 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
Feb 06, 2025Model merging aggregates Large Language Models (LLMs) finetuned on different tasks into a stronger one. However, parameter conflicts between models leads to performance degradation in averaging. While model routing addresses this issue by selecting individual models during inference, it imposes excessive storage and compute costs, and fails to leverage the common knowledge from different models. In this work, we observe that different layers exhibit varying levels of parameter conflicts. Building on this insight, we average layers with minimal parameter conflicts and use a novel task-level expert routing for layers with significant conflicts. To further reduce storage costs, inspired by task arithmetic sparsity, we decouple multiple fine-tuned experts into a dense expert and several sparse experts. Considering the out-of-distribution samples, we select and merge appropriate experts based on the task uncertainty of the input data. We conduct extensive experiments on both LLaMA and Qwen with varying parameter scales, and evaluate on real-world reasoning tasks. Results demonstrate that our method consistently achieves significant performance improvements while requiring less system cost compared to existing methods.
KGSynNet: A Novel Entity Synonyms Discovery Framework with Knowledge Graph
Apr 01, 2021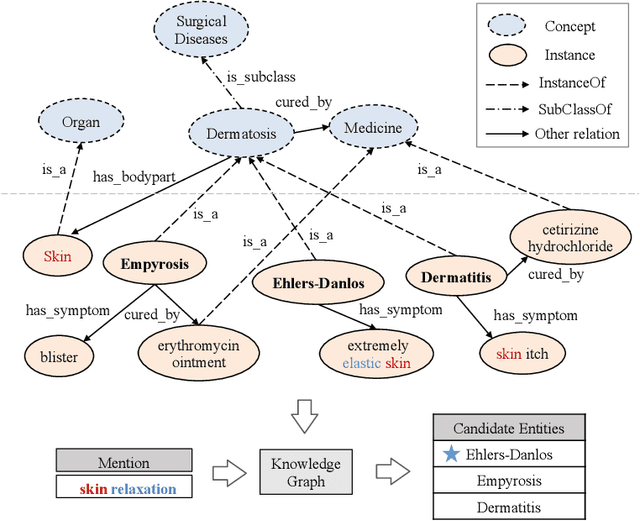
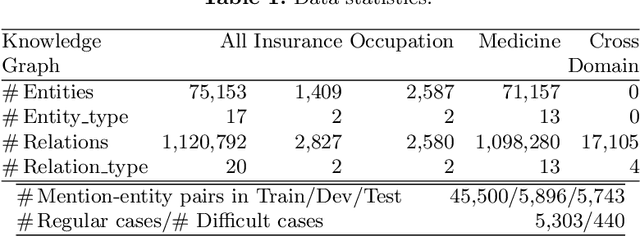
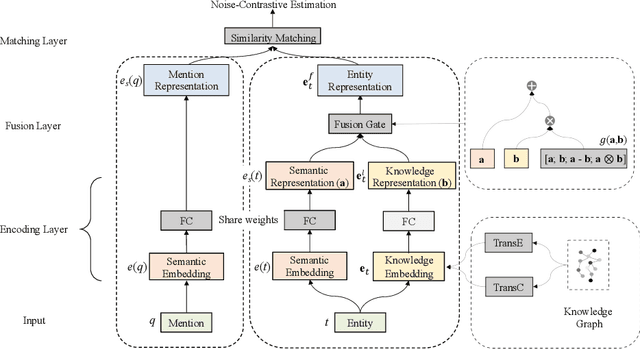
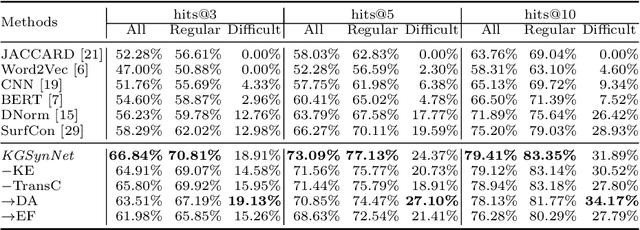
Entity synonyms discovery is crucial for entity-leveraging applications. However, existing studies suffer from several critical issues: (1) the input mentions may be out-of-vocabulary (OOV) and may come from a different semantic space of the entities; (2) the connection between mentions and entities may be hidden and cannot be established by surface matching; and (3) some entities rarely appear due to the long-tail effect. To tackle these challenges, we facilitate knowledge graphs and propose a novel entity synonyms discovery framework, named \emph{KGSynNet}. Specifically, we pre-train subword embeddings for mentions and entities using a large-scale domain-specific corpus while learning the knowledge embeddings of entities via a joint TransC-TransE model. More importantly, to obtain a comprehensive representation of entities, we employ a specifically designed \emph{fusion gate} to adaptively absorb the entities' knowledge information into their semantic features. We conduct extensive experiments to demonstrate the effectiveness of our \emph{KGSynNet} in leveraging the knowledge graph. The experimental results show that the \emph{KGSynNet} improves the state-of-the-art methods by 14.7\% in terms of hits@3 in the offline evaluation and outperforms the BERT model by 8.3\% in the positive feedback rate of an online A/B test on the entity linking module of a question answering system.
