 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025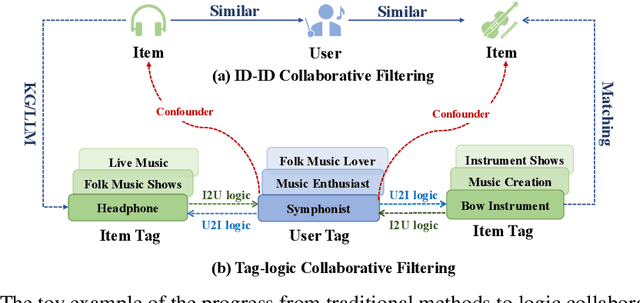
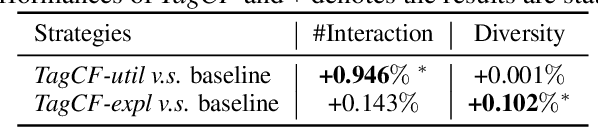
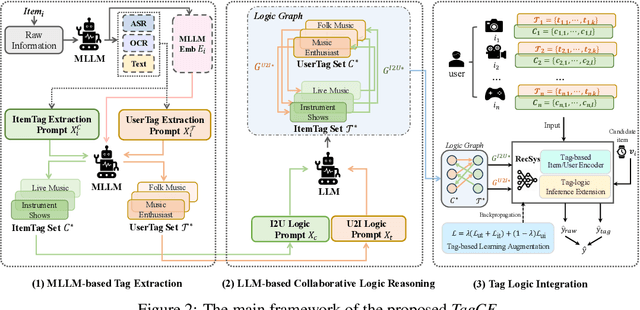
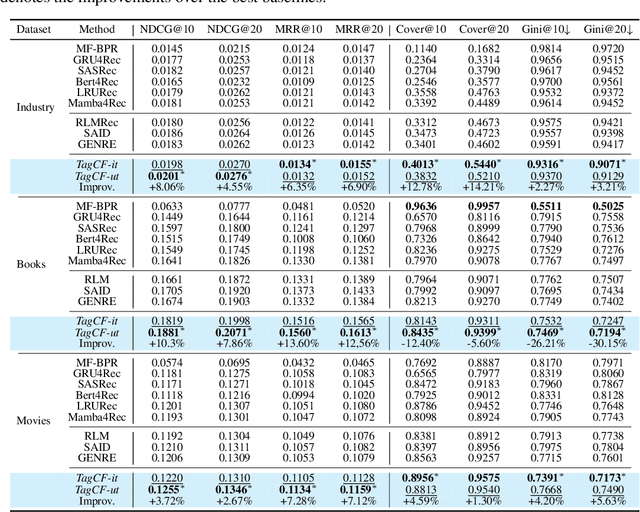
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
Coarse-to-fine Dynamic Uplift Modeling for Real-time Video Recommendation
Oct 22, 2024With the rise of short video platforms, video recommendation technology faces more complex challenges. Currently, there are multiple non-personalized modules in the video recommendation pipeline that urgently need personalized modeling techniques for improvement. Inspired by the success of uplift modeling in online marketing, we attempt to implement uplift modeling in the video recommendation scenario. However, we face two main challenges: 1) Design and utilization of treatments, and 2) Capture of user real-time interest. To address them, we design adjusting the distribution of videos with varying durations as the treatment and propose Coarse-to-fine Dynamic Uplift Modeling (CDUM) for real-time video recommendation. CDUM consists of two modules, CPM and FIC. The former module fully utilizes the offline features of users to model their long-term preferences, while the latter module leverages online real-time contextual features and request-level candidates to model users' real-time interests. These two modules work together to dynamically identify and targeting specific user groups and applying treatments effectively. Further, we conduct comprehensive experiments on the offline public and industrial datasets and online A/B test, demonstrating the superiority and effectiveness of our proposed CDUM. Our proposed CDUM is eventually fully deployed on the Kuaishou platform, serving hundreds of millions of users every day. The source code will be provided after the paper is accepted.
