 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Contextual Inertia: Reinforcement Learning with Single-Turn Anchors for Stable Multi-Turn Interaction
Mar 05, 2026While LLMs demonstrate strong reasoning capabilities when provided with full information in a single turn, they exhibit substantial vulnerability in multi-turn interactions. Specifically, when information is revealed incrementally or requires updates, models frequently fail to integrate new constraints, leading to a collapse in performance compared to their single-turn baselines. We term the root cause as \emph{Contextual Inertia}: a phenomenon where models rigidly adhere to previous reasoning traces. Even when users explicitly provide corrections or new data in later turns, the model ignores them, preferring to maintain consistency with its previous (incorrect) reasoning path. To address this, we introduce \textbf{R}einforcement \textbf{L}earning with \textbf{S}ingle-\textbf{T}urn \textbf{A}nchors (\textbf{RLSTA}), a generalizable training approach designed to stabilize multi-turn interaction across diverse scenarios and domains. RLSTA leverages the model's superior single-turn capabilities as stable internal anchors to provide reward signals. By aligning multi-turn responses with these anchors, RLSTA empowers models to break contextual inertia and self-calibrate their reasoning based on the latest information. Experiments show that RLSTA significantly outperforms standard fine-tuning and abstention-based methods. Notably, our method exhibits strong cross-domain generalization (e.g., math to code) and proves effective even without external verifiers, highlighting its potential for general-domain applications.
Cultivating Game Sense for Yourself: Making VLMs Gaming Experts
Mar 27, 2025Developing agents capable of fluid gameplay in first/third-person games without API access remains a critical challenge in Artificial General Intelligence (AGI). Recent efforts leverage Vision Language Models (VLMs) as direct controllers, frequently pausing the game to analyze screens and plan action through language reasoning. However, this inefficient paradigm fundamentally restricts agents to basic and non-fluent interactions: relying on isolated VLM reasoning for each action makes it impossible to handle tasks requiring high reactivity (e.g., FPS shooting) or dynamic adaptability (e.g., ACT combat). To handle this, we propose a paradigm shift in gameplay agent design: instead of directly controlling gameplay, VLM develops specialized execution modules tailored for tasks like shooting and combat. These modules handle real-time game interactions, elevating VLM to a high-level developer. Building upon this paradigm, we introduce GameSense, a gameplay agent framework where VLM develops task-specific game sense modules by observing task execution and leveraging vision tools and neural network training pipelines. These modules encapsulate action-feedback logic, ranging from direct action rules to neural network-based decisions. Experiments demonstrate that our framework is the first to achieve fluent gameplay in diverse genres, including ACT, FPS, and Flappy Bird, setting a new benchmark for game-playing agents.
Multi-Task Model Merging via Adaptive Weight Disentanglement
Nov 27, 2024



Model merging has gained increasing attention as an efficient and effective technique for integrating task-specific weights from various tasks into a unified multi-task model without retraining or additional data. As a representative approach, Task Arithmetic (TA) has demonstrated that combining task vectors through arithmetic operations facilitates efficient capability transfer between different tasks. In this framework, task vectors are obtained by subtracting the parameter values of a pre-trained model from those of individually fine-tuned models initialized from it. Despite the notable effectiveness of TA, interference among task vectors can adversely affect the performance of the merged model. In this paper, we relax the constraints of Task Arithmetic Property and propose Task Consistency Property, which can be regarded as being free from task interference. Through theoretical derivation, we show that such a property can be approximately achieved by seeking orthogonal task vectors. Guiding by this insight, we propose Adaptive Weight Disentanglement (AWD), which decomposes traditional task vectors into a redundant vector and several disentangled task vectors. The primary optimization objective of AWD is to achieve orthogonality among the disentangled task vectors, thereby closely approximating the desired solution. Notably, these disentangled task vectors can be seamlessly integrated into existing merging methodologies. Experimental results demonstrate that our AWD consistently and significantly improves upon previous merging approaches, achieving state-of-the-art results. Our code is available at \href{https://github.com/FarisXiong/AWD.git}{https://github.com/FarisXiong/AWD.git}.