Fine-grained Event Categorization with Heterogeneous Graph Convolutional Networks
Jun 09, 2019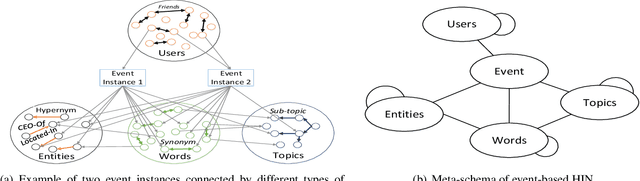
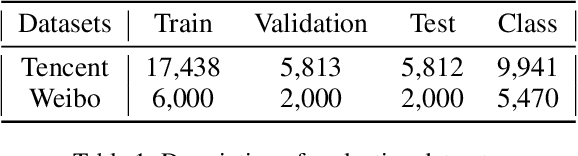
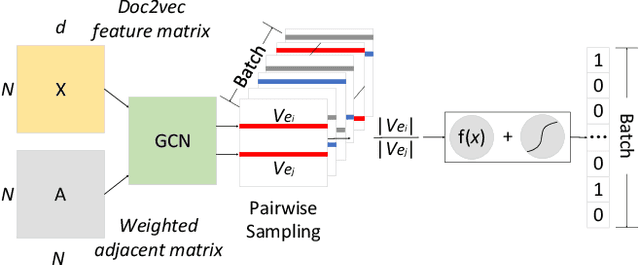
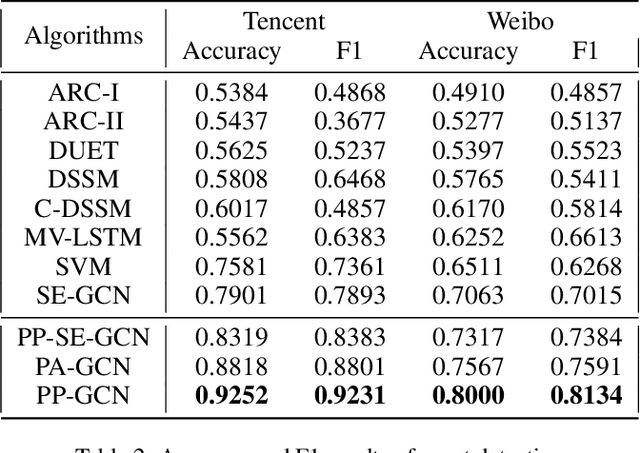
Events are happening in real-world and real-time, which can be planned and organized occasions involving multiple people and objects. Social media platforms publish a lot of text messages containing public events with comprehensive topics. However, mining social events is challenging due to the heterogeneous event elements in texts and explicit and implicit social network structures. In this paper, we design an event meta-schema to characterize the semantic relatedness of social events and build an event-based heterogeneous information network (HIN) integrating information from external knowledge base, and propose a novel Pair-wise Popularity Graph Convolutional Network (PP-GCN) based fine-grained social event categorization model. We propose a Knowledgeable meta-paths Instances based social Event Similarity (KIES) between events and build a weighted adjacent matrix as input to the PP-GCN model. Comprehensive experiments on real data collections are conducted to compare various social event detection and clustering tasks. Experimental results demonstrate that our proposed framework outperforms other alternative social event categorization techniques.