Future Impact Decomposition in Request-level Recommendations
Feb 07, 2024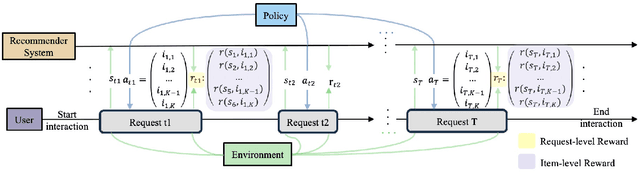
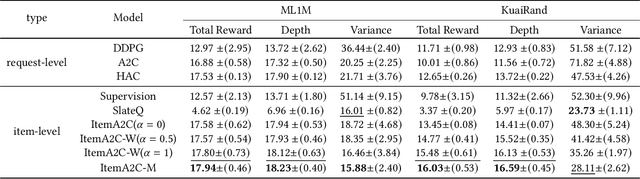
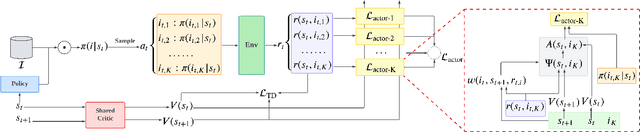
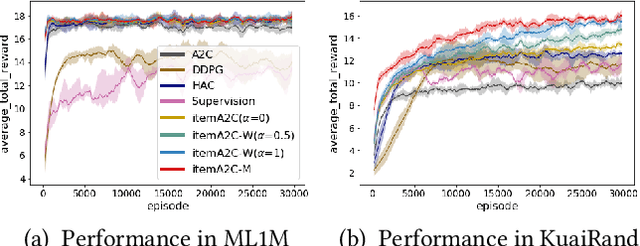
In recommender systems, reinforcement learning solutions have shown promising results in optimizing the interaction sequence between users and the system over the long-term performance. For practical reasons, the policy's actions are typically designed as recommending a list of items to handle users' frequent and continuous browsing requests more efficiently. In this list-wise recommendation scenario, the user state is updated upon every request in the corresponding MDP formulation. However, this request-level formulation is essentially inconsistent with the user's item-level behavior. In this study, we demonstrate that an item-level optimization approach can better utilize item characteristics and optimize the policy's performance even under the request-level MDP. We support this claim by comparing the performance of standard request-level methods with the proposed item-level actor-critic framework in both simulation and online experiments. Furthermore, we show that a reward-based future decomposition strategy can better express the item-wise future impact and improve the recommendation accuracy in the long term. To achieve a more thorough understanding of the decomposition strategy, we propose a model-based re-weighting framework with adversarial learning that further boost the performance and investigate its correlation with the reward-based strategy.
Reinforcing User Retention in a Billion Scale Short Video Recommender System
Feb 12, 2023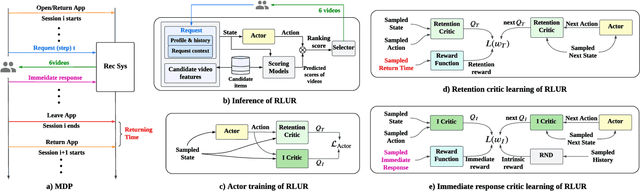
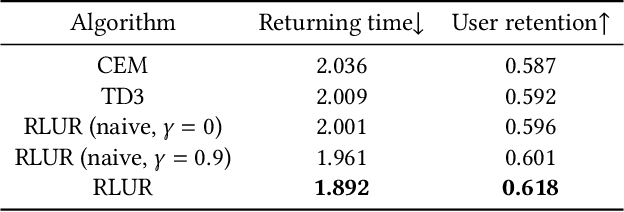
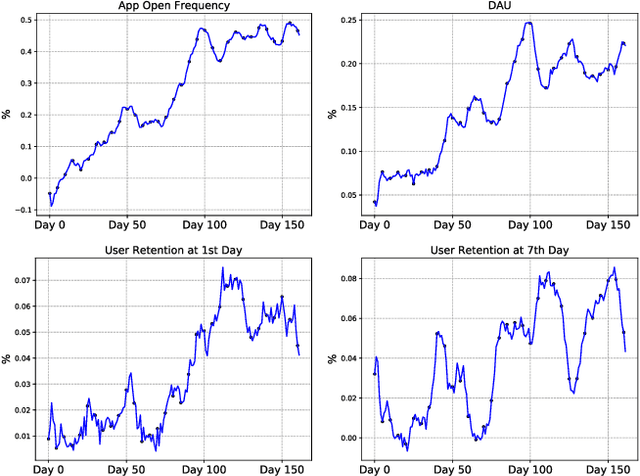
Recently, short video platforms have achieved rapid user growth by recommending interesting content to users. The objective of the recommendation is to optimize user retention, thereby driving the growth of DAU (Daily Active Users). Retention is a long-term feedback after multiple interactions of users and the system, and it is hard to decompose retention reward to each item or a list of items. Thus traditional point-wise and list-wise models are not able to optimize retention. In this paper, we choose reinforcement learning methods to optimize the retention as they are designed to maximize the long-term performance. We formulate the problem as an infinite-horizon request-based Markov Decision Process, and our objective is to minimize the accumulated time interval of multiple sessions, which is equal to improving the app open frequency and user retention. However, current reinforcement learning algorithms can not be directly applied in this setting due to uncertainty, bias, and long delay time incurred by the properties of user retention. We propose a novel method, dubbed RLUR, to address the aforementioned challenges. Both offline and live experiments show that RLUR can significantly improve user retention. RLUR has been fully launched in Kuaishou app for a long time, and achieves consistent performance improvement on user retention and DAU.
