 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
Jan 05, 2026Despite significant progress, multimodal large language models continue to struggle with visual mathematical problem solving. Some recent works recognize that visual perception is a bottleneck in visual mathematical reasoning, but their solutions are limited to improving the extraction and interpretation of visual inputs. Notably, they all ignore the key issue of whether the extracted visual cues are faithfully integrated and properly utilized in subsequent reasoning. Motivated by this, we present CogFlow, a novel cognitive-inspired three-stage framework that incorporates a knowledge internalization stage, explicitly simulating the hierarchical flow of human reasoning: perception$\Rightarrow$internalization$\Rightarrow$reasoning. Inline with this hierarchical flow, we holistically enhance all its stages. We devise Synergistic Visual Rewards to boost perception capabilities in parametric and semantic spaces, jointly improving visual information extraction from symbols and diagrams. To guarantee faithful integration of extracted visual cues into subsequent reasoning, we introduce a Knowledge Internalization Reward model in the internalization stage, bridging perception and reasoning. Moreover, we design a Visual-Gated Policy Optimization algorithm to further enforce the reasoning is grounded with the visual knowledge, preventing models seeking shortcuts that appear coherent but are visually ungrounded reasoning chains. Moreover, we contribute a new dataset MathCog for model training, which contains samples with over 120K high-quality perception-reasoning aligned annotations. Comprehensive experiments and analysis on commonly used visual mathematical reasoning benchmarks validate the superiority of the proposed CogFlow.
Clear Nights Ahead: Towards Multi-Weather Nighttime Image Restoration
May 22, 2025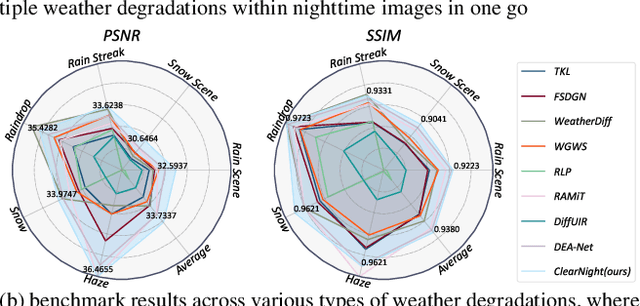
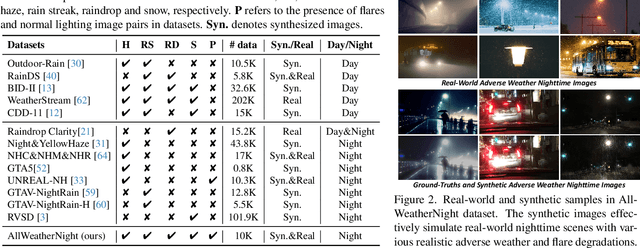

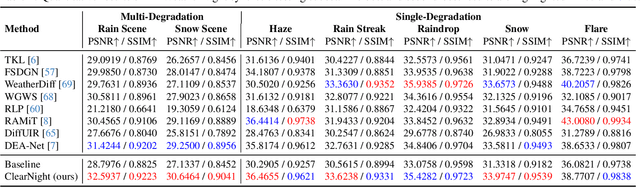
Restoring nighttime images affected by multiple adverse weather conditions is a practical yet under-explored research problem, as multiple weather conditions often coexist in the real world alongside various lighting effects at night. This paper first explores the challenging multi-weather nighttime image restoration task, where various types of weather degradations are intertwined with flare effects. To support the research, we contribute the AllWeatherNight dataset, featuring large-scale high-quality nighttime images with diverse compositional degradations, synthesized using our introduced illumination-aware degradation generation. Moreover, we present ClearNight, a unified nighttime image restoration