 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning or Memorization? Direction-Aware Diversity Exploration in LLM Reinforcement Learning
Jun 09, 2026Reinforcement learning has become a key paradigm for eliciting reasoning abilities in large language models, where exploration is crucial for discovering effective solution trajectories. Existing exploration methods typically encourage diversity in semantic or gradient spaces, without distinguishing what drives this diversity. A trajectory may appear novel because it follows a new reasoning process, or because it varies memorized patterns and shortcuts. Rewarding both cases equally may steer exploration toward memorization rather than genuine reasoning improvement. In this paper, we propose DiRL, a Direction-Aware Reinforcement Learning framework that anchors exploration to an internal reasoning-memorization direction of the policy. Specifically, DiRL extracts this direction from model representations, constructs direction-weighted gradient features to characterize rollout updates, and shapes rewards to amplify reasoning-aligned exploration while suppressing memorization-aligned variations. DiRL integrates seamlessly into standard Group Relative Policy Optimization (GRPO). Extensive experiments on mathematical and general reasoning benchmarks demonstrate the effectiveness of DiRL, showing significant improvements over various existing exploration methods.
TS-Diff: Two-Stage Diffusion Model for Low-Light RAW Image Enhancement
May 07, 2025This paper presents a novel Two-Stage Diffusion Model (TS-Diff) for enhancing extremely low-light RAW images. In the pre-training stage, TS-Diff synthesizes noisy images by constructing multiple virtual cameras based on a noise space. Camera Feature Integration (CFI) modules are then designed to enable the model to learn generalizable features across diverse virtual cameras. During the aligning stage, CFIs are averaged to create a target-specific CFI$^T$, which is fine-tuned using a small amount of real RAW data to adapt to the noise characteristics of specific cameras. A structural reparameterization technique further simplifies CFI$^T$ for efficient deployment. To address color shifts during the diffusion process, a color corrector is introduced to ensure color consistency by dynamically adjusting global color distributions. Additionally, a novel dataset, QID, is constructed, featuring quantifiable illumination levels and a wide dynamic range, providing a comprehensive benchmark for training and evaluation under extreme low-light conditions. Experimental results demonstrate that TS-Diff achieves state-of-the-art performance on multiple datasets, including QID, SID, and ELD, excelling in denoising, generalization, and color consistency across various cameras and illumination levels. These findings highlight the robustness and versatility of TS-Diff, making it a practical solution for low-light imaging applications. Source codes and models are available at https://github.com/CircccleK/TS-Diff
FairTP: A Prolonged Fairness Framework for Traffic Prediction
Dec 18, 2024Traffic prediction plays a crucial role in intelligent transportation systems. Existing approaches primarily focus on improving overall accuracy, often neglecting a critical issue: whether predictive models lead to biased decisions by transportation authorities. In practice, the uneven deployment of traffic sensors across urban areas results in imbalanced data, causing prediction models to perform poorly in certain regions and leading to unfair decision-making. This imbalance ultimately harms the equity and quality of life for residents. Moreover, current fairness-aware machine learning models only ensure fairness at specific time points, failing to maintain fairness over extended periods. As traffic conditions change, such static fairness approaches become ineffective. To address this gap, we propose FairTP, a framework for prolonged fair traffic prediction. We introduce two new fairness definitions tailored for dynamic traffic scenarios. Fairness in traffic prediction is not static; it varies over time and across regions. Each sensor or urban area can alternate between two states: "sacrifice" (low prediction accuracy) and "benefit" (high prediction accuracy). Prolonged fairness is achieved when the overall states of sensors remain similar over a given period. We define two types of fairness: region-based static fairness and sensor-based dynamic fairness. To implement this, FairTP incorporates a state identification module to classify sensors' states as either "sacrifice" or "benefit," enabling prolonged fairness-aware predictions. Additionally, we introduce a state-guided balanced sampling strategy to further enhance fairness, addressing performance disparities among regions with uneven sensor distributions. Extensive experiments on two real-world datasets demonstrate that FairTP significantly improves prediction fairness while minimizing accuracy degradation.
