 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distributed Semantic Pruning for Robust Semi-Supervised Learning
May 30, 2023Recent advances in robust semi-supervised learning (SSL) typically filter out-of-distribution (OOD) information at the sample level. We argue that an overlooked problem of robust SSL is its corrupted information on semantic level, practically limiting the development of the field. In this paper, we take an initial step to explore and propose a unified framework termed OOD Semantic Pruning (OSP), which aims at pruning OOD semantics out from in-distribution (ID) features. Specifically, (i) we propose an aliasing OOD matching module to pair each ID sample with an OOD sample with semantic overlap. (ii) We design a soft orthogonality regularization, which first transforms each ID feature by suppressing its semantic component that is collinear with paired OOD sample. It then forces the predictions before and after soft orthogonality decomposition to be consistent. Being practically simple, our method shows a strong performance in OOD detection and ID classification on challenging benchmarks. In particular, OSP surpasses the previous state-of-the-art by 13.7% on accuracy for ID classification and 5.9% on AUROC for OOD detection on TinyImageNet dataset. The source codes are publicly available at https://github.com/rain305f/OSP.
Position Embedding Needs an Independent Layer Normalization
Dec 22, 2022



The Position Embedding (PE) is critical for Vision Transformers (VTs) due to the permutation-invariance of self-attention operation. By analyzing the input and output of each encoder layer in VTs using reparameterization and visualization, we find that the default PE joining method (simply adding the PE and patch embedding together) operates the same affine transformation to token embedding and PE, which limits the expressiveness of PE and hence constrains the performance of VTs. To overcome this limitation, we propose a simple, effective, and robust method. Specifically, we provide two independent layer normalizations for token embeddings and PE for each layer, and add them together as the input of each layer's Muti-Head Self-Attention module. Since the method allows the model to adaptively adjust the information of PE for different layers, we name it as Layer-adaptive Position Embedding, abbreviated as LaPE. Extensive experiments demonstrate that LaPE can improve various VTs with different types of PE and make VTs robust to PE types. For example, LaPE improves 0.94% accuracy for ViT-Lite on Cifar10, 0.98% for CCT on Cifar100, and 1.72% for DeiT on ImageNet-1K, which is remarkable considering the negligible extra parameters, memory and computational cost brought by LaPE. The code is publicly available at https://github.com/Ingrid725/LaPE.
Expectation-Maximization Contrastive Learning for Compact Video-and-Language Representations
Nov 21, 2022Most video-and-language representation learning approaches employ contrastive learning, e.g., CLIP, to project the video and text features into a common latent space according to the semantic similarities of text-video pairs. However, such learned shared latent spaces are not often optimal, and the modality gap between visual and textual representation can not be fully eliminated. In this paper, we propose Expectation-Maximization Contrastive Learning (EMCL) to learn compact video-and-language representations. Specifically, we use the Expectation-Maximization algorithm to find a compact set of bases for the latent space, where the features could be concisely represented as the linear combinations of these bases. Such feature decomposition of video-and-language representations reduces the rank of the latent space, resulting in increased representing power for the semantics. Extensive experiments on three benchmark text-video retrieval datasets prove that our EMCL can learn more discriminative video-and-language representations than previous methods, and significantly outperform previous state-of-the-art methods across all metrics. More encouragingly, the proposed method can be applied to boost the performance of existing approaches either as a jointly training layer or an out-of-the-box inference module with no extra training, making it easy to be incorporated into any existing methods.