framework, which effectively removes complex degradations in one go. Specifically, ClearNight extracts Retinex-based dual priors and explicitly guides the network to focus on uneven illumination regions and intrinsic texture contents respectively, thereby enhancing restoration effectiveness in nighttime scenarios. In order to better represent the common and unique characters of multiple weather degradations, we introduce a weather-aware dynamic specific-commonality collaboration method, which identifies weather degradations and adaptively selects optimal candidate units associated with specific weather types. Our ClearNight achieves state-of-the-art performance on both synthetic and real-world images. Comprehensive ablation experiments validate the necessity of AllWeatherNight dataset as well as the effectiveness of ClearNight. Project page: https://henlyta.github.io/ClearNight/mainpage.html
MathFlow: Enhancing the Perceptual Flow of MLLMs for Visual Mathematical Problems
Mar 19, 2025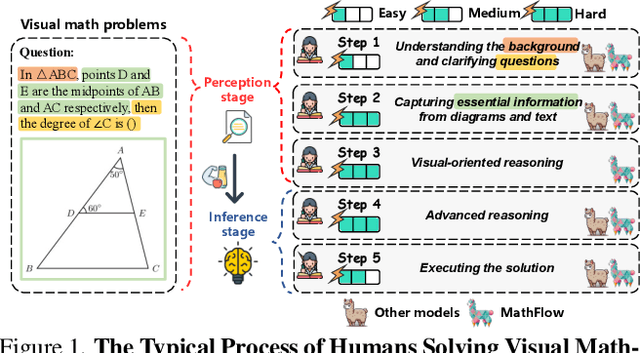
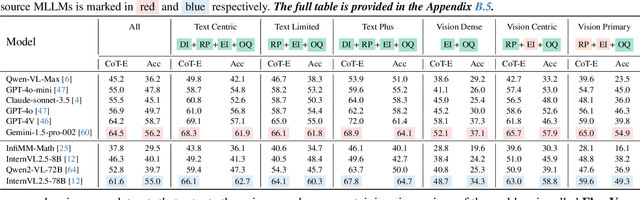
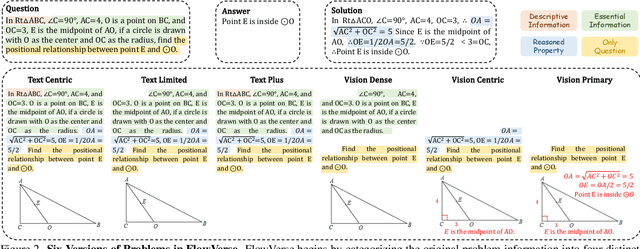
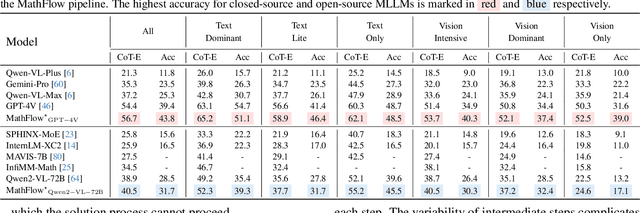
Despite impressive performance across diverse tasks, Multimodal Large Language Models (MLLMs) have yet to fully demonstrate their potential in visual mathematical problem-solving, particularly in accurately perceiving and interpreting diagrams. Inspired by typical processes of humans, we hypothesize that the perception capabilities to extract meaningful information from diagrams is crucial, as it directly impacts subsequent inference processes. To validate this hypothesis, we developed FlowVerse, a comprehensive benchmark that categorizes all information used during problem-solving into four components, which are then combined into six problem versions for evaluation. Our preliminary results on FlowVerse reveal that existing MLLMs exhibit substantial limitations when extracting essential information and reasoned property from diagrams and performing complex reasoning based on these visual inputs. In response, we introduce MathFlow, a modular problem-solving pipeline that decouples perception and inference into distinct stages, thereby optimizing each independently. Given the perceptual limitations observed in current MLLMs, we trained MathFlow-P-7B as a dedicated perception model. Experimental results indicate that MathFlow-P-7B yields substantial performance gains when integrated with various closed-source and open-source inference models. This demonstrates the effectiveness of the MathFlow pipeline and its compatibility to diverse inference frameworks. The FlowVerse benchmark and code are available at https://github.com/MathFlow-zju/MathFlow.