Unveiling and Consulting Core Experts in Retrieval-Augmented MoE-based LLMs
Oct 20, 2024



Retrieval-Augmented Generation (RAG) significantly improved the ability of Large Language Models (LLMs) to solve knowledge-intensive tasks. While existing research seeks to enhance RAG performance by retrieving higher-quality documents or designing RAG-specific LLMs, the internal mechanisms within LLMs that contribute to the effectiveness of RAG systems remain underexplored. In this paper, we aim to investigate these internal mechanisms within the popular Mixture-of-Expert (MoE)-based LLMs and demonstrate how to improve RAG by examining expert activations in these LLMs. Our controlled experiments reveal that several core groups of experts are primarily responsible for RAG-related behaviors. The activation of these core experts can signify the model's inclination towards external/internal knowledge and adjust its behavior. For instance, we identify core experts that can (1) indicate the sufficiency of the model's internal knowledge, (2) assess the quality of retrieved documents, and (3) enhance the model's ability to utilize context. Based on these findings, we propose several strategies to enhance RAG's efficiency and effectiveness through expert activation. Experimental results across various datasets and MoE-based LLMs show the effectiveness of our method.
BEYOND DIALOGUE: A Profile-Dialogue Alignment Framework Towards General Role-Playing Language Model
Aug 21, 2024The rapid advancement of large language models (LLMs) has revolutionized role-playing, enabling the development of general role-playing models. However, current role-playing training has two significant issues: (I) Using a predefined role profile to prompt dialogue training for specific scenarios usually leads to inconsistencies and even conflicts between the dialogue and the profile, resulting in training biases. (II) The model learns to imitate the role based solely on the profile, neglecting profile-dialogue alignment at the sentence level. In this work, we propose a simple yet effective framework called BEYOND DIALOGUE, designed to overcome these hurdles. This framework innovatively introduces "beyond dialogue" tasks to align dialogue with profile traits based on each specific scenario, thereby eliminating biases during training. Furthermore, by adopting an innovative prompting mechanism that generates reasoning outcomes for training, the framework allows the model to achieve fine-grained alignment between profile and dialogue at the sentence level. The aforementioned methods are fully automated and low-cost. Additionally, the integration of automated dialogue and objective evaluation methods forms a comprehensive framework, paving the way for general role-playing. Experimental results demonstrate that our model excels in adhering to and reflecting various dimensions of role profiles, outperforming most proprietary general and specialized role-playing baselines. All code and datasets are available at https://github.com/yuyouyu32/BeyondDialogue.
Compressing Deep Graph Neural Networks via Adversarial Knowledge Distillation
May 24, 2022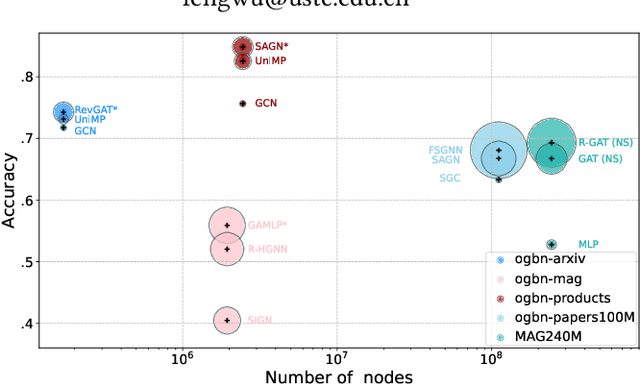


Deep graph neural networks (GNNs) have been shown to be expressive for modeling graph-structured data. Nevertheless, the over-stacked architecture of deep graph models makes it difficult to deploy and rapidly test on mobile or embedded systems. To compress over-stacked GNNs, knowledge distillation via a teacher-student architecture turns out to be an effective technique, where the key step is to measure the discrepancy between teacher and student networks with predefined distance functions. However, using the same distance for graphs of various structures may be unfit, and the optimal distance formulation is hard to determine. To tackle these problems, we propose a novel Adversarial Knowledge Distillation framework for graph models named GraphAKD, which adversarially trains a discriminator and a generator to adaptively detect and decrease the discrepancy. Specifically, noticing that the well-captured inter-node and inter-class correlations favor the success of deep GNNs, we propose to criticize the inherited knowledge from node-level and class-level views with a trainable discriminator. The discriminator distinguishes between teacher knowledge and what the student inherits, while the student GNN works as a generator and aims to fool the discriminator. To our best knowledge, GraphAKD is the first to introduce adversarial training to knowledge distillation in graph domains. Experiments on node-level and graph-level classification benchmarks demonstrate that GraphAKD improves the student performance by a large margin. The results imply that GraphAKD can precisely transfer knowledge from a complicated teacher GNN to a compact student GNN.
