 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-StructureV2: A Stronger Document Analysis System
Oct 11, 2022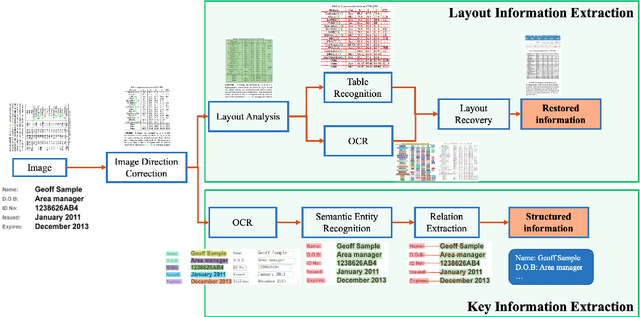



A large amount of document data exists in unstructured form such as raw images without any text information. Designing a practical document image analysis system is a meaningful but challenging task. In previous work, we proposed an intelligent document analysis system PP-Structure. In order to further upgrade the function and performance of PP-Structure, we propose PP-StructureV2 in this work, which contains two subsystems: Layout Information Extraction and Key Information Extraction. Firstly, we integrate Image Direction Correction module and Layout Restoration module to enhance the functionality of the system. Secondly, 8 practical strategies are utilized in PP-StructureV2 for better performance. For Layout Analysis model, we introduce ultra light-weight detector PP-PicoDet and knowledge distillation algorithm FGD for model lightweighting, which increased the inference speed by 11 times with comparable mAP. For Table Recognition model, we utilize PP-LCNet, CSP-PAN and SLAHead to optimize the backbone module, feature fusion module and decoding module, respectively, which improved the table structure accuracy by 6\% with comparable inference speed. For Key Information Extraction model, we introduce VI-LayoutXLM which is a visual-feature independent LayoutXLM architecture, TB-YX sorting algorithm and U-DML knowledge distillation algorithm, which brought 2.8\% and 9.1\% improvement respectively on the Hmean of Semantic Entity Recognition and Relation Extraction tasks. All the above mentioned models and code are open-sourced in the GitHub repository PaddleOCR.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

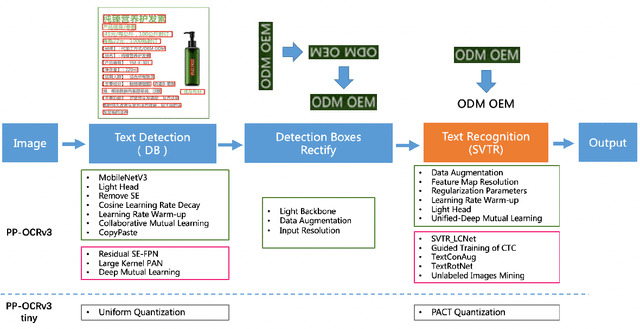
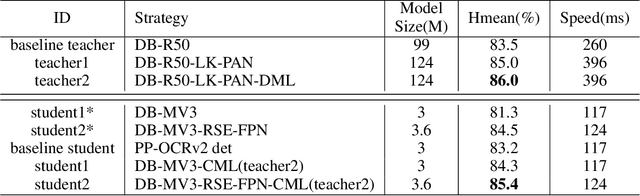
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.