 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025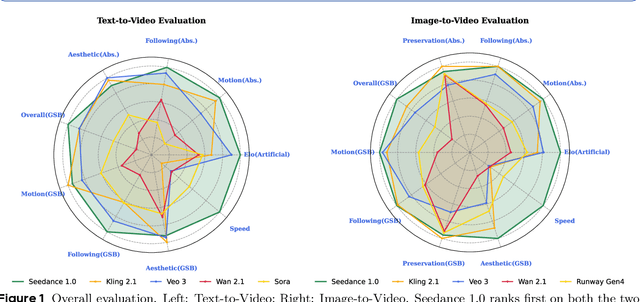
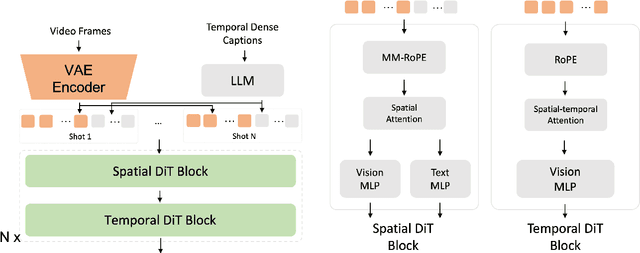
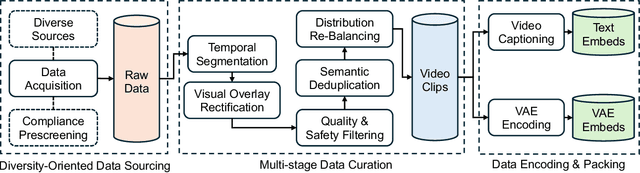
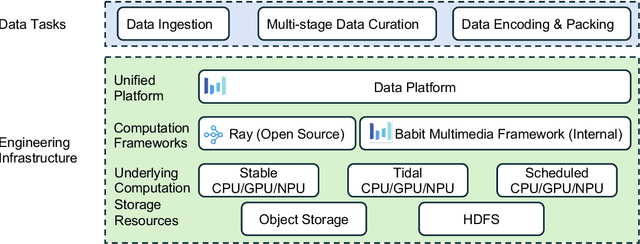
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Training-free Camera Control for Video Generation
Jun 14, 2024
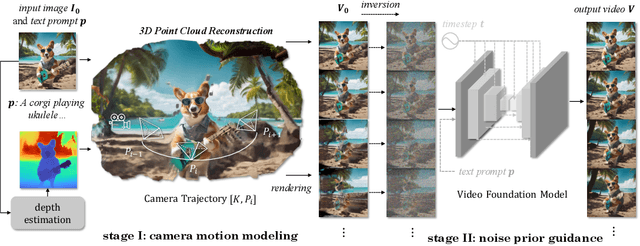
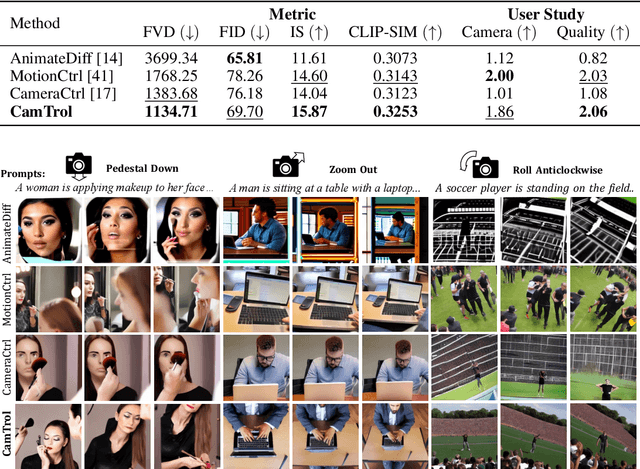
We propose a training-free and robust solution to offer camera movement control for off-the-shelf video diffusion models. Unlike previous work, our method does not require any supervised finetuning on camera-annotated datasets or self-supervised training via data augmentation. Instead, it can be plugged and played with most pretrained video diffusion models and generate camera controllable videos with a single image or text prompt as input. The inspiration of our work comes from the layout prior that intermediate latents hold towards generated results, thus rearranging noisy pixels in them will make output content reallocated as well. As camera move could also be seen as a kind of pixel rearrangement caused by perspective change, videos could be reorganized following specific camera motion if their noisy latents change accordingly. Established on this, we propose our method CamTrol, which enables robust camera control for video diffusion models. It is achieved by a two-stage process. First, we model image layout rearrangement through explicit camera movement in 3D point cloud space. Second, we generate videos with camera motion using layout prior of noisy latents formed by a series of rearranged images. Extensive experiments have demonstrated the robustness our method holds in controlling camera motion of generated videos. Furthermore, we show that our method can produce impressive results in generating 3D rotation videos with dynamic content. Project page at https://lifedecoder.github.io/CamTrol/.
