 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025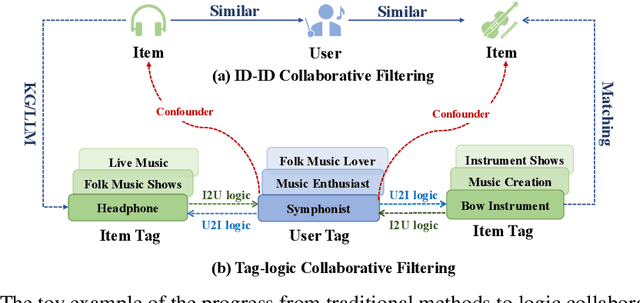
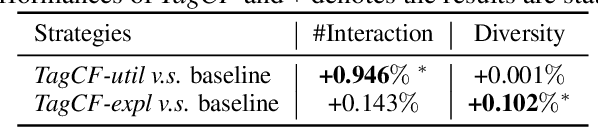
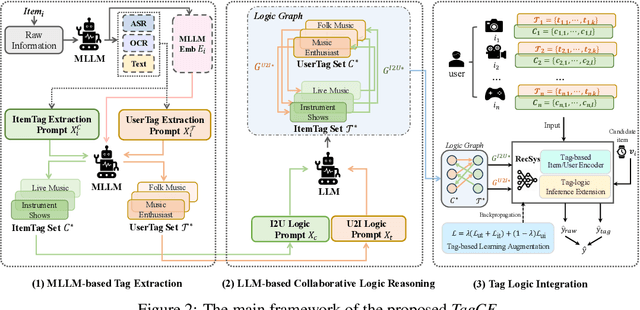
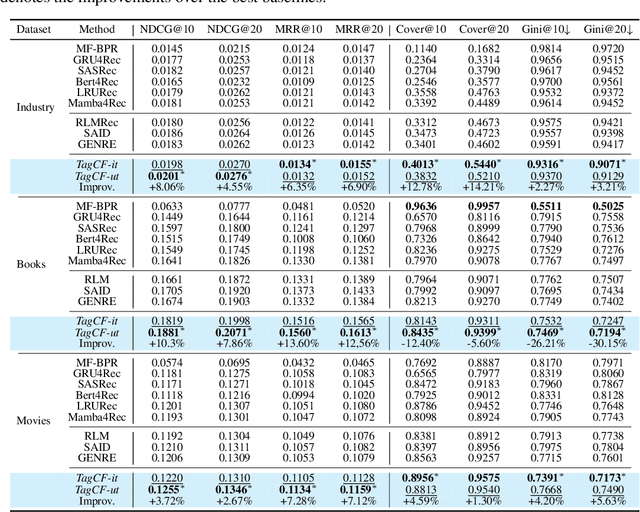
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
iMOVE: Instance-Motion-Aware Video Understanding
Feb 18, 2025



Enhancing the fine-grained instance spatiotemporal motion perception capabilities of Video Large Language Models is crucial for improving their temporal and general video understanding. However, current models struggle to perceive detailed and complex instance motions. To address these challenges, we have made improvements from both data and model perspectives. In terms of data, we have meticulously curated iMOVE-IT, the first large-scale instance-motion-aware video instruction-tuning dataset. This dataset is enriched with comprehensive instance motion annotations and spatiotemporal mutual-supervision tasks, providing extensive training for the model's instance-motion-awareness. Building on this foundation, we introduce iMOVE, an instance-motion-aware video foundation model that utilizes Event-aware Spatiotemporal Efficient Modeling to retain informative instance spatiotemporal motion details while maintaining computational efficiency. It also incorporates Relative Spatiotemporal Position Tokens to ensure awareness of instance spatiotemporal positions. Evaluations indicate that iMOVE excels not only in video temporal understanding and general video understanding but also demonstrates significant advantages in long-term video understanding.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024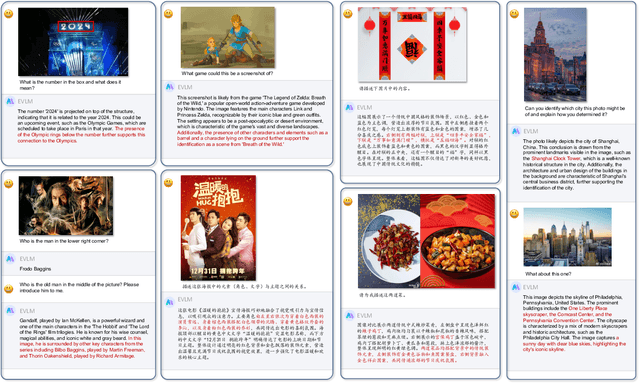
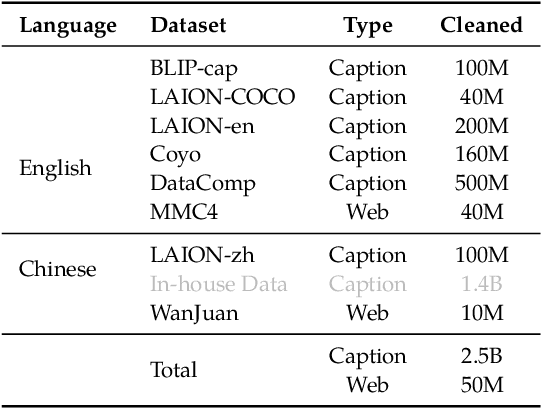
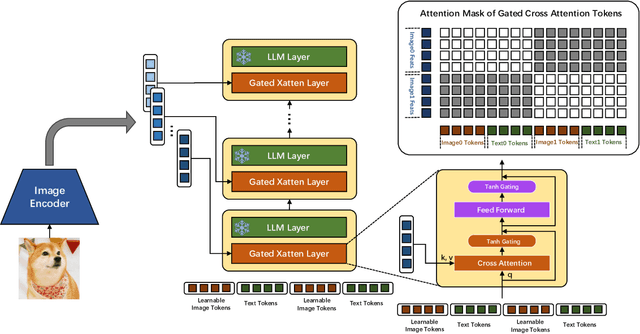

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.