PCR: Pessimistic Consistency Regularization for Semi-Supervised Segmentation
Oct 16, 2022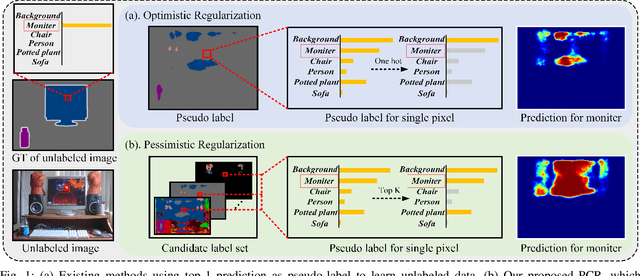
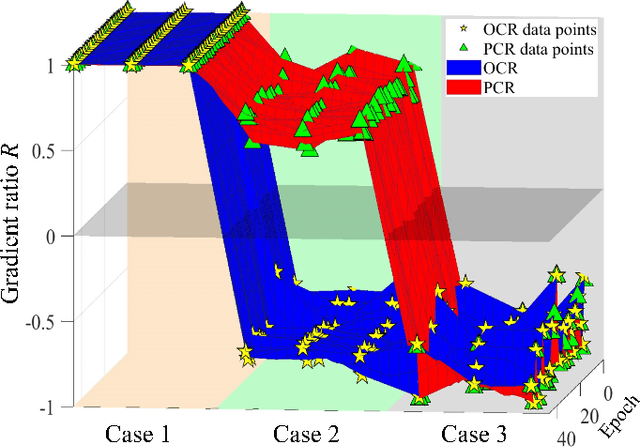
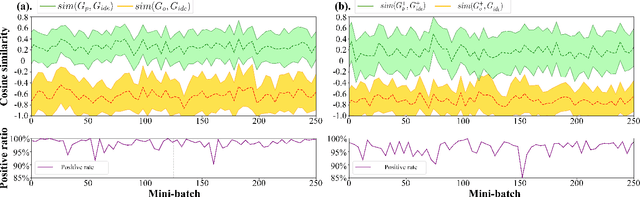
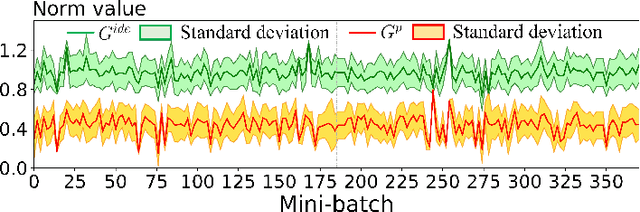
Currently, state-of-the-art semi-supervised learning (SSL) segmentation methods employ pseudo labels to train their models, which is an optimistic training manner that supposes the predicted pseudo labels are correct. However, their models will be optimized incorrectly when the above assumption does not hold. In this paper, we propose a Pessimistic Consistency Regularization (PCR) which considers a pessimistic case that pseudo labels are not always correct. PCR makes it possible for our model to learn the ground truth (GT) in pessimism by adaptively providing a candidate label set containing K proposals for each unlabeled pixel. Specifically, we propose a pessimistic consistency loss which trains our model to learn the possible GT from multiple candidate labels. In addition, we develop a candidate label proposal method to adaptively decide which pseudo labels are provided for each pixel. Our method is easy to implement and could be applied to existing baselines without changing their frameworks. Theoretical analysis and experiments on various benchmarks demonstrate the superiority of our approach to state-of-the-art alternatives.
Dynamic Clustering Network for Unsupervised Semantic Segmentation
Oct 12, 2022



Recently, the ability of self-supervised Vision Transformer (ViT) to represent pixel-level semantic relationships promotes the development of unsupervised dense prediction tasks. In this work, we investigate transferring self-supervised ViT to unsupervised semantic segmentation task. According to the analysis that the pixel-level representations of self-supervised ViT within a single image achieve good intra-class compactness and inter-class discrimination, we propose the Dynamic Clustering Network (DCN) to dynamically infer the underlying cluster centers for different images. By training with the proposed modularity loss, the DCN learns to project a set of prototypes to cluster centers for pixel representations in each image and assign pixels to different clusters, resulting on dividing each image to class-agnostic regions. For achieving unsupervised semantic segmentation task, we treat it as a region classification problem. Based on the regions produced by the DCN, we explore different ways to extract region-level representations and classify them in an unsupervised manner. We demonstrate the effectiveness of the proposed method trough experiments on unsupervised semantic segmentation, and achieve state-of-the-art performance on PASCAL VOC 2012 unsupervised semantic segmentation task.