Two-Stage Constrained Actor-Critic for Short Video Recommendation
Feb 06, 2023
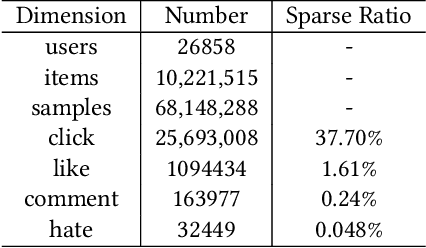
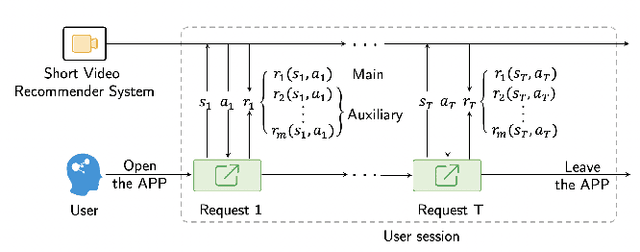
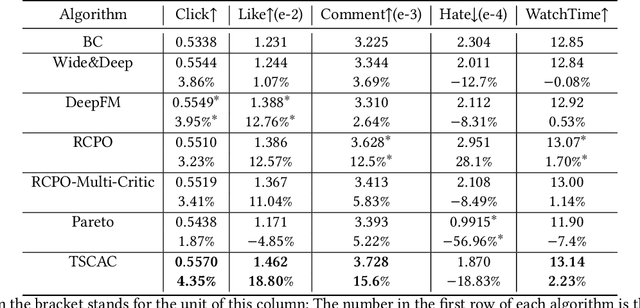
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users sequentially interact with the system and provide complex and multi-faceted responses, including watch time and various types of interactions with multiple videos. One the one hand, the platforms aims at optimizing the users' cumulative watch time (main goal) in long term, which can be effectively optimized by Reinforcement Learning. On the other hand, the platforms also needs to satisfy the constraint of accommodating the responses of multiple user interactions (auxiliary goals) such like, follow, share etc. In this paper, we formulate the problem of short video recommendation as a Constrained Markov Decision Process (CMDP). We find that traditional constrained reinforcement learning algorithms can not work well in this setting. We propose a novel two-stage constrained actor-critic method: At stage one, we learn individual policies to optimize each auxiliary signal. At stage two, we learn a policy to (i) optimize the main signal and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive offline evaluations, we demonstrate effectiveness of our method over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our method in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of both watch time and interactions. Our approach has been fully launched in the production system to optimize user experiences on the platform.