Bayes-enhanced Multi-view Attention Networks for Robust POI Recommendation
Nov 01, 2023



POI recommendation is practically important to facilitate various Location-Based Social Network services, and has attracted rising research attention recently. Existing works generally assume the available POI check-ins reported by users are the ground-truth depiction of user behaviors. However, in real application scenarios, the check-in data can be rather unreliable due to both subjective and objective causes including positioning error and user privacy concerns, leading to significant negative impacts on the performance of the POI recommendation. To this end, we investigate a novel problem of robust POI recommendation by considering the uncertainty factors of the user check-ins, and proposes a Bayes-enhanced Multi-view Attention Network. Specifically, we construct personal POI transition graph, the semantic-based POI graph and distance-based POI graph to comprehensively model the dependencies among the POIs. As the personal POI transition graph is usually sparse and sensitive to noise, we design a Bayes-enhanced spatial dependency learning module for data augmentation from the local view. A Bayesian posterior guided graph augmentation approach is adopted to generate a new graph with collaborative signals to increase the data diversity. Then both the original and the augmented graphs are used for POI representation learning to counteract the data uncertainty issue. Next, the POI representations of the three view graphs are input into the proposed multi-view attention-based user preference learning module. By incorporating the semantic and distance correlations of POIs, the user preference can be effectively refined and finally robust recommendation results are achieved. The results of extensive experiments show that BayMAN significantly outperforms the state-of-the-art methods in POI recommendation when the available check-ins are incomplete and noisy.
What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?
Jul 30, 2023Recent advancements in Large Language Models (LLMs) such as GPT4 have displayed exceptional multi-modal capabilities in following open-ended instructions given images. However, the performance of these models heavily relies on design choices such as network structures, training data, and training strategies, and these choices have not been extensively discussed in the literature, making it difficult to quantify progress in this field. To address this issue, this paper presents a systematic and comprehensive study, quantitatively and qualitatively, on training such models. We implement over 20 variants with controlled settings. Concretely, for network structures, we compare different LLM backbones and model designs. For training data, we investigate the impact of data and sampling strategies. For instructions, we explore the influence of diversified prompts on the instruction-following ability of the trained models. For benchmarks, we contribute the first, to our best knowledge, comprehensive evaluation set including both image and video tasks through crowd-sourcing. Based on our findings, we present Lynx, which performs the most accurate multi-modal understanding while keeping the best multi-modal generation ability compared to existing open-sourced GPT4-style models.
