 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Structure and Appearance: Topological Features for Robust Self-Supervised Segmentation
Dec 30, 2025Self-supervised semantic segmentation methods often fail when faced with appearance ambiguities. We argue that this is due to an over-reliance on unstable, appearance-based features such as shadows, glare, and local textures. We propose \textbf{GASeg}, a novel framework that bridges appearance and geometry by leveraging stable topological information. The core of our method is Differentiable Box-Counting (\textbf{DBC}) module, which quantifies multi-scale topological statistics from two parallel streams: geometric-based features and appearance-based features. To force the model to learn these stable structural representations, we introduce Topological Augmentation (\textbf{TopoAug}), an adversarial strategy that simulates real-world ambiguities by applying morphological operators to the input images. A multi-objective loss, \textbf{GALoss}, then explicitly enforces cross-modal alignment between geometric-based and appearance-based features. Extensive experiments demonstrate that GASeg achieves state-of-the-art performance on four benchmarks, including COCO-Stuff, Cityscapes, and PASCAL, validating our approach of bridging geometry and appearance via topological information.
Comprehensive List Generation for Multi-Generator Reranking
Apr 22, 2025Reranking models solve the final recommendation lists that best fulfill users' demands. While existing solutions focus on finding parametric models that approximate optimal policies, recent approaches find that it is better to generate multiple lists to compete for a ``pass'' ticket from an evaluator, where the evaluator serves as the supervisor who accurately estimates the performance of the candidate lists. In this work, we show that we can achieve a more efficient and effective list proposal with a multi-generator framework and provide empirical evidence on two public datasets and online A/B tests. More importantly, we verify that the effectiveness of a generator is closely related to how much it complements the views of other generators with sufficiently different rerankings, which derives the metric of list comprehensiveness. With this intuition, we design an automatic complementary generator-finding framework that learns a policy that simultaneously aligns the users' preferences and maximizes the list comprehensiveness metric. The experimental results indicate that the proposed framework can further improve the multi-generator reranking performance.
* 11 pages, 6 figures, 9 tables
LAA-Net: A Physical-prior-knowledge Based Network for Robust Nighttime Depth Estimation
Dec 05, 2024



Existing self-supervised monocular depth estimation (MDE) models attempt to improve nighttime performance by using GANs to transfer nighttime images into their daytime versions. However, this can introduce inconsistencies due to the complexities of real-world daytime lighting variations, which may finally lead to inaccurate estimation results. To address this issue, we leverage physical-prior-knowledge about light wavelength and light attenuation during nighttime. Specifically, our model, Light-Attenuation-Aware Network (LAA-Net), incorporates physical insights from Rayleigh scattering theory for robust nighttime depth estimation: LAA-Net is trained based on red channel values because red light preserves more information under nighttime scenarios due to its longer wavelength. Additionally, based on Beer-Lambert law, we introduce Red Channel Attenuation (RCA) loss to guide LAA-Net's training. Experiments on the RobotCar-Night, nuScenes-Night, RobotCar-Day, and KITTI datasets demonstrate that our model outperforms SOTA models.
Text Classification Improved by Integrating Bidirectional LSTM with Two-dimensional Max Pooling
Nov 21, 2016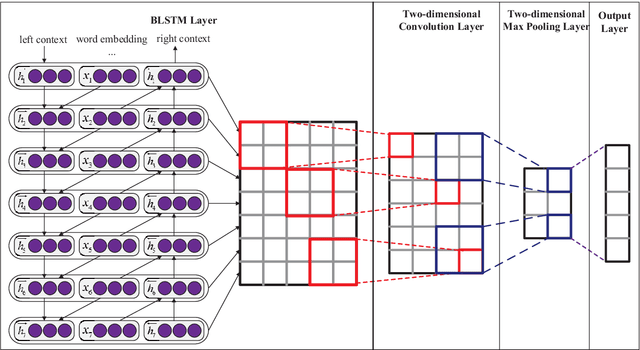
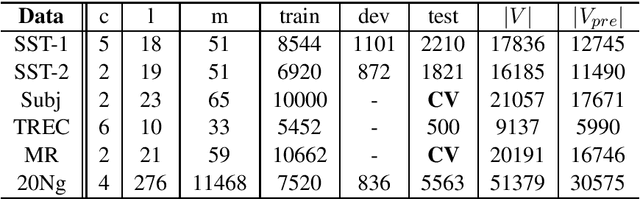
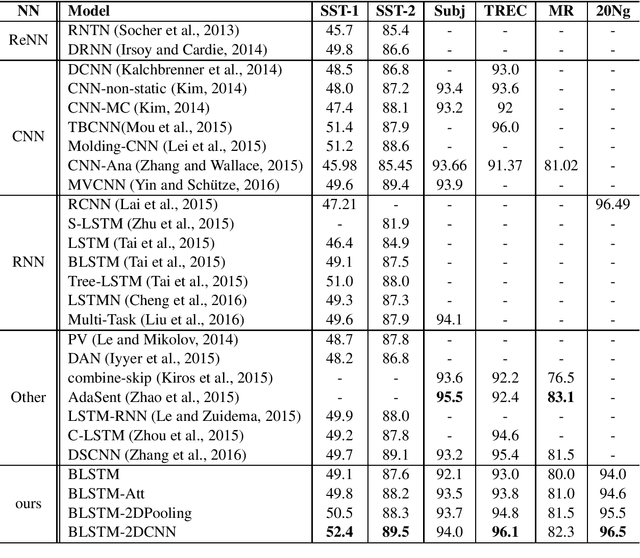
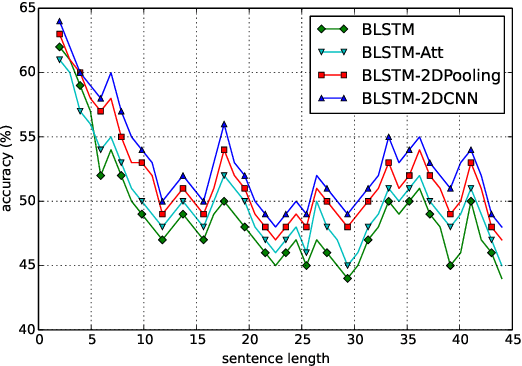
Recurrent Neural Network (RNN) is one of the most popular architectures used in Natural Language Processsing (NLP) tasks because its recurrent structure is very suitable to process variable-length text. RNN can utilize distributed representations of words by first converting the tokens comprising each text into vectors, which form a matrix. And this matrix includes two dimensions: the time-step dimension and the feature vector dimension. Then most existing models usually utilize one-dimensional (1D) max pooling operation or attention-based operation only on the time-step dimension to obtain a fixed-length vector. However, the features on the feature vector dimension are not mutually independent, and simply applying 1D pooling operation over the time-step dimension independently may destroy the structure of the feature representation. On the other hand, applying two-dimensional (2D) pooling operation over the two dimensions may sample more meaningful features for sequence modeling tasks. To integrate the features on both dimensions of the matrix, this paper explores applying 2D max pooling operation to obtain a fixed-length representation of the text. This paper also utilizes 2D convolution to sample more meaningful information of the matrix. Experiments are conducted on six text classification tasks, including sentiment analysis, question classification, subjectivity classification and newsgroup classification. Compared with the state-of-the-art models, the proposed models achieve excellent performance on 4 out of 6 tasks. Specifically, one of the proposed models achieves highest accuracy on Stanford Sentiment Treebank binary classification and fine-grained classification tasks.