 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoalRank: Group-Relative Optimization for a Large Ranking Model
Sep 26, 2025Mainstream ranking approaches typically follow a Generator-Evaluator two-stage paradigm, where a generator produces candidate lists and an evaluator selects the best one. Recent work has attempted to enhance performance by expanding the number of candidate lists, for example, through multi-generator settings. However, ranking involves selecting a recommendation list from a combinatorially large space. Simply enlarging the candidate set remains ineffective, and performance gains quickly saturate. At the same time, recent advances in large recommendation models have shown that end-to-end one-stage models can achieve promising performance with the expectation of scaling laws. Motivated by this, we revisit ranking from a generator-only one-stage perspective. We theoretically prove that, for any (finite Multi-)Generator-Evaluator model, there always exists a generator-only model that achieves strictly smaller approximation error to the optimal ranking policy, while also enjoying scaling laws as its size increases. Building on this result, we derive an evidence upper bound of the one-stage optimization objective, from which we find that one can leverage a reward model trained on real user feedback to construct a reference policy in a group-relative manner. This reference policy serves as a practical surrogate of the optimal policy, enabling effective training of a large generator-only ranker. Based on these insights, we propose GoalRank, a generator-only ranking framework. Extensive offline experiments on public benchmarks and large-scale online A/B tests demonstrate that GoalRank consistently outperforms state-of-the-art methods.
Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025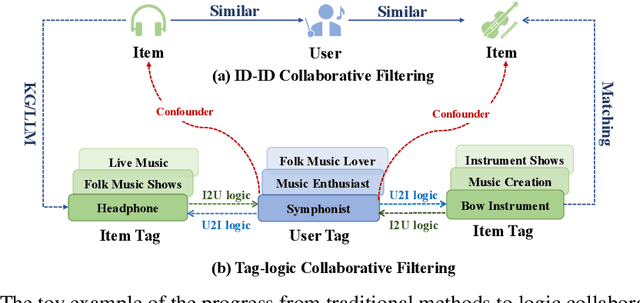
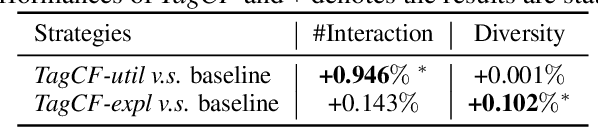
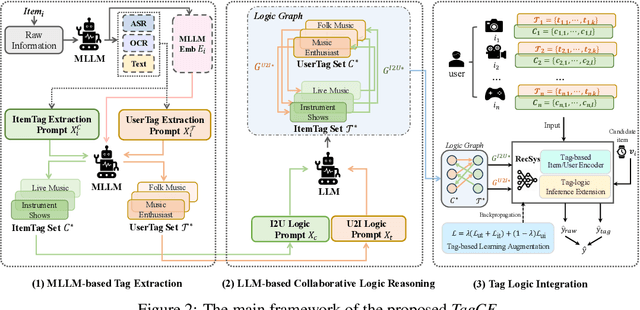
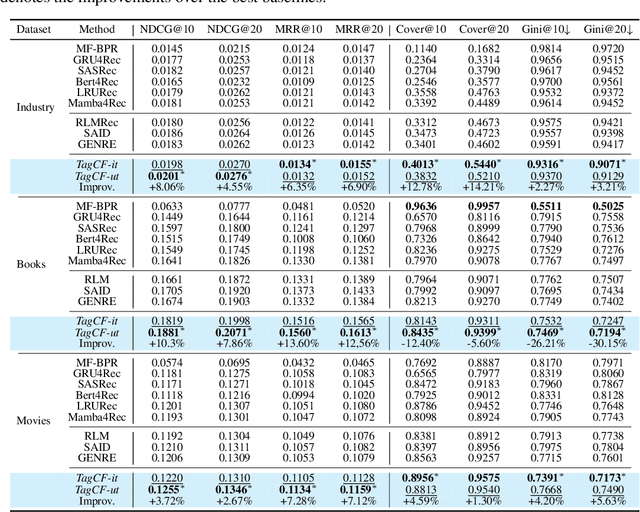
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
Comprehensive List Generation for Multi-Generator Reranking
Apr 22, 2025Reranking models solve the final recommendation lists that best fulfill users' demands. While existing solutions focus on finding parametric models that approximate optimal policies, recent approaches find that it is better to generate multiple lists to compete for a ``pass'' ticket from an evaluator, where the evaluator serves as the supervisor who accurately estimates the performance of the candidate lists. In this work, we show that we can achieve a more efficient and effective list proposal with a multi-generator framework and provide empirical evidence on two public datasets and online A/B tests. More importantly, we verify that the effectiveness of a generator is closely related to how much it complements the views of other generators with sufficiently different rerankings, which derives the metric of list comprehensiveness. With this intuition, we design an automatic complementary generator-finding framework that learns a policy that simultaneously aligns the users' preferences and maximizes the list comprehensiveness metric. The experimental results indicate that the proposed framework can further improve the multi-generator reranking performance.