Incorporating External Knowledge into Machine Reading for Generative Question Answering
Sep 06, 2019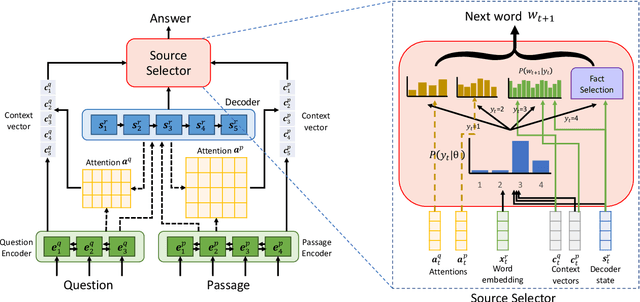
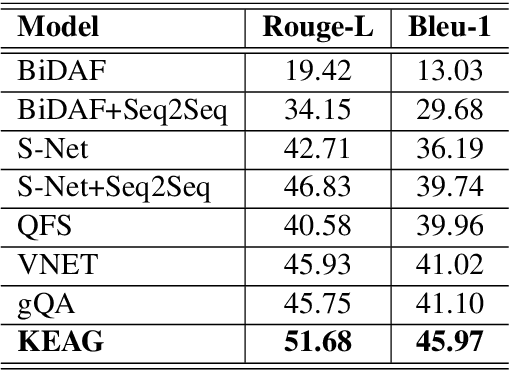
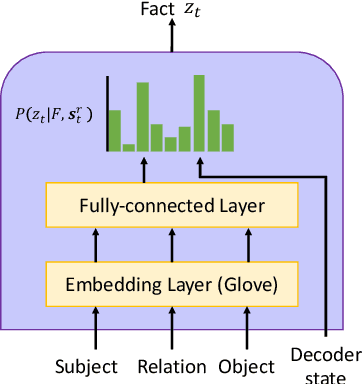
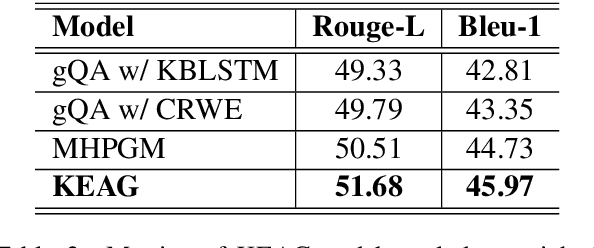
Commonsense and background knowledge is required for a QA model to answer many nontrivial questions. Different from existing work on knowledge-aware QA, we focus on a more challenging task of leveraging external knowledge to generate answers in natural language for a given question with context. In this paper, we propose a new neural model, Knowledge-Enriched Answer Generator (KEAG), which is able to compose a natural answer by exploiting and aggregating evidence from all four information sources available: question, passage, vocabulary and knowledge. During the process of answer generation, KEAG adaptively determines when to utilize symbolic knowledge and which fact from the knowledge is useful. This allows the model to exploit external knowledge that is not explicitly stated in the given text, but that is relevant for generating an answer. The empirical study on public benchmark of answer generation demonstrates that KEAG improves answer quality over models without knowledge and existing knowledge-aware models, confirming its effectiveness in leveraging knowledge.
Incorporating Relation Knowledge into Commonsense Reading Comprehension with Multi-task Learning
Sep 05, 2019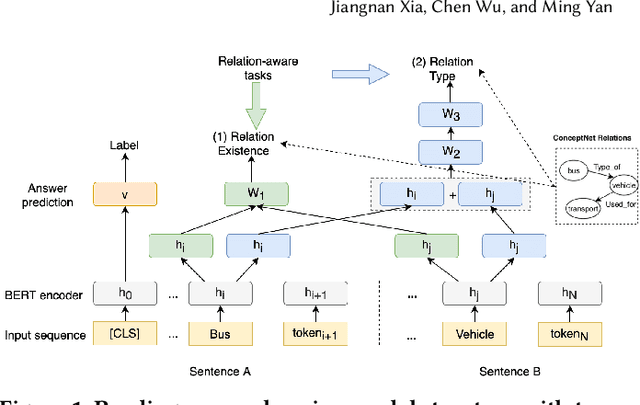

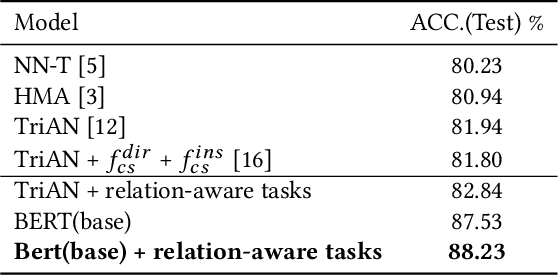
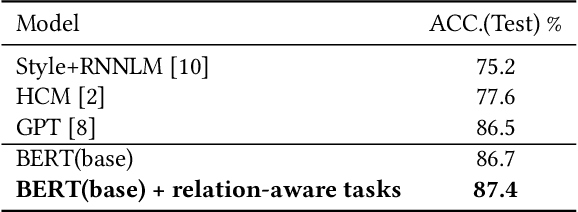
This paper focuses on how to take advantage of external relational knowledge to improve machine reading comprehension (MRC) with multi-task learning. Most of the traditional methods in MRC assume that the knowledge used to get the correct answer generally exists in the given documents. However, in real-world task, part of knowledge may not be mentioned and machines should be equipped with the ability to leverage external knowledge. In this paper, we integrate relational knowledge into MRC model for commonsense reasoning. Specifically, based on a pre-trained language model (LM). We design two auxiliary relation-aware tasks to predict if there exists any commonsense relation and what is the relation type between two words, in order to better model the interactions between document and candidate answer option. We conduct experiments on two multi-choice benchmark datasets: the SemEval-2018 Task 11 and the Cloze Story Test. The experimental results demonstrate the effectiveness of the proposed method, which achieves superior performance compared with the comparable baselines on both datasets.