MC-Bench: A Benchmark for Multi-Context Visual Grounding in the Era of MLLMs
Oct 16, 2024



While multimodal large language models (MLLMs) have demonstrated extraordinary vision-language understanding capabilities and shown potential to serve as general-purpose assistants, their abilities to solve instance-level visual-language problems beyond a single image warrant further exploration. In order to assess these unproven abilities of MLLMs, this paper proposes a new visual grounding task called multi-context visual grounding, which aims to localize instances of interest across multiple images based on open-ended text prompts. To facilitate this research, we meticulously construct a new dataset MC-Bench for benchmarking the visual grounding capabilities of MLLMs. MC-Bench features 2K high-quality and manually annotated samples, consisting of instance-level labeled image pairs and corresponding text prompts that indicate the target instances in the images. In total, there are three distinct styles of text prompts, covering 20 practical skills. We benchmark over 20 state-of-the-art MLLMs and foundation models with potential multi-context visual grounding capabilities. Our evaluation reveals a non-trivial performance gap between existing MLLMs and humans across all metrics. We also observe that existing MLLMs typically outperform foundation models without LLMs only on image-level metrics, and the specialist MLLMs trained on single images often struggle to generalize to multi-image scenarios. Moreover, a simple stepwise baseline integrating advanced MLLM and a detector can significantly surpass prior end-to-end MLLMs. We hope our MC-Bench and empirical findings can encourage the research community to further explore and enhance the untapped potentials of MLLMs in instance-level tasks, particularly in multi-image contexts. Project page: https://xuyunqiu.github.io/MC-Bench/.
Continual Learning for Temporal-Sensitive Question Answering
Jul 17, 2024



In this study, we explore an emerging research area of Continual Learning for Temporal Sensitive Question Answering (CLTSQA). Previous research has primarily focused on Temporal Sensitive Question Answering (TSQA), often overlooking the unpredictable nature of future events. In real-world applications, it's crucial for models to continually acquire knowledge over time, rather than relying on a static, complete dataset. Our paper investigates strategies that enable models to adapt to the ever-evolving information landscape, thereby addressing the challenges inherent in CLTSQA. To support our research, we first create a novel dataset, divided into five subsets, designed specifically for various stages of continual learning. We then propose a training framework for CLTSQA that integrates temporal memory replay and temporal contrastive learning. Our experimental results highlight two significant insights: First, the CLTSQA task introduces unique challenges for existing models. Second, our proposed framework effectively navigates these challenges, resulting in improved performance.
Manifold-based Incomplete Multi-view Clustering via Bi-Consistency Guidance
May 16, 2024Incomplete multi-view clustering primarily focuses on dividing unlabeled data into corresponding categories with missing instances, and has received intensive attention due to its superiority in real applications. Considering the influence of incomplete data, the existing methods mostly attempt to recover data by adding extra terms. However, for the unsupervised methods, a simple recovery strategy will cause errors and outlying value accumulations, which will affect the performance of the methods. Broadly, the previous methods have not taken the effectiveness of recovered instances into consideration, or cannot flexibly balance the discrepancies between recovered data and original data. To address these problems, we propose a novel method termed Manifold-based Incomplete Multi-view clustering via Bi-consistency guidance (MIMB), which flexibly recovers incomplete data among various views, and attempts to achieve biconsistency guidance via reverse regularization. In particular, MIMB adds reconstruction terms to representation learning by recovering missing instances, which dynamically examines the latent consensus representation. Moreover, to preserve the consistency information among multiple views, MIMB implements a biconsistency guidance strategy with reverse regularization of the consensus representation and proposes a manifold embedding measure for exploring the hidden structure of the recovered data. Notably, MIMB aims to balance the importance of different views, and introduces an adaptive weight term for each view. Finally, an optimization algorithm with an alternating iteration optimization strategy is designed for final clustering. Extensive experimental results on 6 benchmark datasets are provided to confirm that MIMB can significantly obtain superior results as compared with several state-of-the-art baselines.
