 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecouple Content and Motion for Conditional Image-to-Video Generation
Nov 24, 2023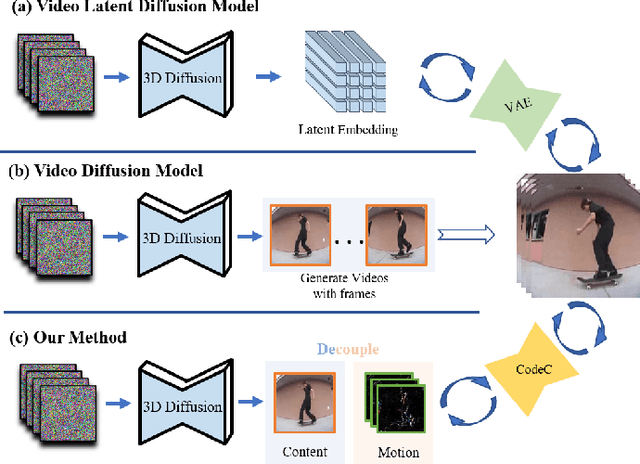

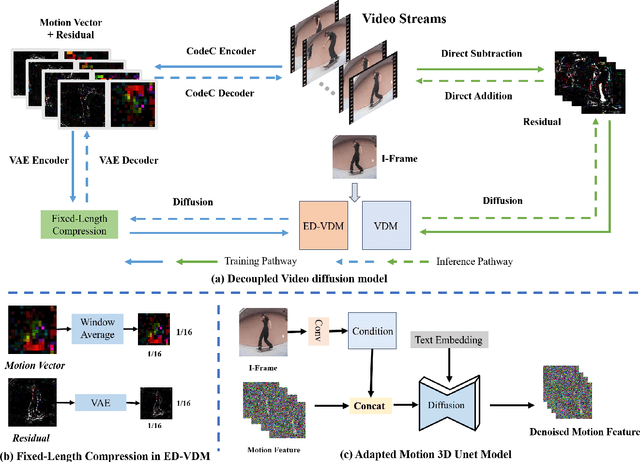

The goal of conditional image-to-video (cI2V) generation is to create a believable new video by beginning with the condition, i.e., one image and text.The previous cI2V generation methods conventionally perform in RGB pixel space, with limitations in modeling motion consistency and visual continuity. Additionally, the efficiency of generating videos in pixel space is quite low.In this paper, we propose a novel approach to address these challenges by disentangling the target RGB pixels into two distinct components: spatial content and temporal motions. Specifically, we predict temporal motions which include motion vector and residual based on a 3D-UNet diffusion model. By explicitly modeling temporal motions and warping them to the starting image, we improve the temporal consistency of generated videos. This results in a reduction of spatial redundancy, emphasizing temporal details. Our proposed method achieves performance improvements by disentangling content and motion, all without introducing new structural complexities to the model. Extensive experiments on various datasets confirm our approach's superior performance over the majority of state-of-the-art methods in both effectiveness and efficiency.
ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval
Mar 31, 2022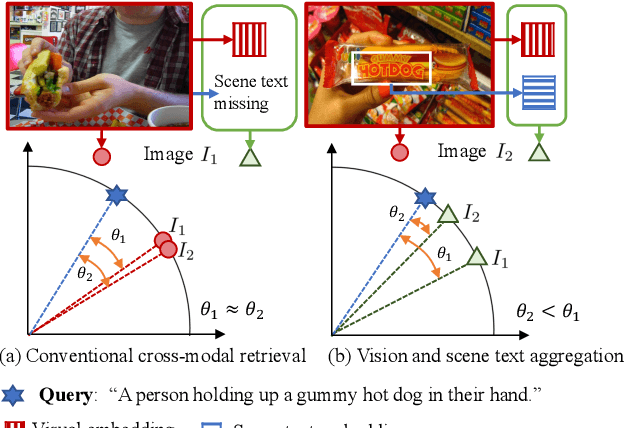

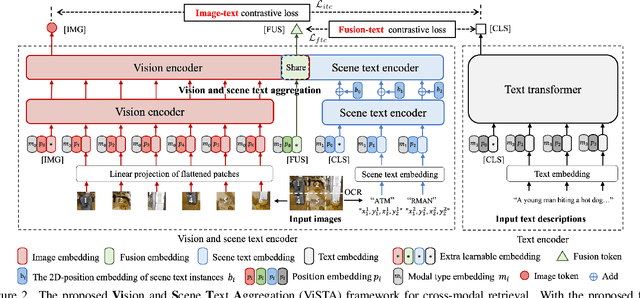

Visual appearance is considered to be the most important cue to understand images for cross-modal retrieval, while sometimes the scene text appearing in images can provide valuable information to understand the visual semantics. Most of existing cross-modal retrieval approaches ignore the usage of scene text information and directly adding this information may lead to performance degradation in scene text free scenarios. To address this issue, we propose a full transformer architecture to unify these cross-modal retrieval scenarios in a single $\textbf{Vi}$sion and $\textbf{S}$cene $\textbf{T}$ext $\textbf{A}$ggregation framework (ViSTA). Specifically, ViSTA utilizes transformer blocks to directly encode image patches and fuse scene text embedding to learn an aggregated visual representation for cross-modal retrieval. To tackle the modality missing problem of scene text, we propose a novel fusion token based transformer aggregation approach to exchange the necessary scene text information only through the fusion token and concentrate on the most important features in each modality. To further strengthen the visual modality, we develop dual contrastive learning losses to embed both image-text pairs and fusion-text pairs into a common cross-modal space. Compared to existing methods, ViSTA enables to aggregate relevant scene text semantics with visual appearance, and hence improve results under both scene text free and scene text aware scenarios. Experimental results show that ViSTA outperforms other methods by at least $\bf{8.4}\%$ at Recall@1 for scene text aware retrieval task. Compared with state-of-the-art scene text free retrieval methods, ViSTA can achieve better accuracy on Flicker30K and MSCOCO while running at least three times faster during the inference stage, which validates the effectiveness of the proposed framework.