 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Adaptive Label Augmentation for Semi-supervised Few-shot Classification
Jun 16, 2022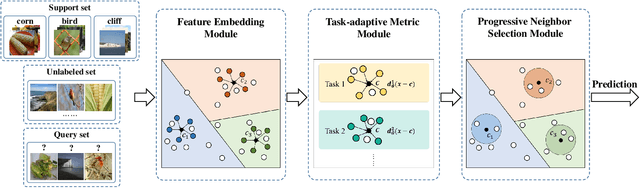
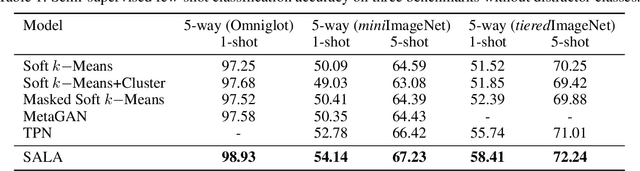
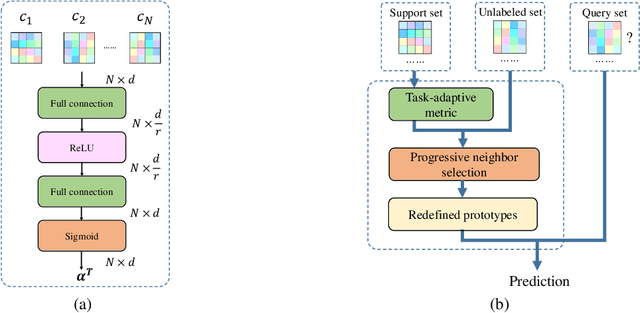
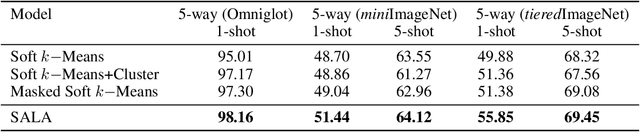
Few-shot classification aims to learn a model that can generalize well to new tasks when only a few labeled samples are available. To make use of unlabeled data that are more abundantly available in real applications, Ren et al. \shortcite{ren2018meta} propose a semi-supervised few-shot classification method that assigns an appropriate label to each unlabeled sample by a manually defined metric. However, the manually defined metric fails to capture the intrinsic property in data. In this paper, we propose a \textbf{S}elf-\textbf{A}daptive \textbf{L}abel \textbf{A}ugmentation approach, called \textbf{SALA}, for semi-supervised few-shot classification. A major novelty of SALA is the task-adaptive metric, which can learn the metric adaptively for different tasks in an end-to-end fashion. Another appealing feature of SALA is a progressive neighbor selection strategy, which selects unlabeled data with high confidence progressively through the training phase. Experiments demonstrate that SALA outperforms several state-of-the-art methods for semi-supervised few-shot classification on benchmark datasets.
Duality-Induced Regularizer for Semantic Matching Knowledge Graph Embeddings
Apr 06, 2022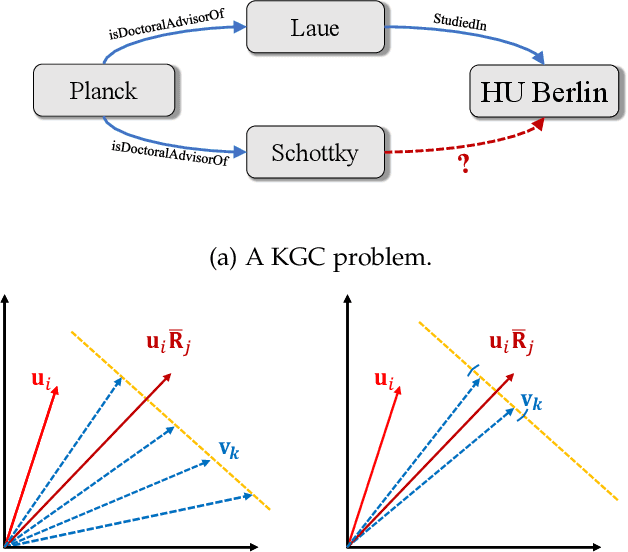

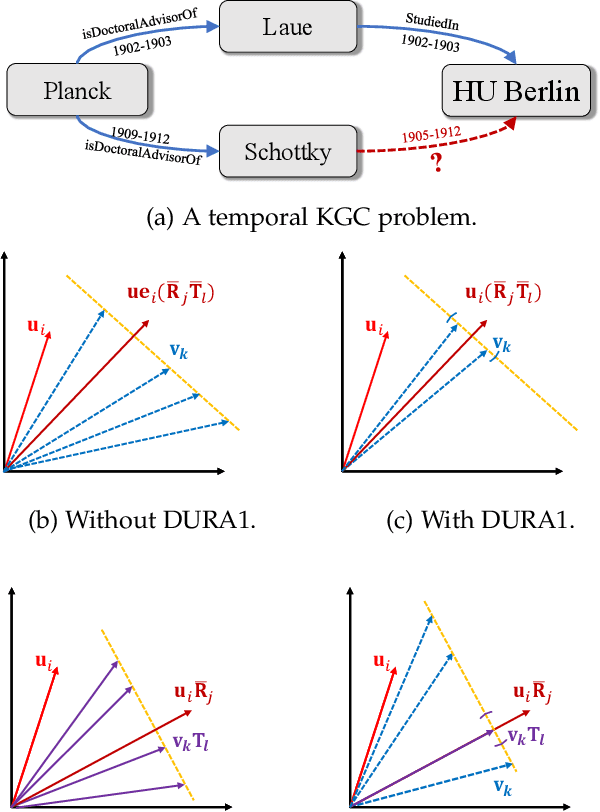
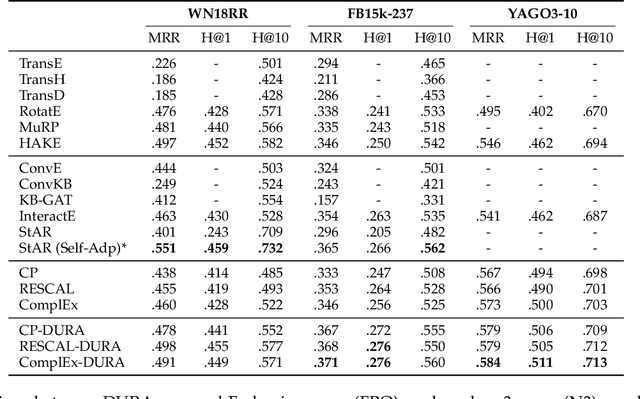
Semantic matching models -- which assume that entities with similar semantics have similar embeddings -- have shown great power in knowledge graph embeddings (KGE). Many existing semantic matching models use inner products in embedding spaces to measure the plausibility of triples and quadruples in static and temporal knowledge graphs. However, vectors that have the same inner products with another vector can still be orthogonal to each other, which implies that entities with