Generalization in Text-based Games via Hierarchical Reinforcement Learning
Sep 21, 2021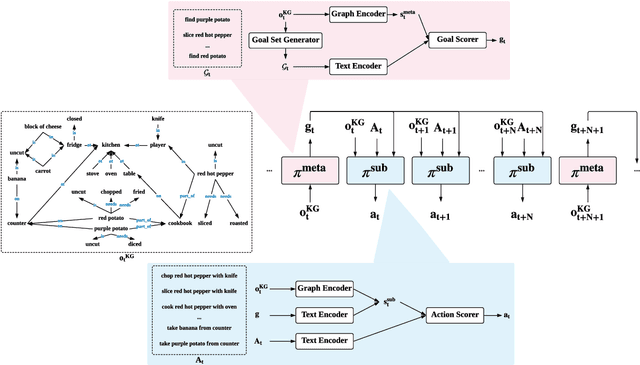
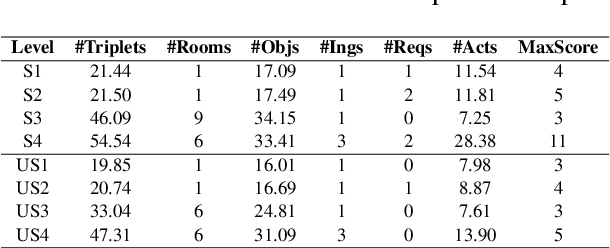
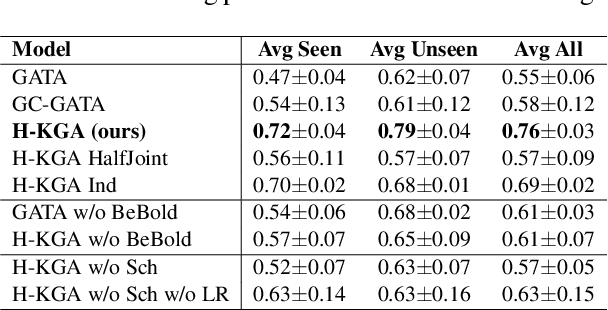
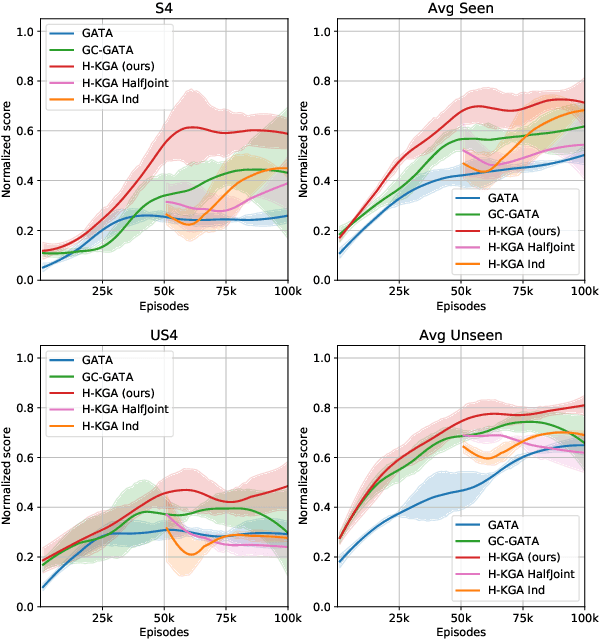
Deep reinforcement learning provides a promising approach for text-based games in studying natural language communication between humans and artificial agents. However, the generalization still remains a big challenge as the agents depend critically on the complexity and variety of training tasks. In this paper, we address this problem by introducing a hierarchical framework built upon the knowledge graph-based RL agent. In the high level, a meta-policy is executed to decompose the whole game into a set of subtasks specified by textual goals, and select one of them based on the KG. Then a sub-policy in the low level is executed to conduct goal-conditioned reinforcement learning. We carry out experiments on games with various difficulty levels and show that the proposed method enjoys favorable generalizability.