Toward 3D Spatial Reasoning for Human-like Text-based Visual Question Answering
Sep 21, 2022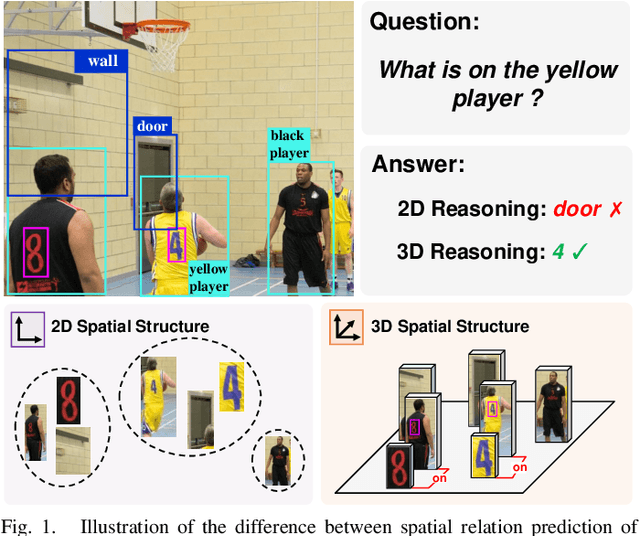

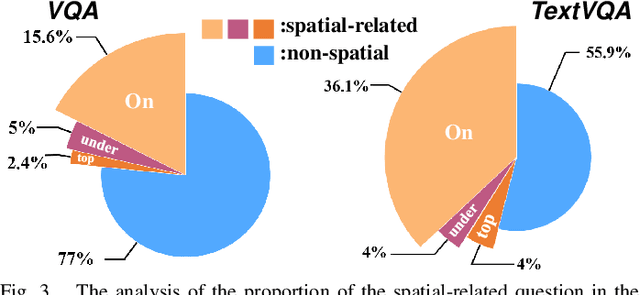
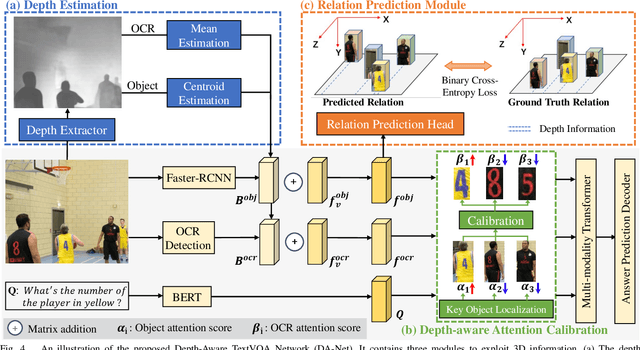
Text-based Visual Question Answering~(TextVQA) aims to produce correct answers for given questions about the images with multiple scene texts. In most cases, the texts naturally attach to the surface of the objects. Therefore, spatial reasoning between texts and objects is crucial in TextVQA. However, existing approaches are constrained within 2D spatial information learned from the input images and rely on transformer-based architectures to reason implicitly during the fusion process. Under this setting, these 2D spatial reasoning approaches cannot distinguish the fine-grain spatial relations between visual objects and scene texts on the same image plane, thereby impairing the interpretability and performance of TextVQA models. In this paper, we introduce 3D geometric information into a human-like spatial reasoning process to capture the contextual knowledge of key objects step-by-step. %we formulate a human-like spatial reasoning process by introducing 3D geometric information for capturing key objects' contextual knowledge. To enhance the model's understanding of 3D spatial relationships, Specifically, (i)~we propose a relation prediction module for accurately locating the region of interest of critical objects; (ii)~we design a depth-aware attention calibration module for calibrating the OCR tokens' attention according to critical objects. Extensive experiments show that our method achieves state-of-the-art performance on TextVQA and ST-VQA datasets. More encouragingly, our model surpasses others by clear margins of 5.7\% and 12.1\% on questions that involve spatial reasoning in TextVQA and ST-VQA valid split. Besides, we also verify the generalizability of our model on the text-based image captioning task.