Boximator: Generating Rich and Controllable Motions for Video Synthesis
Feb 02, 2024



Generating rich and controllable motion is a pivotal challenge in video synthesis. We propose Boximator, a new approach for fine-grained motion control. Boximator introduces two constraint types: hard box and soft box. Users select objects in the conditional frame using hard boxes and then use either type of boxes to roughly or rigorously define the object's position, shape, or motion path in future frames. Boximator functions as a plug-in for existing video diffusion models. Its training process preserves the base model's knowledge by freezing the original weights and training only the control module. To address training challenges, we introduce a novel self-tracking technique that greatly simplifies the learning of box-object correlations. Empirically, Boximator achieves state-of-the-art video quality (FVD) scores, improving on two base models, and further enhanced after incorporating box constraints. Its robust motion controllability is validated by drastic increases in the bounding box alignment metric. Human evaluation also shows that users favor Boximator generation results over the base model.
High-Fidelity Diffusion-based Image Editing
Jan 04, 2024
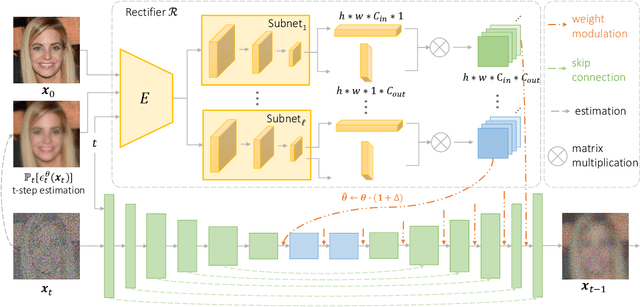

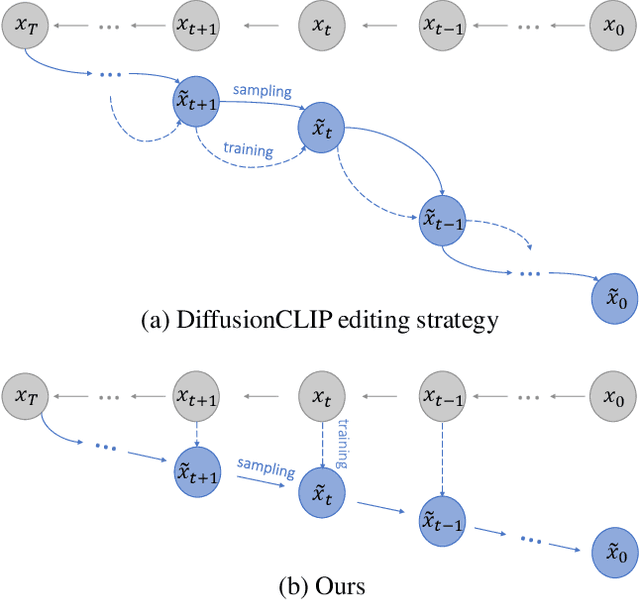
Diffusion models have attained remarkable success in the domains of image generation and editing. It is widely recognized that employing larger inversion and denoising steps in diffusion model leads to improved image reconstruction quality. However, the editing performance of diffusion models tends to be no more satisfactory even with increasing denoising steps. The deficiency in editing could be attributed to the conditional Markovian property of the editing process, where errors accumulate throughout denoising steps. To tackle this challenge, we first propose an innovative framework where a rectifier module is incorporated to modulate diffusion model weights with residual features, thereby providing compensatory information to bridge the fidelity gap. Furthermore, we introduce a novel learning paradigm aimed at minimizing error propagation during the editing process, which trains the editing procedure in a manner similar to denoising score-matching. Extensive experiments demonstrate that our proposed framework and training strategy achieve high-fidelity reconstruction and editing results across various levels of denoising steps, meanwhile exhibits exceptional performance in terms of both quantitative metric and qualitative assessments. Moreover, we explore our model's generalization through several applications like image-to-image translation and out-of-domain image editing.