Deep Reinforcement Learning with Stacked Hierarchical Attention for Text-based Games
Oct 22, 2020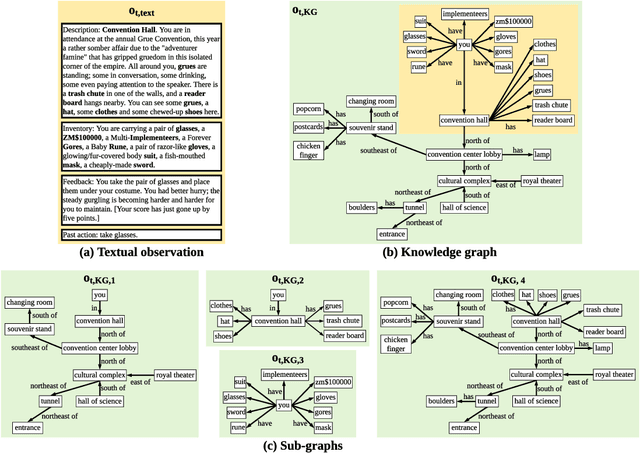
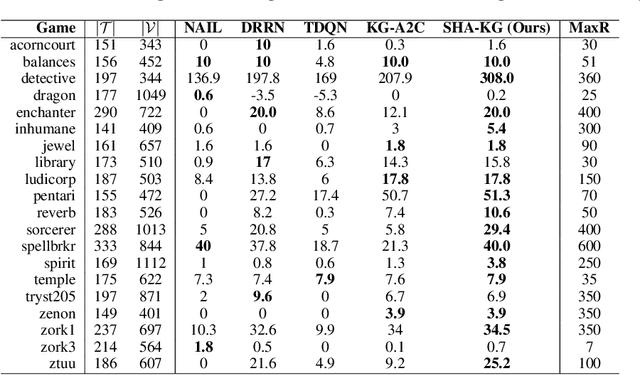
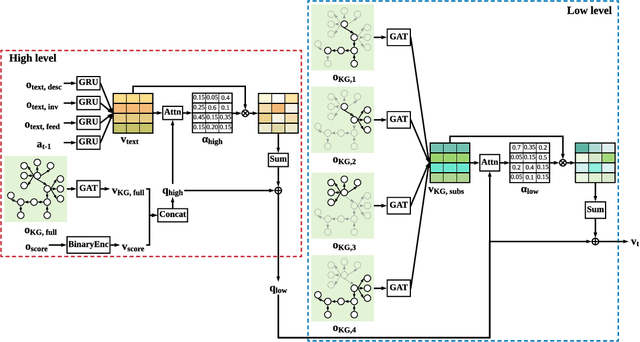

We study reinforcement learning (RL) for text-based games, which are interactive simulations in the context of natural language. While different methods have been developed to represent the environment information and language actions, existing RL agents are not empowered with any reasoning capabilities to deal with textual games. In this work, we aim to conduct explicit reasoning with knowledge graphs for decision making, so that the actions of an agent are generated and supported by an interpretable inference procedure. We propose a stacked hierarchical attention mechanism to construct an explicit representation of the reasoning process by exploiting the structure of the knowledge graph. We extensively evaluate our method on a number of man-made benchmark games, and the experimental results demonstrate that our method performs better than existing text-based agents.