Locality Guidance for Improving Vision Transformers on Tiny Datasets
Jul 20, 2022


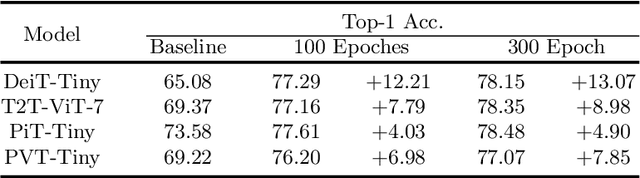
While the Vision Transformer (VT) architecture is becoming trendy in computer vision, pure VT models perform poorly on tiny datasets. To address this issue, this paper proposes the locality guidance for improving the performance of VTs on tiny datasets. We first analyze that the local information, which is of great importance for understanding images, is hard to be learned with limited data due to the high flexibility and intrinsic globality of the self-attention mechanism in VTs. To facilitate local information, we realize the locality guidance for VTs by imitating the features of an already trained convolutional neural network (CNN), inspired by the built-in local-to-global hierarchy of CNN. Under our dual-task learning paradigm, the locality guidance provided by a lightweight CNN trained on low-resolution images is adequate to accelerate the convergence and improve the performance of VTs to a large extent. Therefore, our locality guidance approach is very simple and efficient, and can serve as a basic performance enhancement method for VTs on tiny datasets. Extensive experiments demonstrate that our method can significantly improve VTs when training from scratch on tiny datasets and is compatible with different kinds of VTs and datasets. For example, our proposed method can boost the performance of various VTs on tiny datasets (e.g., 13.07% for DeiT, 8.98% for T2T and 7.85% for PVT), and enhance even stronger baseline PVTv2 by 1.86% to 79.30%, showing the potential of VTs on tiny datasets. The code is available at https://github.com/lkhl/tiny-transformers.
Difference in Euclidean Norm Can Cause Semantic Divergence in Batch Normalization
Jul 06, 2022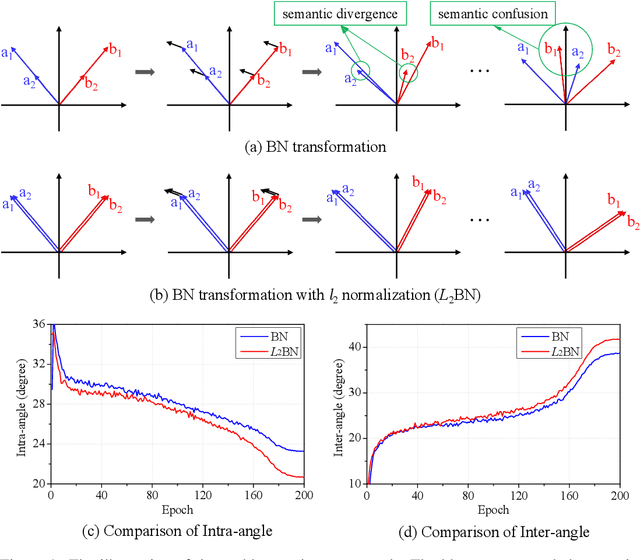

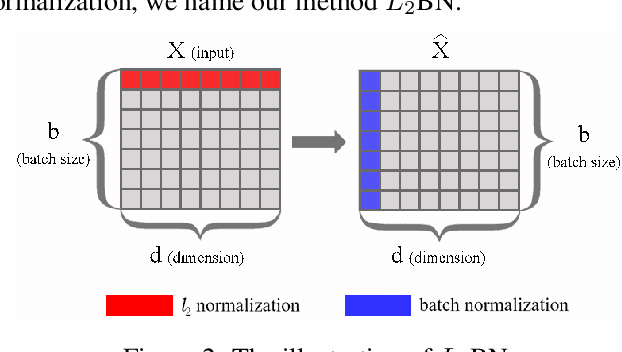
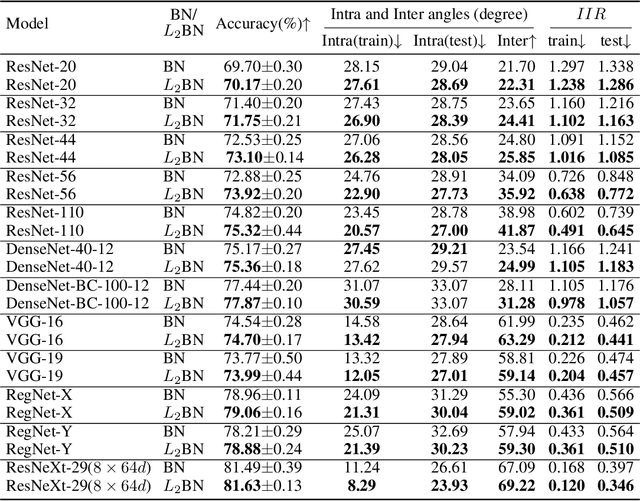
In this paper, we show that the difference in Euclidean norm of samples can make a contribution to the semantic divergence and even confusion, after the spatial translation and scaling transformation in batch normalization. To address this issue, we propose an intuitive but effective method to equalize the Euclidean norms of sample vectors. Concretely, we $l_2$-normalize each sample vector before batch normalization, and therefore the sample vectors are of the same magnitude. Since the proposed method combines the $l_2$ normalization and batch normalization, we name our method as $L_2$BN. The $L_2$BN can