 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOFFEE: COdesign Framework for Feature Enriched Embeddings in Ads-Ranking Systems
Jan 06, 2026Diverse and enriched data sources are essential for commercial ads-recommendation models to accurately assess user interest both before and after engagement with content. While extended user-engagement histories can improve the prediction of user interests, it is equally important to embed activity sequences from multiple sources to ensure freshness of user and ad-representations, following scaling law principles. In this paper, we present a novel three-dimensional framework for enhancing user-ad representations without increasing model inference or serving complexity. The first dimension examines the impact of incorporating diverse event sources, the second considers the benefits of longer user histories, and the third focuses on enriching data with additional event attributes and multi-modal embeddings. We assess the return on investment (ROI) of our source enrichment framework by comparing organic user engagement sources, such as content viewing, with ad-impression sources. The proposed method can boost the area under curve (AUC) and the slope of scaling curves for ad-impression sources by 1.56 to 2 times compared to organic usage sources even for short online-sequence lengths of 100 to 10K. Additionally, click-through rate (CTR) prediction improves by 0.56% AUC over the baseline production ad-recommendation system when using enriched ad-impression event sources, leading to improved sequence scaling resolutions for longer and offline user-ad representations.
* 4 pages, 5 figures, 1 table
MAC: A unified framework boosting low resource automatic speech recognition
Feb 15, 2023We propose a unified framework for low resource automatic speech recognition tasks named meta audio concatenation (MAC). It is easy to implement and can be carried out in extremely low resource environments. Mathematically, we give a clear description of MAC framework from the perspective of bayesian sampling. In this framework, we leverage a novel concatenative synthesis text-to-speech system to boost the low resource ASR task. By the concatenative synthesis text-to-speech system, we can integrate language pronunciation rules and adjust the TTS process. Furthermore, we propose a broad notion of meta audio set to meet the modeling needs of different languages and different scenes when using the system. Extensive experiments have demonstrated the great effectiveness of MAC on low resource ASR tasks. For CTC greedy search, CTC prefix, attention, and attention rescoring decode mode in Cantonese ASR task, Taiwanese ASR task, and Japanese ASR task the MAC method can reduce the CER by more than 15\%. Furthermore, in the ASR task, MAC beats wav2vec2 (with fine-tuning) on common voice datasets of Cantonese and gets really competitive results on common voice datasets of Taiwanese and Japanese. Among them, it is worth mentioning that we achieve a \textbf{10.9\%} character error rate (CER) on the common voice Cantonese ASR task, bringing about \textbf{30\%} relative improvement compared to the wav2vec2 (with fine-tuning).
SAN: a robust end-to-end ASR model architecture
Oct 27, 2022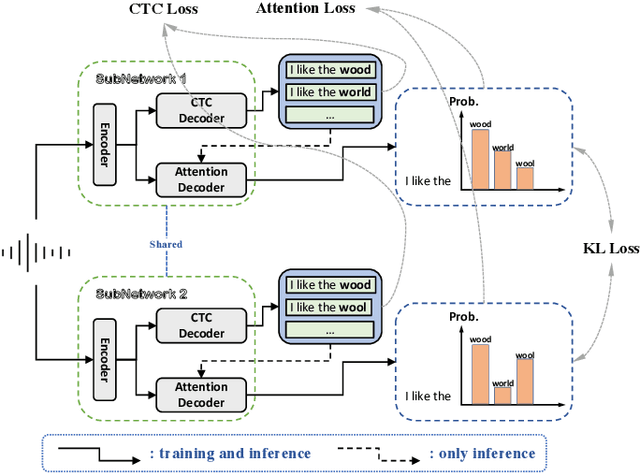
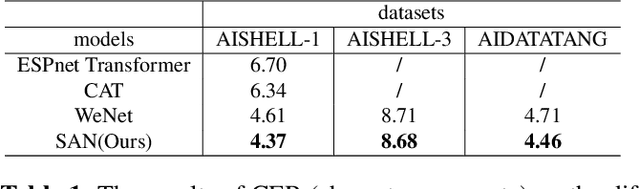
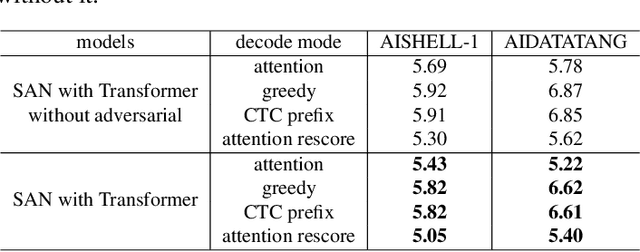