Duality-Induced Regularizer for Semantic Matching Knowledge Graph Embeddings
Apr 06, 2022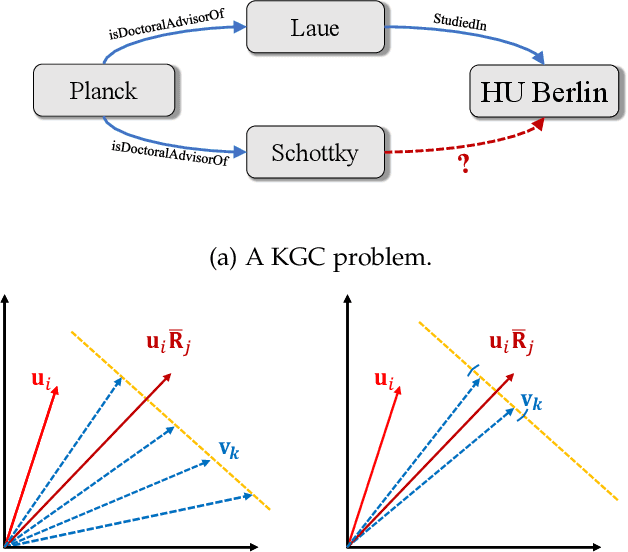

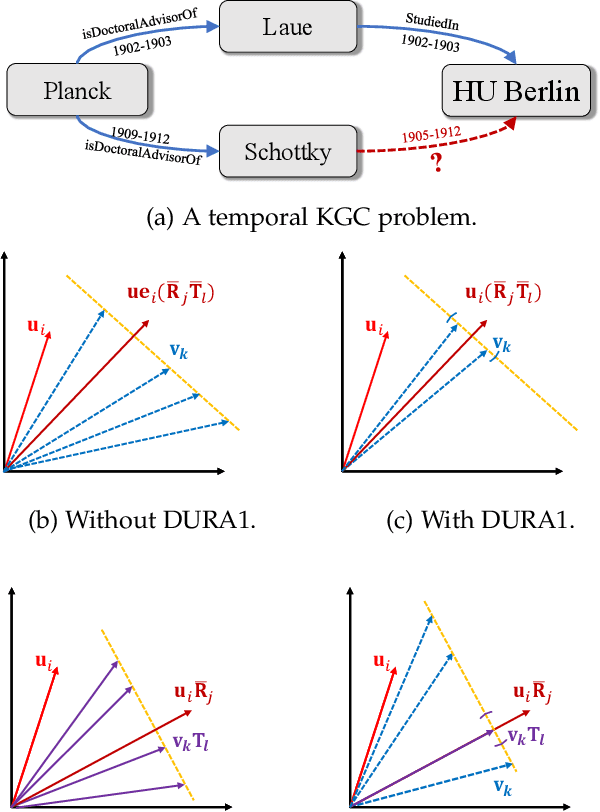
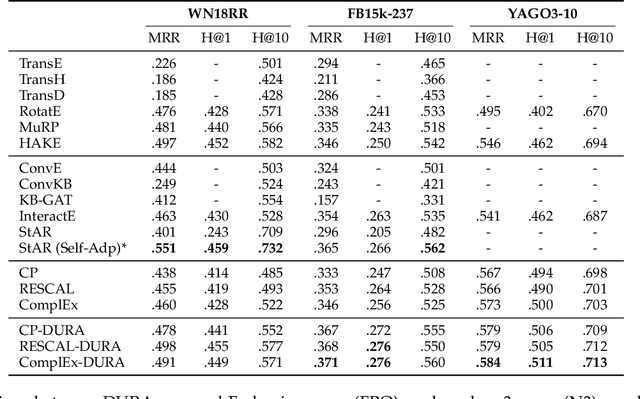
Semantic matching models -- which assume that entities with similar semantics have similar embeddings -- have shown great power in knowledge graph embeddings (KGE). Many existing semantic matching models use inner products in embedding spaces to measure the plausibility of triples and quadruples in static and temporal knowledge graphs. However, vectors that have the same inner products with another vector can still be orthogonal to each other, which implies that entities with similar semantics may have dissimilar embeddings. This property of inner products significantly limits the performance of semantic matching models. To address this challenge, we propose a novel regularizer -- namely, DUality-induced RegulArizer (DURA) -- which effectively encourages the entities with similar semantics to have similar embeddings. The major novelty of DURA is based on the observation that, for an existing semantic matching KGE model (primal), there is often another distance based KGE model (dual) closely associated with it, which can be used as effective constraints for entity embeddings. Experiments demonstrate that DURA consistently and significantly improves the performance of state-of-the-art semantic matching models on both static and temporal knowledge graph benchmarks.
