 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeficient Excitation in Parameter Learning
Mar 04, 2025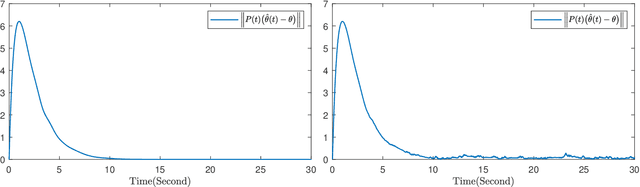
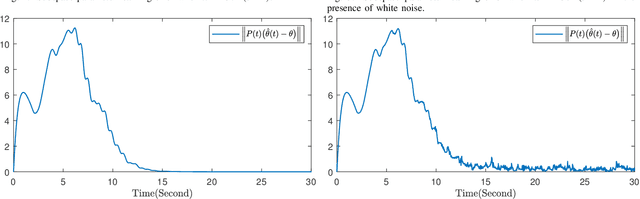
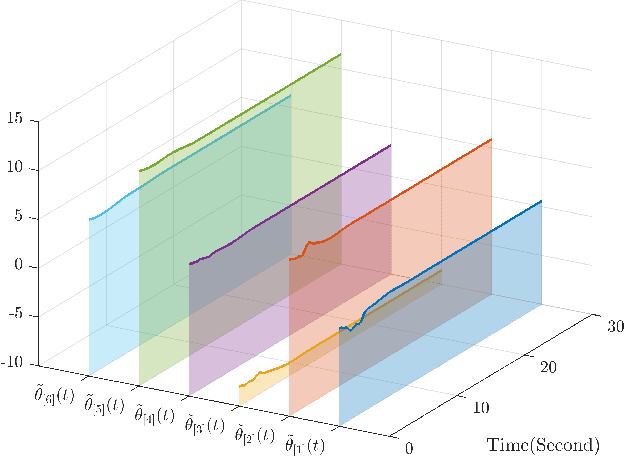
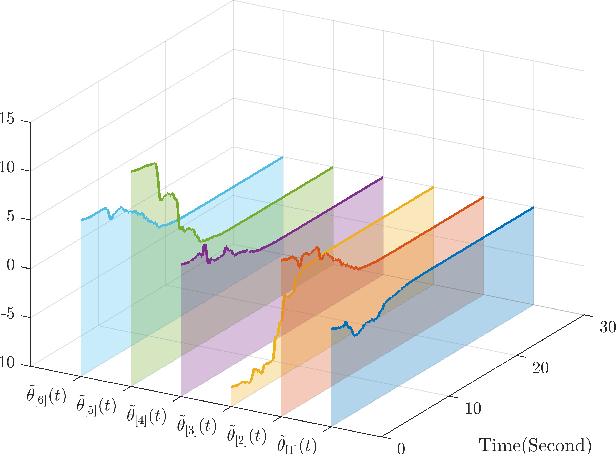
This paper investigates parameter learning problems under deficient excitation (DE). The DE condition is a rank-deficient, and therefore, a more general evolution of the well-known persistent excitation condition. Under the DE condition, a proposed online algorithm is able to calculate the identifiable and non-identifiable subspaces, and finally give an optimal parameter estimate in the sense of least squares. In particular, the learning error within the identifiable subspace exponentially converges to zero in the noise-free case, even without persistent excitation. The DE condition also provides a new perspective for solving distributed parameter learning problems, where the challenge is posed by local regressors that are often insufficiently excited. To improve knowledge of the unknown parameters, a cooperative learning protocol is proposed for a group of estimators that collect measured information under complementary DE conditions. This protocol allows each local estimator to operate locally in its identifiable subspace, and reach a consensus with neighbours in its non-identifiable subspace. As a result, the task of estimating unknown parameters can be achieved in a distributed way using cooperative local estimators. Application examples in system identification are given to demonstrate the effectiveness of the theoretical results developed in this paper.
SubstationAI: Multimodal Large Model-Based Approaches for Analyzing Substation Equipment Faults
Dec 22, 2024