In this paper, we propose a novel Siamese Adversarial Network (SAN) architecture for automatic speech recognition, which aims at solving the difficulty of fuzzy audio recognition. Specifically, SAN constructs two sub-networks to differentiate the audio feature input and then introduces a loss to unify the output distribution of these sub-networks. Adversarial learning enables the network to capture more essential acoustic features and helps the models achieve better performance when encountering fuzzy audio input. We conduct numerical experiments with the SAN model on several datasets for the automatic speech recognition task. All experimental results show that the siamese adversarial nets significantly reduce the character error rate (CER). Specifically, we achieve a new state of art 4.37 CER without language model on the AISHELL-1 dataset, which leads to around 5% relative CER reduction. To reveal the generality of the siamese adversarial net, we also conduct experiments on the phoneme recognition task, which also shows the superiority of the siamese adversarial network.
10 hours data is all you need
Oct 24, 2022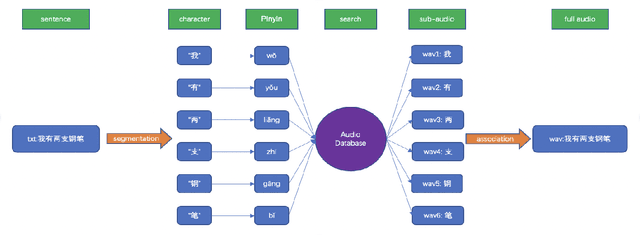

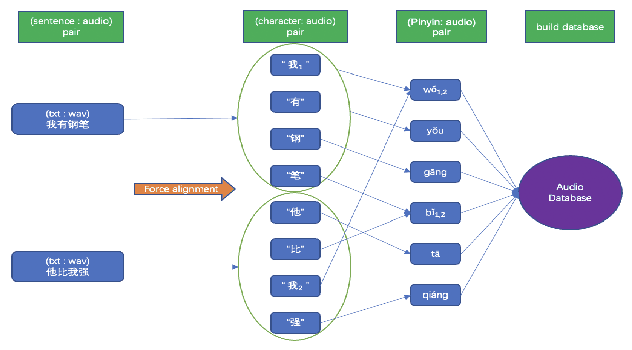

We propose a novel procedure to generate pseudo mandarin speech data named as CAMP (character audio mix up), which aims at generating audio from a character scale. We also raise a method for building a mandarin character scale audio database adaptive to CAMP named as META-AUDIO, which makes full use of audio data and can greatly increase the data diversity of the database. Experiments show that our CAMP method is simple and quite effective. For example, we train models with 10 hours of audio data in AISHELL-1 and pseudo audio data generated by CAMP, and achieve a competitive 11.07 character error rate (CER). Besides, we also perform training with only 10 hours of audio data in AIDATATANG dataset and pseudo audio data generated by CAMP, which again achieves a competitive 8.26 CER.
Robust Trajectory-based Density Estimation for Geometric Structure Recovery: Theory and Applications
Oct 01, 2022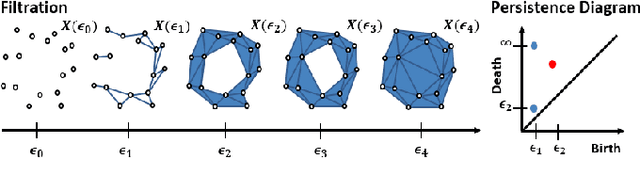


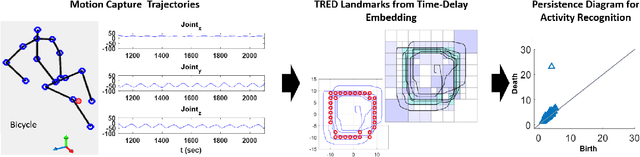
With the rise of the Internet of Things, strategies for effectively processing big data are essential for discovering meaningul insights. The time series datasets produced by groups of interconnected devices contain valuable underlying patterns. Recent works have extracted patterns from spatio-temporal datasets to aid in road network generation, activity recognition, and others. The speed and accuracy of the underlying geometry reconstruction are important in these applications. Existing methods such as kernel density estimation (KDE) have been used but are often computationally expensive. We propose modifying edge quadtrees to utilize their effective heirarchical structure. Our modification estimates density using a novel trajectory count function which provides mathematical guarantees on the stability of the count by enforcing an invariance to local perturbations. We evaluate our method's effectiveness at extracting the underlying geometry and representative subsample points. For verification, we compare against a KDE variant at extracting the underlying shape of noisy synthetic trajectories travelling alonng the shape. We compare map extraction from GPS traces against current methods. Our method significantly improves runtime while extracting the geometry better or at least comparably. We also compare against maxmin subsampling on an activity recognition data set and find a significant runtime improvement with comparable performance.