similar semantics may have dissimilar embeddings. This property of inner products significantly limits the performance of semantic matching models. To address this challenge, we propose a novel regularizer -- namely, DUality-induced RegulArizer (DURA) -- which effectively encourages the entities with similar semantics to have similar embeddings. The major novelty of DURA is based on the observation that, for an existing semantic matching KGE model (primal), there is often another distance based KGE model (dual) closely associated with it, which can be used as effective constraints for entity embeddings. Experiments demonstrate that DURA consistently and significantly improves the performance of state-of-the-art semantic matching models on both static and temporal knowledge graph benchmarks.
Technical Report of Team GraphMIRAcles in the WikiKG90M-LSC Track of OGB-LSC @ KDD Cup 2021
Jul 12, 2021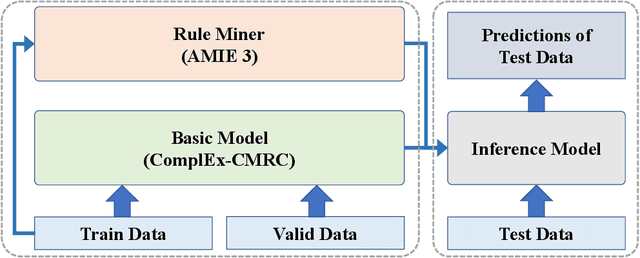

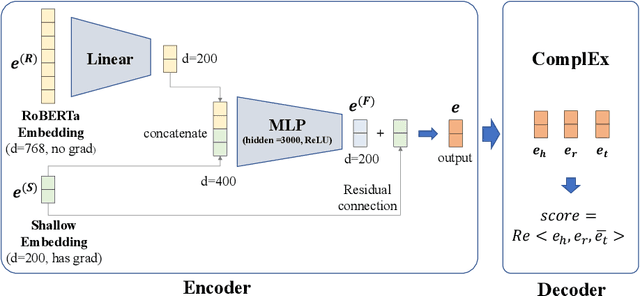

Link prediction in large-scale knowledge graphs has gained increasing attention recently. The OGB-LSC team presented OGB Large-Scale Challenge (OGB-LSC), a collection of three real-world datasets for advancing the state-of-the-art in large-scale graph machine learning. In this paper, we introduce the solution of our team GraphMIRAcles in the WikiKG90M-LSC track of OGB-LSC @ KDD Cup 2021. In the WikiKG90M-LSC track, the goal is to automatically predict missing links in WikiKG90M, a large scale knowledge graph extracted from Wikidata. To address this challenge, we propose a framework that integrates three components -- a basic model ComplEx-CMRC, a rule miner AMIE 3, and an inference model to predict missing links. Experiments demonstrate that our solution achieves an MRR of 0.9707 on the test dataset. Moreover, as the knowledge distillation in the inference model uses test tail candidates -- which are unavailable in practice -- we conduct ablation studies on knowledge distillation. Experiments demonstrate that our model without knowledge distillation achieves an MRR of 0.9533 on the full validation dataset.