The reliability of substation equipment is crucial to the stability of power systems, but traditional fault analysis methods heavily rely on manual expertise, limiting their effectiveness in handling complex and large-scale data. This paper proposes a substation equipment fault analysis method based on a multimodal large language model (MLLM). We developed a database containing 40,000 entries, including images, defect labels, and analysis reports, and used an image-to-video generation model for data augmentation. Detailed fault analysis reports were generated using GPT-4. Based on this database, we developed SubstationAI, the first model dedicated to substation fault analysis, and designed a fault diagnosis knowledge base along with knowledge enhancement methods. Experimental results show that SubstationAI significantly outperforms existing models, such as GPT-4, across various evaluation metrics, demonstrating higher accuracy and practicality in fault cause analysis, repair suggestions, and preventive measures, providing a more advanced solution for substation equipment fault analysis.
Decouple Content and Motion for Conditional Image-to-Video Generation
Nov 24, 2023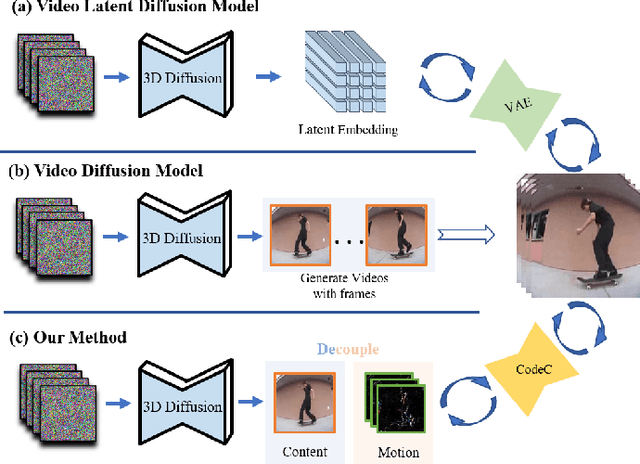

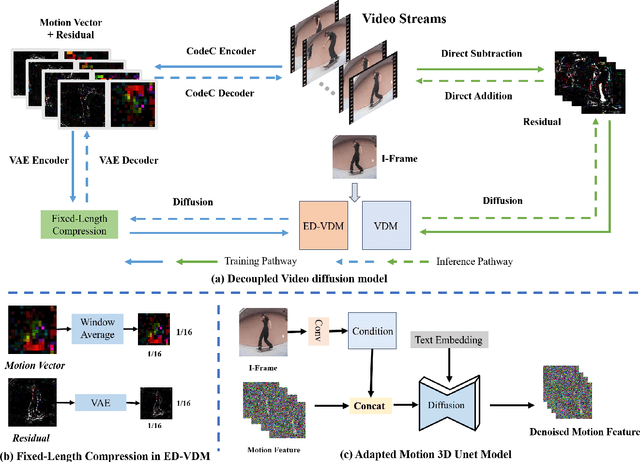

The goal of conditional image-to-video (cI2V) generation is to create a believable new video by beginning with the condition, i.e., one image and text.The previous cI2V generation methods conventionally perform in RGB pixel space, with limitations in modeling motion consistency and visual continuity. Additionally, the efficiency of generating videos in pixel space is quite low.In this paper, we propose a novel approach to address these challenges by disentangling the target RGB pixels into two distinct components: spatial content and temporal motions. Specifically, we predict temporal motions which include motion vector and residual based on a 3D-UNet diffusion model. By explicitly modeling temporal motions and warping them to the starting image, we improve the temporal consistency of generated videos. This results in a reduction of spatial redundancy, emphasizing temporal details. Our proposed method achieves performance improvements by disentangling content and motion, all without introducing new structural complexities to the model. Extensive experiments on various datasets confirm our approach's superior performance over the majority of state-of-the-art methods in both effectiveness and efficiency.