* arXiv admin note: substantial text overlap with arXiv:2205.13248
Self-Adaptive Label Augmentation for Semi-supervised Few-shot Classification
Jun 16, 2022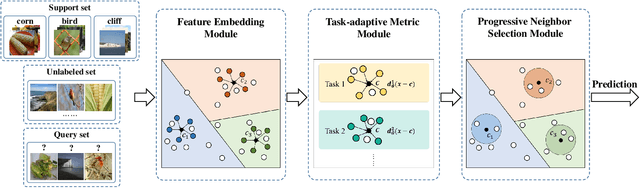
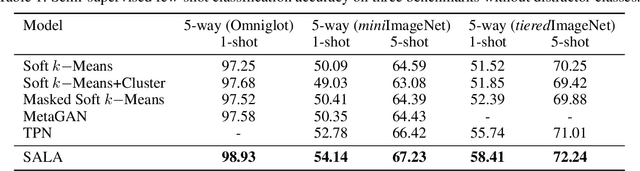
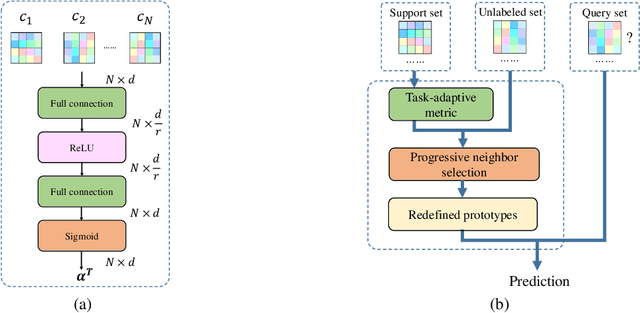
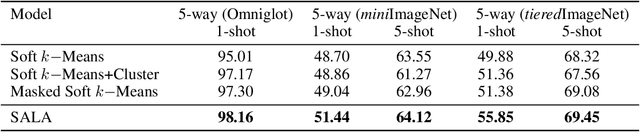
Few-shot classification aims to learn a model that can generalize well to new tasks when only a few labeled samples are available. To make use of unlabeled data that are more abundantly available in real applications, Ren et al. \shortcite{ren2018meta} propose a semi-supervised few-shot classification method that assigns an appropriate label to each unlabeled sample by a manually defined metric. However, the manually defined metric fails to capture the intrinsic property in data. In this paper, we propose a \textbf{S}elf-\textbf{A}daptive \textbf{L}abel \textbf{A}ugmentation approach, called \textbf{SALA}, for semi-supervised few-shot classification. A major novelty of SALA is the task-adaptive metric, which can learn the metric adaptively for different tasks in an end-to-end fashion. Another appealing feature of SALA is a progressive neighbor selection strategy, which selects unlabeled data with high confidence progressively through the training phase. Experiments demonstrate that SALA outperforms several state-of-the-art methods for semi-supervised few-shot classification on benchmark datasets.
Exploiting Global Semantic Similarities in Knowledge Graphs by Relational Prototype Entities
Jun 16, 2022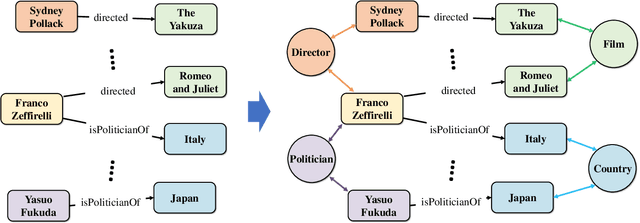
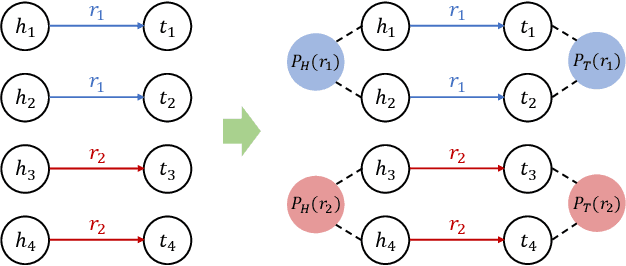
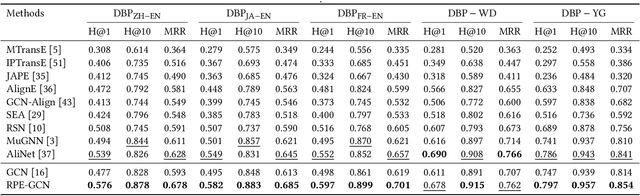
Knowledge graph (KG) embedding aims at learning the latent representations for entities and relations of a KG in continuous vector spaces. An empirical observation is that the head (tail) entities connected by the same relation often share similar semantic attributes -- specifically, they often belong to the same category -- no matter how far away they are from each other in the KG; that is, they share global semantic similarities. However, many existing methods derive KG embeddings based on the local information, which fail to effectively capture such global semantic similarities among entities. To address this challenge, we propose a novel approach, which introduces a set of virtual nodes called \textit{\textbf{relational prototype entities}} to represent the prototypes of the head and tail entities connected by the same relations. By enforcing the entities' embeddings close to their associated prototypes' embeddings, our approach can effectively encourage the global semantic similarities of entities -- that can be far away in the KG -- connected by the same relation. Experiments on the entity alignment and KG completion tasks demonstrate that our approach significantly outperforms recent state-of-the-arts.