Make Pixels Dance: High-Dynamic Video Generation
Nov 18, 2023Creating high-dynamic videos such as motion-rich actions and sophisticated visual effects poses a significant challenge in the field of artificial intelligence. Unfortunately, current state-of-the-art video generation methods, primarily focusing on text-to-video generation, tend to produce video clips with minimal motions despite maintaining high fidelity. We argue that relying solely on text instructions is insufficient and suboptimal for video generation. In this paper, we introduce PixelDance, a novel approach based on diffusion models that incorporates image instructions for both the first and last frames in conjunction with text instructions for video generation. Comprehensive experimental results demonstrate that PixelDance trained with public data exhibits significantly better proficiency in synthesizing videos with complex scenes and intricate motions, setting a new standard for video generation.
What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?
Jul 30, 2023Recent advancements in Large Language Models (LLMs) such as GPT4 have displayed exceptional multi-modal capabilities in following open-ended instructions given images. However, the performance of these models heavily relies on design choices such as network structures, training data, and training strategies, and these choices have not been extensively discussed in the literature, making it difficult to quantify progress in this field. To address this issue, this paper presents a systematic and comprehensive study, quantitatively and qualitatively, on training such models. We implement over 20 variants with controlled settings. Concretely, for network structures, we compare different LLM backbones and model designs. For training data, we investigate the impact of data and sampling strategies. For instructions, we explore the influence of diversified prompts on the instruction-following ability of the trained models. For benchmarks, we contribute the first, to our best knowledge, comprehensive evaluation set including both image and video tasks through crowd-sourcing. Based on our findings, we present Lynx, which performs the most accurate multi-modal understanding while keeping the best multi-modal generation ability compared to existing open-sourced GPT4-style models.
MRVM-NeRF: Mask-Based Pretraining for Neural Radiance Fields
Apr 11, 2023



Most Neural Radiance Fields (NeRFs) have poor generalization ability, limiting their application when representing multiple scenes by a single model. To ameliorate this problem, existing methods simply condition NeRF models on image features, lacking the global understanding and modeling of the entire 3D scene. Inspired by the significant success of mask-based modeling in other research fields, we propose a masked ray and view modeling method for generalizable NeRF (MRVM-NeRF), the first attempt to incorporate mask-based pretraining into 3D implicit representations. Specifically, considering that the core of NeRFs lies in modeling 3D representations along the rays and across the views, we randomly mask a proportion of sampled points along the ray at fine stage by discarding partial information obtained from multi-viewpoints, targeting at predicting the corresponding features produced in the coarse branch. In this way, the learned prior knowledge of 3D scenes during pretraining helps the model generalize better to novel scenarios after finetuning. Extensive experiments demonstrate the superiority of our proposed MRVM-NeRF under various synthetic and real-world settings, both qualitatively and quantitatively. Our empirical studies reveal the effectiveness of our proposed innovative MRVM which is specifically designed for NeRF models.
Semantic-aware Message Broadcasting for Efficient Unsupervised Domain Adaptation
Dec 06, 2022



Vision transformer has demonstrated great potential in abundant vision tasks. However, it also inevitably suffers from poor generalization capability when the distribution shift occurs in testing (i.e., out-of-distribution data). To mitigate this issue, we propose a novel method, Semantic-aware Message Broadcasting (SAMB), which enables more informative and flexible feature alignment for unsupervised domain adaptation (UDA). Particularly, we study the attention module in the vision transformer and notice that the alignment space using one global class token lacks enough flexibility, where it interacts information with all image tokens in the same manner but ignores the rich semantics of different regions. In this paper, we aim to improve the richness of the alignment features by enabling semantic-aware adaptive message broadcasting. Particularly, we introduce a group of learned group tokens as nodes to aggregate the global information from all image tokens, but encourage different group tokens to adaptively focus on the message broadcasting to different semantic regions. In this way, our message broadcasting encourages the group tokens to learn more informative and diverse information for effective domain alignment. Moreover, we systematically study the effects of adversarial-based feature alignment (ADA) and pseudo-label based self-training (PST) on UDA. We find that one simple two-stage training strategy with the cooperation of ADA and PST can further improve the adaptation capability of the vision transformer. Extensive experiments on DomainNet, OfficeHome, and VisDA-2017 demonstrate the effectiveness of our methods for UDA.
