 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge10 hours data is all you need
Paper and Code
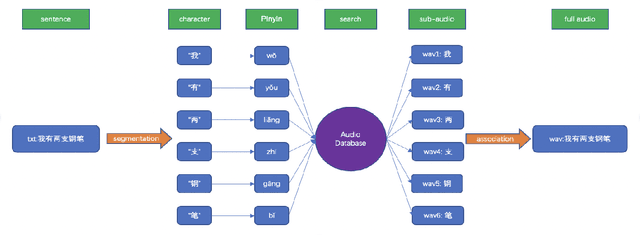

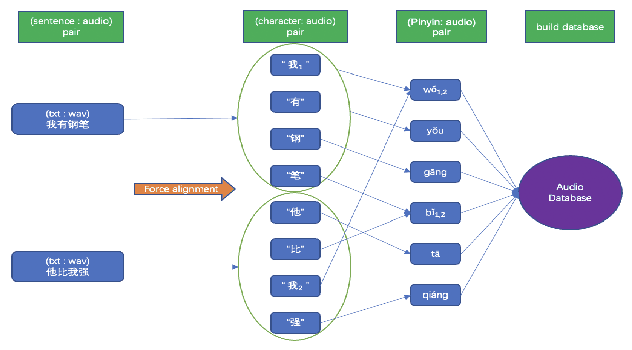

We propose a novel procedure to generate pseudo mandarin speech data named as CAMP (character audio mix up), which aims at generating audio from a character scale. We also raise a method for building a mandarin character scale audio database adaptive to CAMP named as META-AUDIO, which makes full use of audio data and can greatly increase the data diversity of the database. Experiments show that our CAMP method is simple and quite effective. For example, we train models with 10 hours of audio data in AISHELL-1 and pseudo audio data generated by CAMP, and achieve a competitive 11.07 character error rate (CER). Besides, we also perform training with only 10 hours of audio data in AIDATATANG dataset and pseudo audio data generated by CAMP, which again achieves a competitive 8.26 CER.