Deconfounding Duration Bias in Watch-time Prediction for Video Recommendation
Jun 13, 2022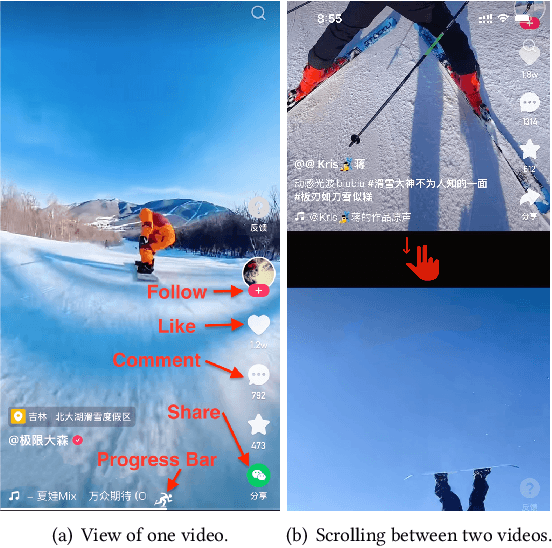

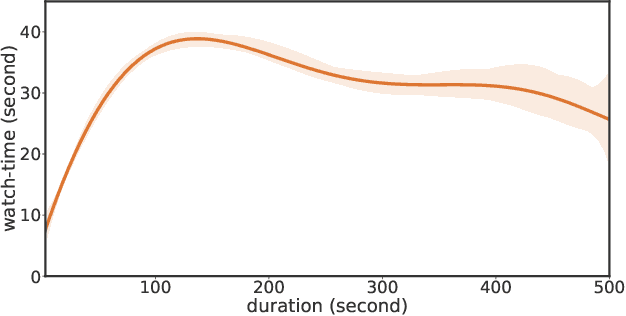
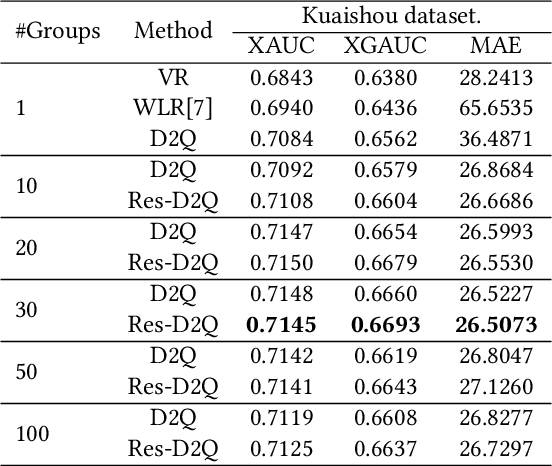
Watch-time prediction remains to be a key factor in reinforcing user engagement via video recommendations. It has become increasingly important given the ever-growing popularity of online videos. However, prediction of watch time not only depends on the match between the user and the video but is often mislead by the duration of the video itself. With the goal of improving watch time, recommendation is always biased towards videos with long duration. Models trained on this imbalanced data face the risk of bias amplification, which misguides platforms to over-recommend videos with long duration but overlook the underlying user interests. This paper presents the first work to study duration bias in watch-time prediction for video recommendation. We employ a causal graph illuminating that duration is a confounding factor that concurrently affects video exposure and watch-time prediction -- the first effect on video causes the bias issue and should be eliminated, while the second effect on watch time originates from video intrinsic characteristics and should be preserved. To remove the undesired bias but leverage the natural effect, we propose a Duration Deconfounded Quantile-based (D2Q) watch-time prediction framework, which allows for scalability to perform on industry production systems. Through extensive offline evaluation and live experiments, we showcase the effectiveness of this duration-deconfounding framework by significantly outperforming the state-of-the-art baselines. We have fully launched our approach on Kuaishou App, which has substantially improved real-time video consumption due to more accurate watch-time predictions.