Rethinking Graph Convolutional Networks in Knowledge Graph Completion
Feb 08, 2022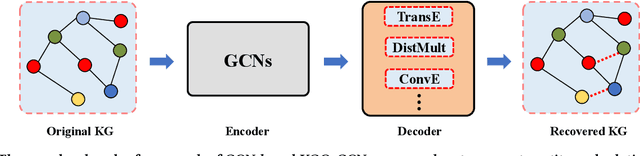

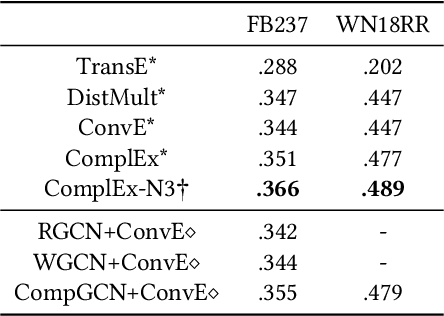
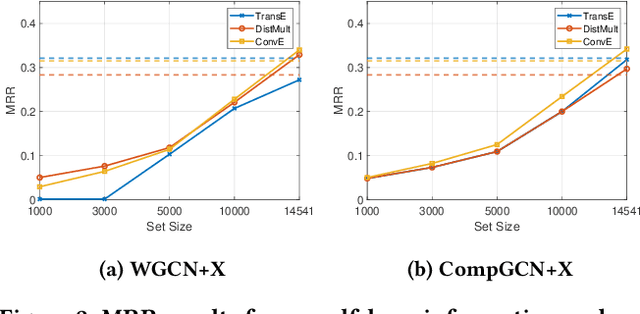
Graph convolutional networks (GCNs) -- which are effective in modeling graph structures -- have been increasingly popular in knowledge graph completion (KGC). GCN-based KGC models first use GCNs to generate expressive entity representations and then use knowledge graph embedding (KGE) models to capture the interactions among entities and relations. However, many GCN-based KGC models fail to outperform state-of-the-art KGE models though introducing additional computational complexity. This phenomenon motivates us to explore the real effect of GCNs in KGC. Therefore, in this paper, we build upon representative GCN-based KGC models and introduce variants to find which factor of GCNs is critical in KGC. Surprisingly, we observe from experiments that the graph structure modeling in GCNs does not have a significant impact on the performance of KGC models, which is in contrast to the common belief. Instead, the transformations for entity representations are responsible for the performance improvements. Based on the observation, we propose a simple yet effective framework named LTE-KGE, which equips existing KGE models with linearly transformed entity embeddings. Experiments demonstrate that LTE-KGE models lead to similar performance improvements with GCN-based KGC methods, while being more computationally efficient. These results suggest that existing GCNs are unnecessary for KGC, and novel GCN-based KGC models should count on more ablation studies to validate their effectiveness. The code of all the experiments is available on GitHub at https://github.com/MIRALab-USTC/GCN4KGC.