strengthen the compactness of intra-class features and enlarge the discrepancy of inter-class features. In addition, it can help the gradient converge to a stable scale. The $L_2$BN is easy to implement and can exert its effect without any additional parameters and hyper-parameters. Therefore, it can be used as a basic normalization method for neural networks. We evaluate the effectiveness of $L_2$BN through extensive experiments with various models on image classification and acoustic scene classification tasks. The experimental results demonstrate that the $L_2$BN is able to boost the generalization ability of various neural network models and achieve considerable performance improvements.
ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Mar 31, 2022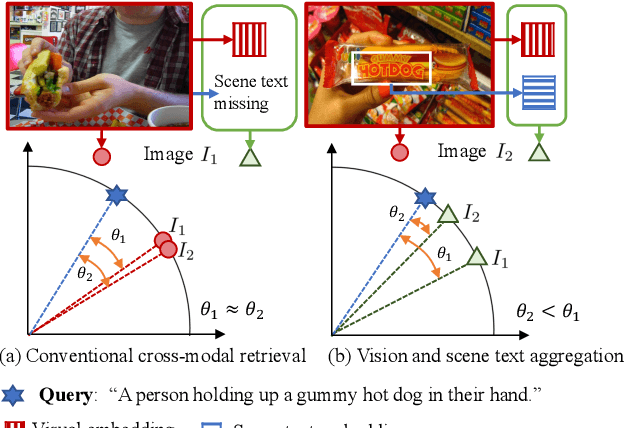

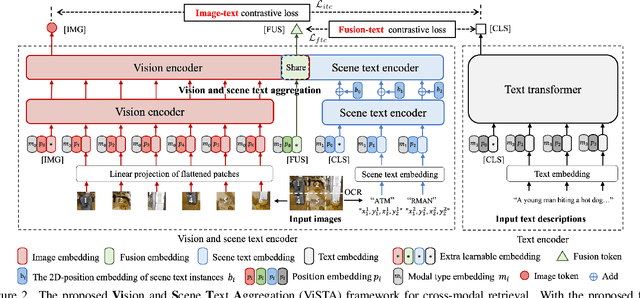

Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics. Most of existing cross-modal retrieval approaches ignore the usage of scene text information and directly adding this information may lead to performance degradation in scene text free scenarios. To address this issue, we propose a full transformer architecture to unify these cross-modal retrieval scenarios in a single $\textbf{Vi}$sion and $\textbf{S}$cene $\textbf{T}$ext $\textbf{A}$ggregation framework (ViSTA). Specifically, ViSTA utilizes transformer blocks to directly encode image patches and fuse scene text embedding to learn an aggregated visual representation for cross-modal retrieval. To tackle the modality missing problem of scene text, we propose a novel fusion token based transformer aggregation approach to exchange the necessary scene text information only through the fusion token and concentrate on the most important features in each modality. To further strengthen the visual modality, we develop dual contrastive learning losses to embed both image-text pairs and fusion-text pairs into a common cross-modal space. Compared to existing methods, ViSTA enables to aggregate relevant scene text semantics with visual appearance, and hence improve results under both scene text free and scene text aware scenarios. Experimental results show that ViSTA outperforms other methods by at least $\bf{8.4}\%$ at Recall@1 for scene text aware retrieval task. Compared with state-of-the-art scene text free retrieval methods, ViSTA can achieve better accuracy on Flicker30K and MSCOCO while running at least three times faster during the inference stage, which validates the effectiveness of the proposed framework.