ActiveMLP: An MLP-like Architecture with Active Token Mixer
Mar 11, 2022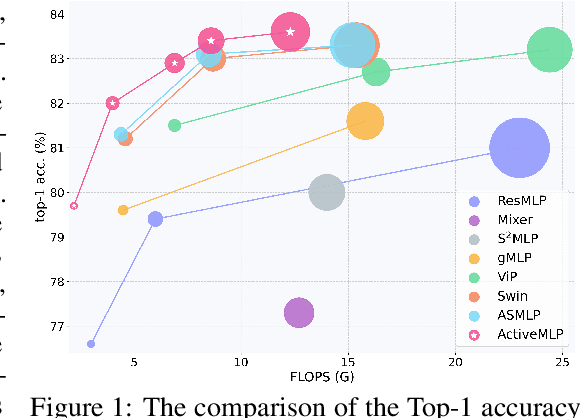

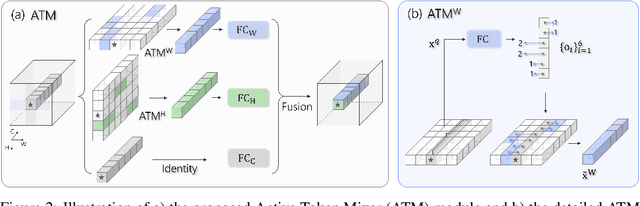
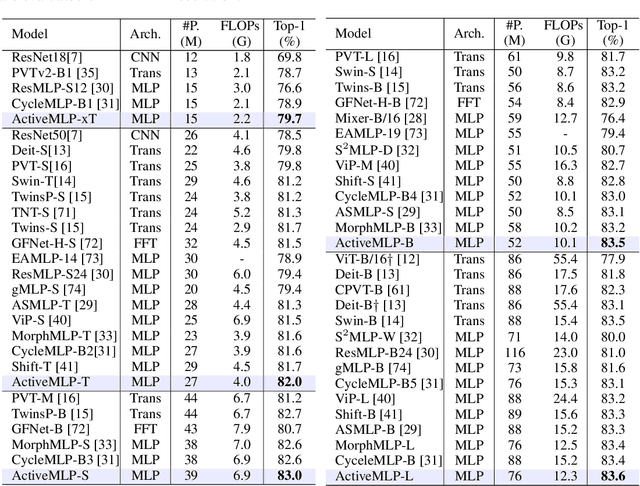
This paper presents ActiveMLP, a general MLP-like backbone for computer vision. The three existing dominant network families, i.e., CNNs, Transformers and MLPs, differ from each other mainly in the ways to fuse contextual information into a given token, leaving the design of more effective token-mixing mechanisms at the core of backbone architecture development. In ActiveMLP, we propose an innovative token-mixer, dubbed Active Token Mixer (ATM), to actively incorporate contextual information from other tokens in the global scope into the given one. This fundamental operator actively predicts where to capture useful contexts and learns how to fuse the captured contexts with the original information of the given token at channel levels. In this way, the spatial range of token-mixing is expanded and the way of token-mixing is reformed. With this design, ActiveMLP is endowed with the merits of global receptive fields and more flexible content-adaptive information fusion. Extensive experiments demonstrate that ActiveMLP is generally applicable and comprehensively surpasses different families of SOTA vision backbones by a clear margin on a broad range of vision tasks, including visual recognition and dense prediction tasks. The code and models will be available at https://github.com/microsoft/ActiveMLP.