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs
Oct 26, 2021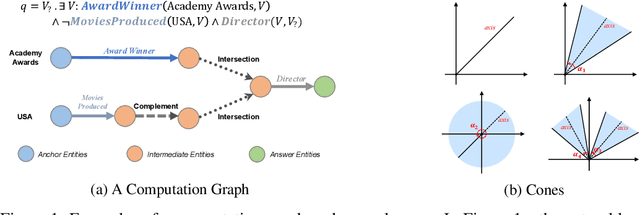
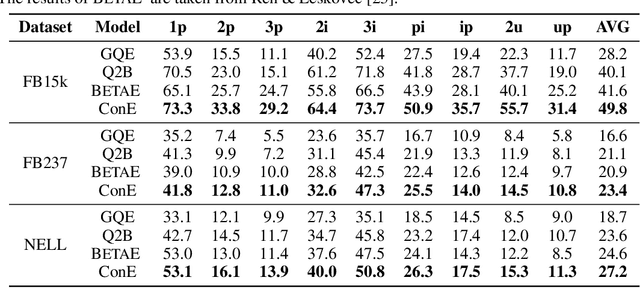
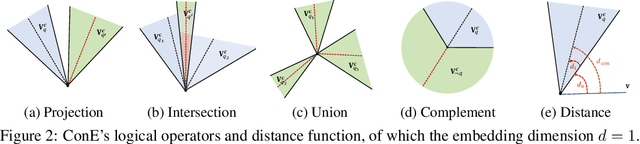
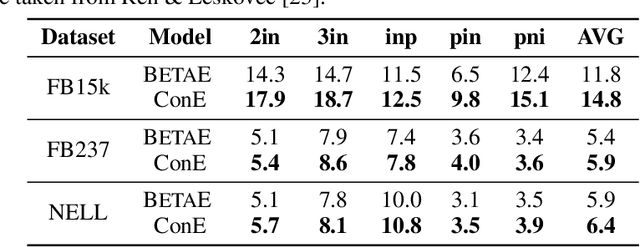
Query embedding (QE) -- which aims to embed entities and first-order logical (FOL) queries in low-dimensional spaces -- has shown great power in multi-hop reasoning over knowledge graphs. Recently, embedding entities and queries with geometric shapes becomes a promising direction, as geometric shapes can naturally represent answer sets of queries and logical relationships among them. However, existing geometry-based models have difficulty in modeling queries with negation, which significantly limits their applicability. To address this challenge, we propose a novel query embedding model, namely Cone Embeddings (ConE), which is the first geometry-based QE model that can handle all the FOL operations, including conjunction, disjunction, and negation. Specifically, ConE represents entities and queries as Cartesian products of two-dimensional cones, where the intersection and union of cones naturally model the conjunction and disjunction operations. By further noticing that the closure of complement of cones remains cones, we design geometric complement operators in the embedding space for the negation operations. Experiments demonstrate that ConE significantly outperforms existing state-of-the-art methods on benchmark datasets.
Technical Report of Team GraphMIRAcles in the WikiKG90M-LSC Track of OGB-LSC @ KDD Cup 2021
Jul 12, 2021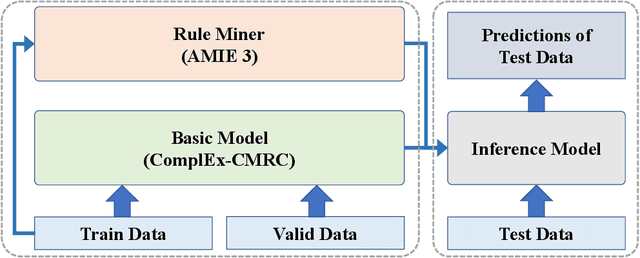

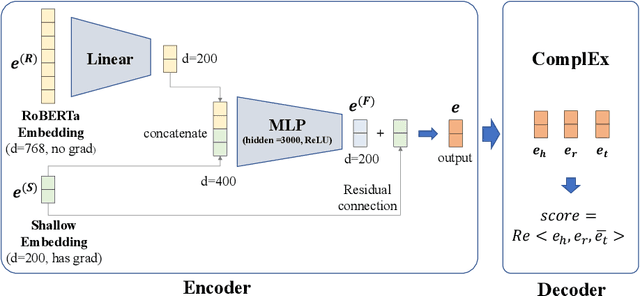

Link prediction in large-scale knowledge graphs has gained increasing attention recently. The OGB-LSC team presented OGB Large-Scale Challenge (OGB-LSC), a collection of three real-world datasets for advancing the state-of-the-art in large-scale graph machine learning. In this paper, we introduce the solution of our team GraphMIRAcles in the WikiKG90M-LSC track of OGB-LSC @ KDD Cup 2021. In the WikiKG90M-LSC track, the goal is to automatically predict missing links in WikiKG90M, a large scale knowledge graph extracted from Wikidata. To address this challenge, we propose a framework that integrates three components -- a basic model ComplEx-CMRC, a rule miner AMIE 3, and an inference model to predict missing links. Experiments demonstrate that our solution achieves an MRR of 0.9707 on the test dataset. Moreover, as the knowledge distillation in the inference model uses test tail candidates -- which are unavailable in practice -- we conduct ablation studies on knowledge distillation. Experiments demonstrate that our model without knowledge distillation achieves an MRR of 0.9533 on the full validation dataset.