 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Small and One Large for Document-level Event Argument Extraction
Nov 08, 2024
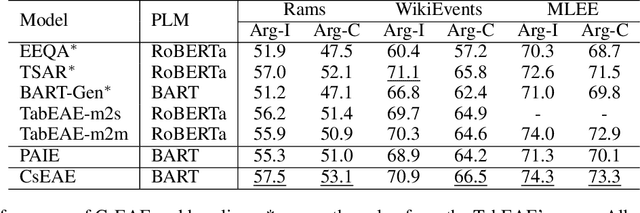
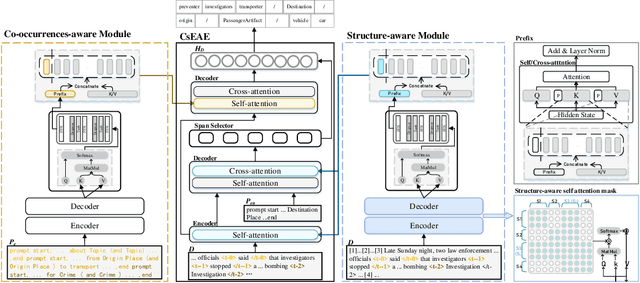
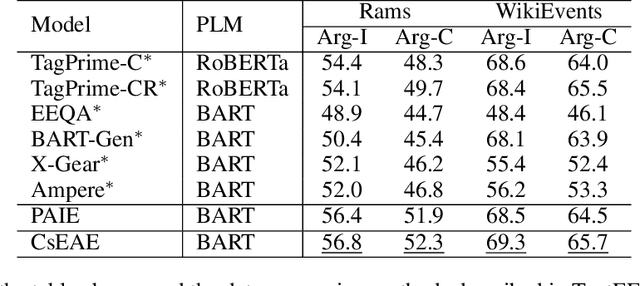
Document-level Event Argument Extraction (EAE) faces two challenges due to increased input length: 1) difficulty in distinguishing semantic boundaries between events, and 2) interference from redundant information. To address these issues, we propose two methods. The first method introduces the Co and Structure Event Argument Extraction model (CsEAE) based on Small Language Models (SLMs). CsEAE includes a co-occurrences-aware module, which integrates information about all events present in the current input through context labeling and co-occurrences event prompts extraction. Additionally, CsEAE includes a structure-aware module that reduces interference from redundant information by establishing structural relationships between the sentence containing the trigger and other sentences in the document. The second method introduces new prompts to transform the extraction task into a generative task suitable for Large Language Models (LLMs), addressing gaps in EAE performance using LLMs under Supervised Fine-Tuning (SFT) conditions. We also fine-tuned multiple datasets to develop an LLM that performs better across most datasets. Finally, we applied insights from CsEAE to LLMs, achieving further performance improvements. This suggests that reliable insights validated on SLMs are also applicable to LLMs. We tested our models on the Rams, WikiEvents, and MLEE datasets. The CsEAE model achieved improvements of 2.1\%, 2.3\%, and 3.2\% in the Arg-C F1 metric compared to the baseline, PAIE~\cite{PAIE}. For LLMs, we demonstrated that their performance on document-level datasets is comparable to that of SLMs~\footnote{All code is available at https://github.com/simon-p-j-r/CsEAE}.
MDF: A Dynamic Fusion Model for Multi-modal Fake News Detection
Jun 28, 2024Fake news detection has received increasing attention from researchers in recent years, especially multi-modal fake news detection containing both text and images. However, many previous works have fed two modal features, text and image, into a binary classifier after a simple concatenation or attention mechanism, in which the features contain a large amount of noise inherent in the data,which in turn leads to intra- and inter-modal uncertainty. In addition, although many methods based on simply splicing two modalities have achieved more prominent results, these methods ignore the drawback of holding fixed weights across modalities, which would lead to some features with higher impact factors being ignored. To alleviate the above problems, we propose a new dynamic fusion framework dubbed MDF for fake news detection. As far as we know, it is the first attempt of dynamic fusion framework in the field of fake news detection. Specifically, our model consists of two main components:(1) UEM as an uncertainty modeling module employing a multi-head attention mechanism to model intra-modal uncertainty; and (2) DFN is a dynamic fusion module based on D-S evidence theory for dynamically fusing the weights of two modalities, text and image. In order to present better results for the dynamic fusion framework, we use GAT for inter-modal uncertainty and weight modeling before DFN. Extensive experiments on two benchmark datasets demonstrate the effectiveness and superior performance of the MDF framework. We also conducted a systematic ablation study to gain insight into our motivation and architectural design. We make our model publicly available to:https://github.com/CoisiniStar/MDF