Self-Correction for Human Parsing
Oct 22, 2019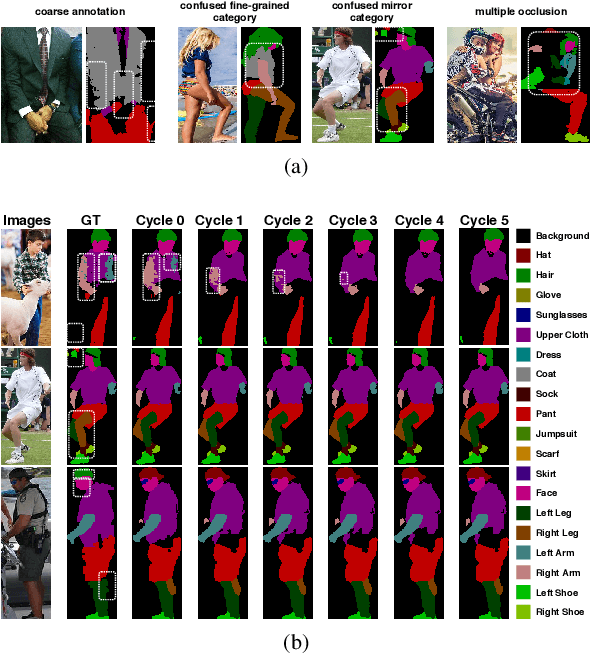
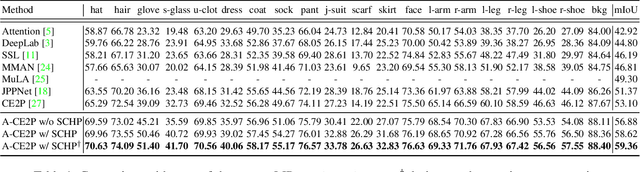
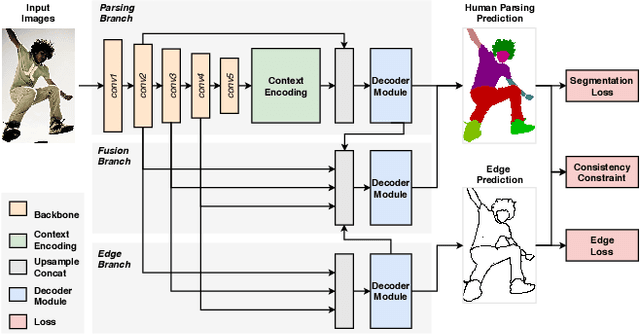
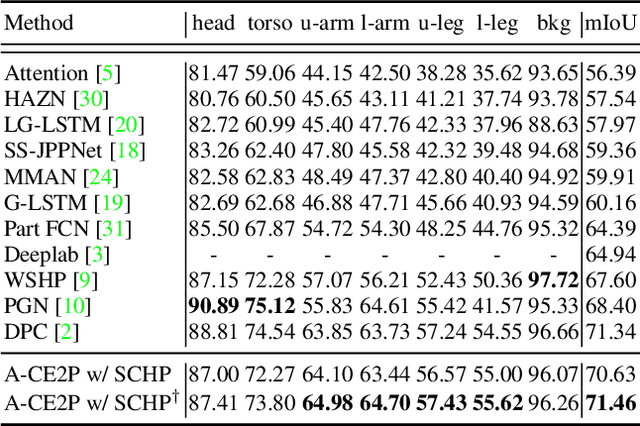
Labeling pixel-level masks for fine-grained semantic segmentation tasks, e.g. human parsing, remains a challenging task. The ambiguous boundary between different semantic parts and those categories with similar appearance usually are confusing, leading to unexpected noises in ground truth masks. To tackle the problem of learning with label noises, this work introduces a purification strategy, called Self-Correction for Human Parsing (SCHP), to progressively promote the reliability of the supervised labels as well as the learned models. In particular, starting from a model trained with inaccurate annotations as initialization, we design a cyclically learning scheduler to infer more reliable pseudo-masks by iteratively aggregating the current learned model with the former optimal one in an online manner. Besides, those correspondingly corrected labels can in turn to further boost the model performance. In this way, the models and the labels will reciprocally become more robust and accurate during the self-correction learning cycles. Benefiting from the superiority of SCHP, we achieve the best performance on two popular single-person human parsing benchmarks, including LIP and Pascal-Person-Part datasets. Our overall system ranks 1st in CVPR2019 LIP Challenge. Code is available at https://github.com/PeikeLi/Self-Correction-Human-Parsing.