Duality-Induced Regularizer for Tensor Factorization Based Knowledge Graph Completion
Nov 11, 2020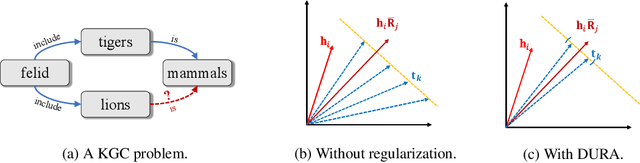
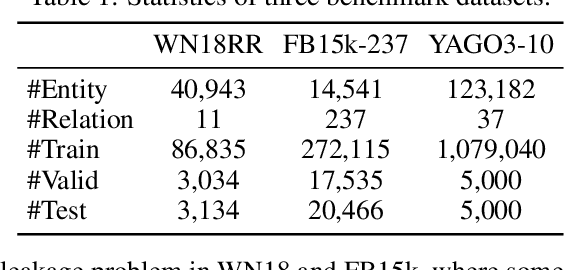
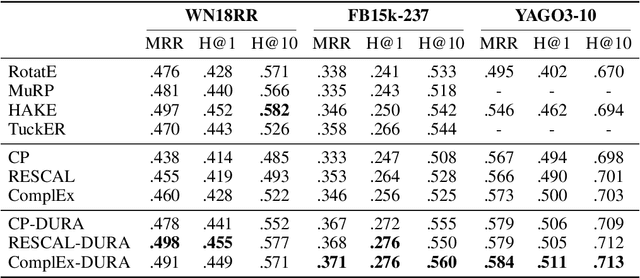
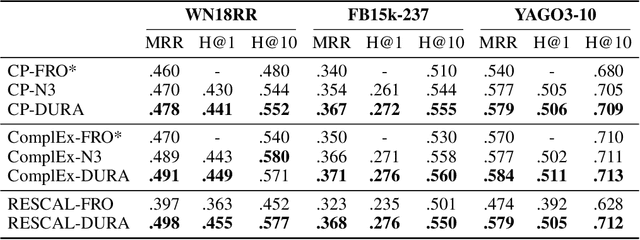
Tensor factorization based models have shown great power in knowledge graph completion (KGC). However, their performance usually suffers from the overfitting problem seriously. This motivates various regularizers---such as the squared Frobenius norm and tensor nuclear norm regularizers---while the limited applicability significantly limits their practical usage. To address this challenge, we propose a novel regularizer---namely, DUality-induced RegulArizer (DURA)---which is not only effective in improving the performance of existing models but widely applicable to various methods. The major novelty of DURA is based on the observation that, for an existing tensor factorization based KGC model (primal), there is often another distance based KGC model (dual) closely associated with it. Experiments show that DURA yields consistent and significant improvements on benchmarks.
Learning Hierarchy-Aware Knowledge Graph Embeddings for Link Prediction
Dec 25, 2019

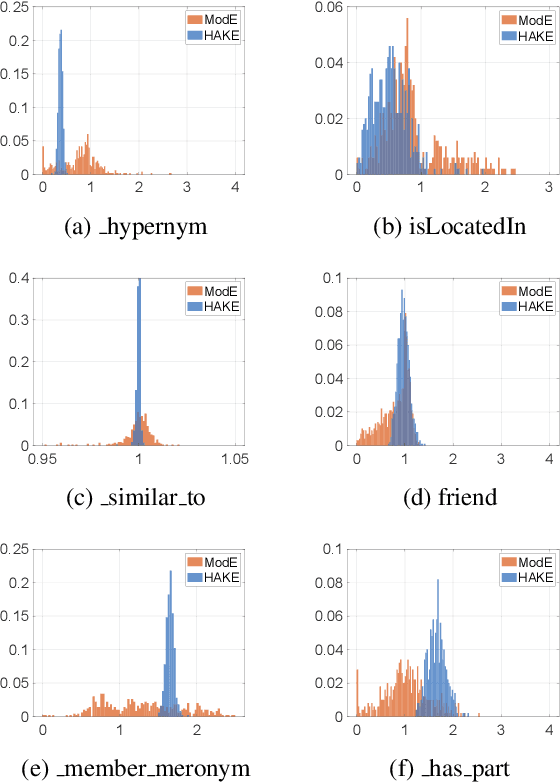
Knowledge graph embedding, which aims to represent entities and relations as low dimensional vectors (or matrices, tensors, etc.), has been shown to be a powerful technique for predicting missing links in knowledge graphs. Existing knowledge graph embedding models mainly focus on modeling relation patterns such as symmetry/antisymmetry, inversion, and composition. However, many existing approaches fail to model semantic hierarchies, which are common in real-world applications. To address this challenge, we propose a novel knowledge graph embedding model---namely, Hierarchy-Aware Knowledge Graph Embedding (HAKE)---which maps entities into the polar coordinate system. HAKE is inspired by the fact that concentric circles in the polar coordinate system can naturally reflect the hierarchy. Specifically, the radial coordinate aims to model entities at different levels of the hierarchy, and entities with smaller radii are expected to be at higher levels; the angular coordinate aims to distinguish entities at the same level of the hierarchy, and these entities are expected to have roughly the same radii but different angles. Experiments demonstrate that HAKE can effectively model the semantic hierarchies in knowledge graphs, and significantly outperforms existing state-of-the-art methods on benchmark datasets for the link prediction task.