a new principled method in diverse polices recovery. In particular, after inferring or assigning a latent style for a trajectory, we enhance the vanilla behavioral cloning by incorporating a weighting mechanism based on pointwise mutual information. This additional weighting reflects the significance of each state-action pair's contribution to learning the style, thus allowing our method to focus on state-action pairs most representative of that style. We provide theoretical justifications for our new objective, and extensive empirical evaluations confirm the effectiveness of our method in recovering diverse policies from expert data.
Robust Learning under Hybrid Noise
Jul 04, 2024Feature noise and label noise are ubiquitous in practical scenarios, which pose great challenges for training a robust machine learning model. Most previous approaches usually deal with only a single problem of either feature noise or label noise. However, in real-world applications, hybrid noise, which contains both feature noise and label noise, is very common due to the unreliable data collection and annotation processes. Although some results have been achieved by a few representation learning based attempts, this issue is still far from being addressed with promising performance and guaranteed theoretical analyses. To address the challenge, we propose a novel unified learning framework called "Feature and Label Recovery" (FLR) to combat the hybrid noise from the perspective of data recovery, where we concurrently reconstruct both the feature matrix and the label matrix of input data. Specifically, the clean feature matrix is discovered by the low-rank approximation, and the ground-truth label matrix is embedded based on the recovered features with a nuclear norm regularization. Meanwhile, the feature noise and label noise are characterized by their respective adaptive matrix norms to satisfy the corresponding maximum likelihood. As this framework leads to a non-convex optimization problem, we develop the non-convex Alternating Direction Method of Multipliers (ADMM) with the convergence guarantee to solve our learning objective. We also provide the theoretical analysis to show that the generalization error of FLR can be upper-bounded in the presence of hybrid noise. Experimental results on several typical benchmark datasets clearly demonstrate the superiority of our proposed method over the state-of-the-art robust learning approaches for various noises.
Enhance Reasoning for Large Language Models in the Game Werewolf
Feb 04, 2024This paper presents an innovative framework that integrates Large Language Models (LLMs) with an external Thinker module to enhance the reasoning capabilities of LLM-based agents. Unlike augmenting LLMs with prompt engineering, Thinker directly harnesses knowledge from databases and employs various optimization techniques. The framework forms a reasoning hierarchy where LLMs handle intuitive System-1 tasks such as natural language processing, while the Thinker focuses on cognitive System-2 tasks that require complex logical analysis and domain-specific knowledge. Our framework is presented using a 9-player Werewolf game that demands dual-system reasoning. We introduce a communication protocol between LLMs and the Thinker, and train the Thinker using data from 18800 human sessions and reinforcement learning. Experiments demonstrate the framework's effectiveness in deductive reasoning, speech generation, and online game evaluation. Additionally, we fine-tune a 6B LLM to surpass GPT4 when integrated with the Thinker. This paper also contributes the largest dataset for social deduction games to date.
Self-Supervised Learning for SAR ATR with a Knowledge-Guided Predictive Architecture
Nov 26, 2023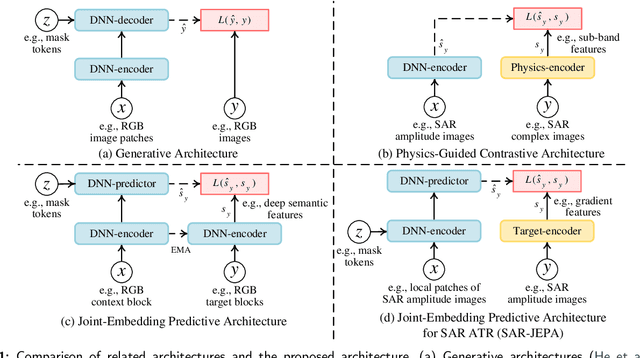
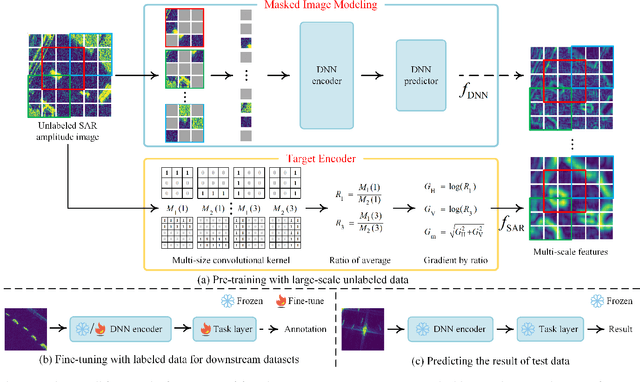

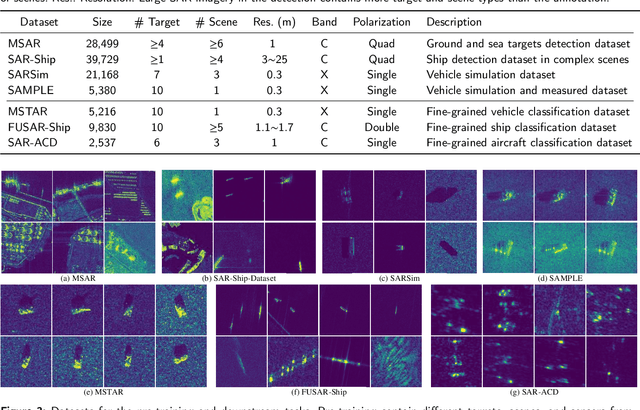
Recently, the emergence of a large number of Synthetic Aperture Radar (SAR) sensors and target datasets has made it possible to unify downstream tasks with self-supervised learning techniques, which can pave the way for building the foundation model in the SAR target recognition field. The major challenge of self-supervised learning for SAR target recognition lies in the generalizable representation learning in low data quality and noise.To address the aforementioned problem, we propose a knowledge-guided predictive architecture that uses local masked patches to predict the multiscale SAR feature representations of unseen context. The core of the proposed architecture lies in combining traditional SAR domain feature extraction with state-of-the-art scalable self-supervised learning for accurate generalized feature representations. The proposed framework is validated on various downstream datasets (MSTAR, FUSAR-Ship, SAR-ACD and SSDD), and can bring consistent performance improvement for SAR target recognition. The experimental results strongly demonstrate the unified performance improvement of the self-supervised learning technique for SAR target recognition across diverse targets, scenes and sensors.
