 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
Paper and Code
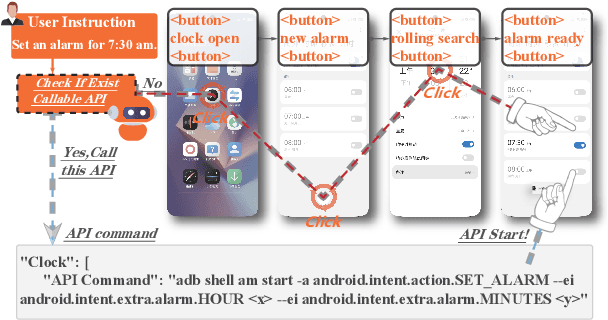


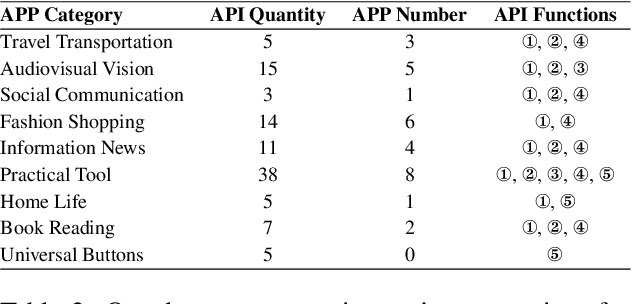
With the remarkable advancements of large language models (LLMs), LLM-based agents have become a research hotspot in human-computer interaction. However, there is a scarcity of benchmarks available for LLM-based mobile agents. Benchmarking these agents generally faces three main challenges: (1) The inefficiency of UI-only operations imposes limitations to task evaluation. (2) Specific instructions within a singular application lack adequacy for assessing the multi-dimensional reasoning and decision-making capacities of LLM mobile agents. (3) Current evaluation metrics are insufficient to accurately assess the process of sequential actions. To this end, we propose Mobile-Bench, a novel benchmark for evaluating the capabilities of LLM-based mobile agents. First, we expand conventional UI operations by incorporating 103 collected APIs to accelerate the efficiency of task completion. Subsequently, we collect evaluation data by combining real user queries with augmentation from LLMs. To better evaluate different levels of planning capabilities for mobile agents, our data is categorized into three distinct groups: SAST, SAMT, and MAMT, reflecting varying levels of task complexity. Mobile-Bench comprises 832 data entries, with more than 200 tasks specifically designed to evaluate multi-APP collaboration scenarios. Furthermore, we introduce a more accurate evaluation metric, named CheckPoint, to assess whether LLM-based mobile agents reach essential points during their planning and reasoning steps.