A Deep Cascade Model for Multi-Document Reading Comprehension
Nov 28, 2018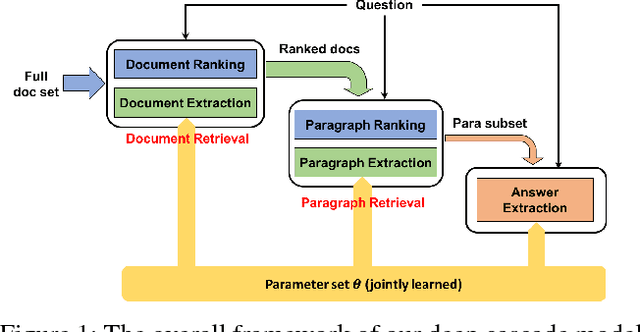

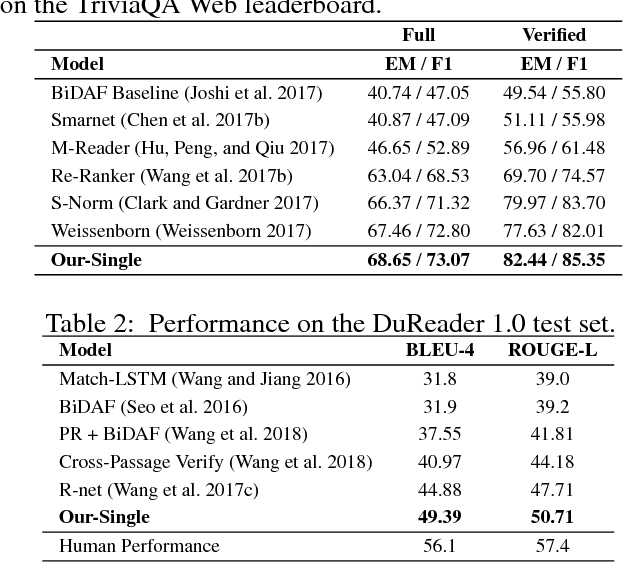
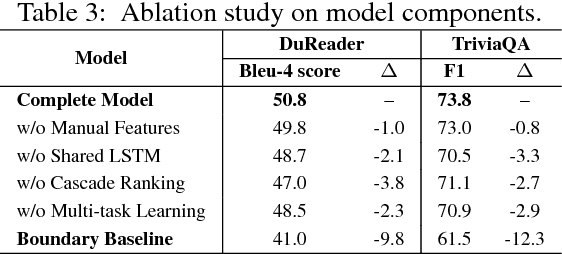
A fundamental trade-off between effectiveness and efficiency needs to be balanced when designing an online question answering system. Effectiveness comes from sophisticated functions such as extractive machine reading comprehension (MRC), while efficiency is obtained from improvements in preliminary retrieval components such as candidate document selection and paragraph ranking. Given the complexity of the real-world multi-document MRC scenario, it is difficult to jointly optimize both in an end-to-end system. To address this problem, we develop a novel deep cascade learning model, which progressively evolves from the document-level and paragraph-level ranking of candidate texts to more precise answer extraction with machine reading comprehension. Specifically, irrelevant documents and paragraphs are first filtered out with simple functions for efficiency consideration. Then we jointly train three modules on the remaining texts for better tracking the answer: the document extraction, the paragraph extraction and the answer extraction. Experiment results show that the proposed method outperforms the previous state-of-the-art methods on two large-scale multi-document benchmark datasets, i.e., TriviaQA and DuReader. In addition, our online system can stably serve typical scenarios with millions of daily requests in less than 50ms.