Harmonized Multimodal Learning with Gaussian Process Latent Variable Models
Aug 14, 2019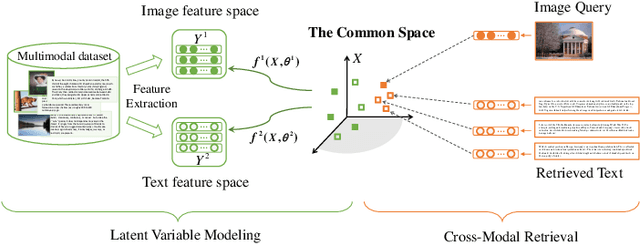
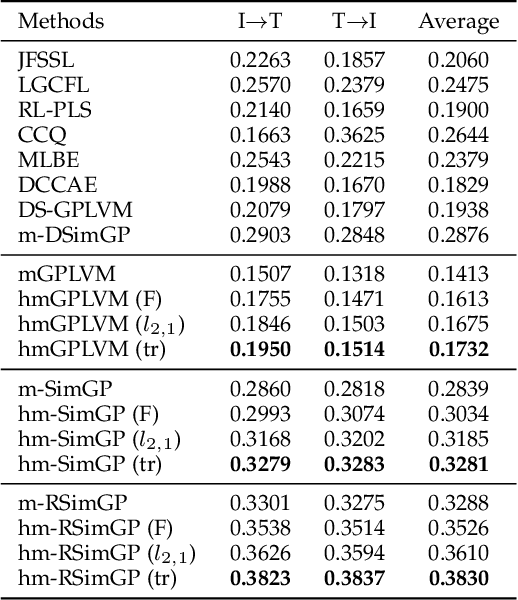

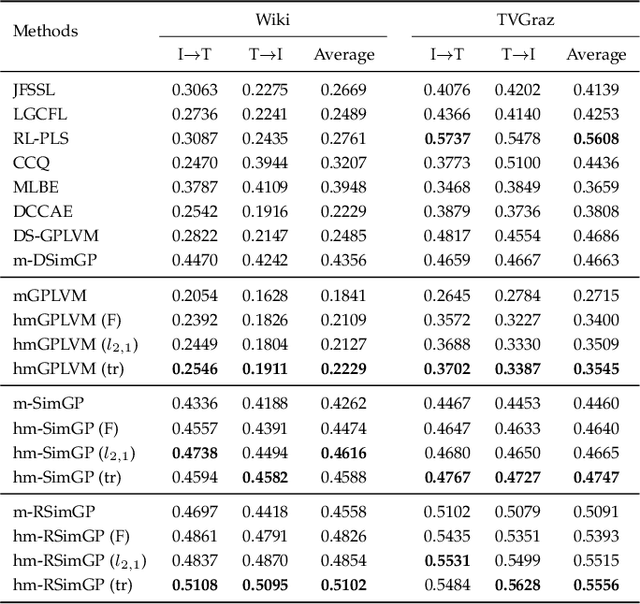
Multimodal learning aims to discover the relationship between multiple modalities. It has become an important research topic due to extensive multimodal applications such as cross-modal retrieval. This paper attempts to address the modality heterogeneity problem based on Gaussian process latent variable models (GPLVMs) to represent multimodal data in a common space. Previous multimodal GPLVM extensions generally adopt individual learning schemes on latent representations and kernel hyperparameters, which ignore their intrinsic relationship. To exploit strong complementarity among different modalities and GPLVM components, we develop a novel learning scheme called Harmonization, where latent model parameters are jointly learned from each other. Beyond the correlation fitting or intra-modal structure preservation paradigms widely used in existing studies, the harmonization is derived in a model-driven manner to encourage the agreement between modality-specific GP kernels and the similarity of latent representations. We present a range of multimodal learning models by incorporating the harmonization mechanism into several representative GPLVM-based approaches. Experimental results on four benchmark datasets show that the proposed models outperform the strong baselines for cross-modal retrieval tasks, and that the harmonized multimodal learning method is superior in discovering semantically consistent latent representation.