Make Pixels Dance: High-Dynamic Video Generation
Nov 18, 2023Creating high-dynamic videos such as motion-rich actions and sophisticated visual effects poses a significant challenge in the field of artificial intelligence. Unfortunately, current state-of-the-art video generation methods, primarily focusing on text-to-video generation, tend to produce video clips with minimal motions despite maintaining high fidelity. We argue that relying solely on text instructions is insufficient and suboptimal for video generation. In this paper, we introduce PixelDance, a novel approach based on diffusion models that incorporates image instructions for both the first and last frames in conjunction with text instructions for video generation. Comprehensive experimental results demonstrate that PixelDance trained with public data exhibits significantly better proficiency in synthesizing videos with complex scenes and intricate motions, setting a new standard for video generation.
Act As You Wish: Fine-Grained Control of Motion Diffusion Model with Hierarchical Semantic Graphs
Nov 02, 2023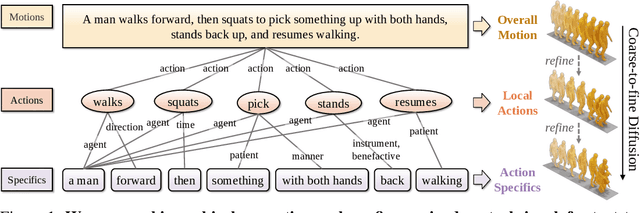

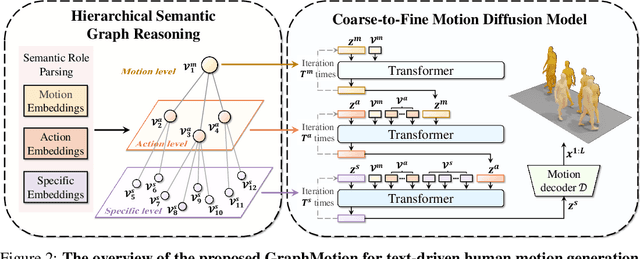
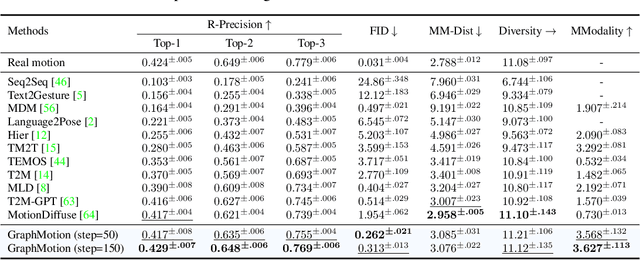
Most text-driven human motion generation methods employ sequential modeling approaches, e.g., transformer, to extract sentence-level text representations automatically and implicitly for human motion synthesis. However, these compact text representations may overemphasize the action names at the expense of other important properties and lack fine-grained details to guide the synthesis of subtly distinct motion. In this paper, we propose hierarchical semantic graphs for fine-grained control over motion generation. Specifically, we disentangle motion descriptions into hierarchical semantic graphs including three levels of motions, actions, and specifics. Such global-to-local structures facilitate a comprehensive understanding of motion description and fine-grained control of motion generation. Correspondingly, to leverage the coarse-to-fine topology of hierarchical semantic graphs, we decompose the text-to-motion diffusion process into three semantic levels, which correspond to capturing the overall motion, local actions, and action specifics. Extensive experiments on two benchmark human motion datasets, including HumanML3D and KIT, with superior performances, justify the efficacy of our method. More encouragingly, by modifying the edge weights of hierarchical semantic graphs, our method can continuously refine the generated motion, which may have a far-reaching impact on the community. Code and pre-training weights are available at https://github.com/jpthu17/GraphMotion.