* 11 pages, 6 figures, 9 tables
VLM as Policy: Common-Law Content Moderation Framework for Short Video Platform
Apr 21, 2025Exponentially growing short video platforms (SVPs) face significant challenges in moderating content detrimental to users' mental health, particularly for minors. The dissemination of such content on SVPs can lead to catastrophic societal consequences. Although substantial efforts have been dedicated to moderating such content, existing methods suffer from critical limitations: (1) Manual review is prone to human bias and incurs high operational costs. (2) Automated methods, though efficient, lack nuanced content understanding, resulting in lower accuracy. (3) Industrial moderation regulations struggle to adapt to rapidly evolving trends due to long update cycles. In this paper, we annotate the first SVP content moderation benchmark with authentic user/reviewer feedback to fill the absence of benchmark in this field. Then we evaluate various methods on the benchmark to verify the existence of the aforementioned limitations. We further propose our common-law content moderation framework named KuaiMod to address these challenges. KuaiMod consists of three components: training data construction, offline adaptation, and online deployment & refinement. Leveraging large vision language model (VLM) and Chain-of-Thought (CoT) reasoning, KuaiMod adequately models video toxicity based on sparse user feedback and fosters dynamic moderation policy with rapid update speed and high accuracy. Offline experiments and large-scale online A/B test demonstrates the superiority of KuaiMod: KuaiMod achieves the best moderation performance on our benchmark. The deployment of KuaiMod reduces the user reporting rate by 20% and its application in video recommendation increases both Daily Active User (DAU) and APP Usage Time (AUT) on several Kuaishou scenarios. We have open-sourced our benchmark at https://kuaimod.github.io.
Value Function Decomposition in Markov Recommendation Process
Jan 29, 2025



Recent advances in recommender systems have shown that user-system interaction essentially formulates long-term optimization problems, and online reinforcement learning can be adopted to improve recommendation performance. The general solution framework incorporates a value function that estimates the user's expected cumulative rewards in the future and guides the training of the recommendation policy. To avoid local maxima, the policy may explore potential high-quality actions during inference to increase the chance of finding better future rewards. To accommodate the stepwise recommendation process, one widely adopted approach to learning the value function is learning from the difference between the values of two consecutive states of a user. However, we argue that this paradigm involves an incorrect approximation in the stochastic process. Specifically, between the current state and the next state in each training sample, there exist two separate random factors from the stochastic policy and the uncertain user environment. Original temporal difference (TD) learning under these mixed random factors may result in a suboptimal estimation of the long-term rewards. As a solution, we show that these two factors can be separately approximated by decomposing the original temporal difference loss. The disentangled learning framework can achieve a more accurate estimation with faster learning and improved robustness against action exploration. As empirical verification of our proposed method, we conduct offline experiments with online simulated environments built based on public datasets.
Future Impact Decomposition in Request-level Recommendations
Feb 07, 2024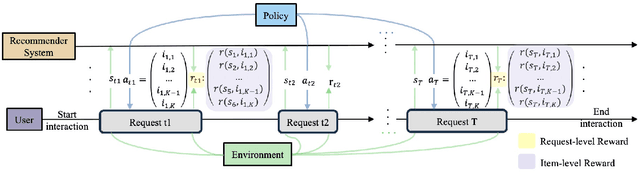
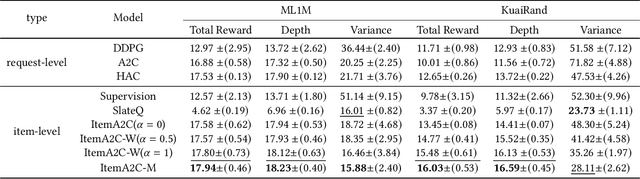
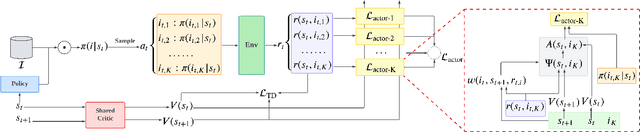
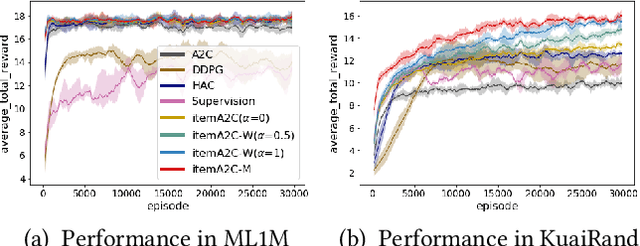
In recommender systems, reinforcement learning solutions have shown promising results in optimizing the interaction sequence between users and the system over the long-term performance. For practical reasons, the policy's actions are typically designed as recommending a list of items to handle users' frequent and continuous browsing requests more efficiently. In this list-wise recommendation scenario, the user state is updated upon every request in the corresponding MDP formulation. However, this request-level formulation is essentially inconsistent with the user's item-level behavior. In this study, we demonstrate that an item-level optimization approach can better utilize item characteristics and optimize the policy's performance even under the request-level MDP. We support this claim by comparing the performance of standard request-level methods with the proposed item-level actor-critic framework in both simulation and online experiments. Furthermore, we show that a reward-based future decomposition strategy can better express the item-wise future impact and improve the recommendation accuracy in the long term. To achieve a more thorough understanding of the decomposition strategy, we propose a model-based re-weighting framework with adversarial learning that further boost the performance and investigate its correlation with the reward-based strategy.