Multiresolution Graph Attention Networks for Relevance Matching
Feb 27, 2019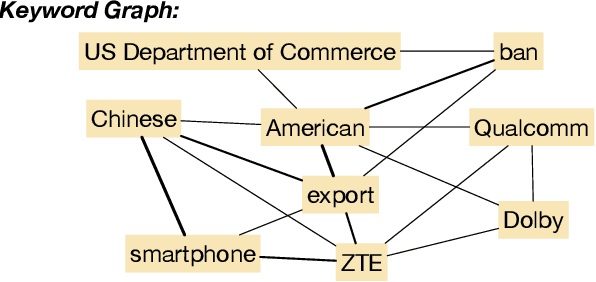
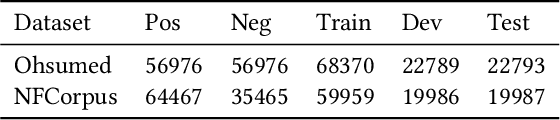
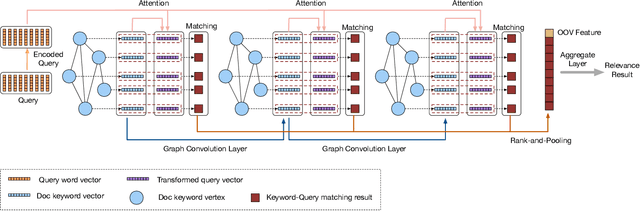
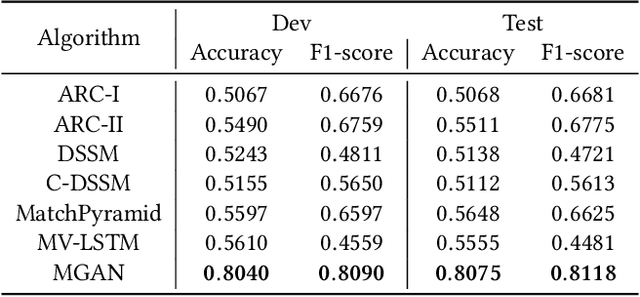
A large number of deep learning models have been proposed for the text matching problem, which is at the core of various typical natural language processing (NLP) tasks. However, existing deep models are mainly designed for the semantic matching between a pair of short texts, such as paraphrase identification and question answering, and do not perform well on the task of relevance matching between short-long text pairs. This is partially due to the fact that the essential characteristics of short-long text matching have not been well considered in these deep models. More specifically, these methods fail to handle extreme length discrepancy between text pieces and neither can they fully characterize the underlying structural information in long text documents. In this paper, we are especially interested in relevance matching between a piece of short text and a long document, which is critical to problems like query-document matching in information retrieval and web searching. To extract the structural information of documents, an undirected graph is constructed, with each vertex representing a keyword and the weight of an edge indicating the degree of interaction between keywords. Based on the keyword graph, we further propose a Multiresolution Graph Attention Network to learn multi-layered representations of vertices through a Graph Convolutional Network (GCN), and then match the short text snippet with the graphical representation of the document with the attention mechanisms applied over each layer of the GCN. Experimental results on two datasets demonstrate that our graph approach outperforms other state-of-the-art deep matching models.
Learning to Generate Questions by Learning What not to Generate
Feb 27, 2019


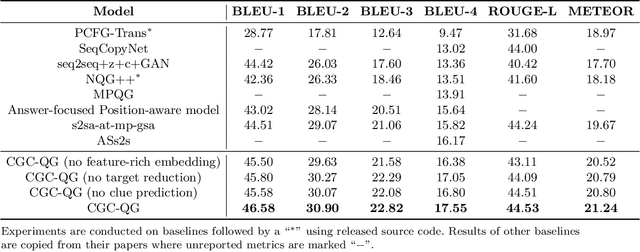
Automatic question generation is an important technique that can improve the training of question answering, help chatbots to start or continue a conversation with humans, and provide assessment materials for educational purposes. Existing neural question generation models are not sufficient mainly due to their inability to properly model the process of how each word in the question is selected, i.e., whether repeating the given passage or being generated from a vocabulary. In this paper, we propose our Clue Guided Copy Network for Question Generation (CGC-QG), which is a sequence-to-sequence generative model with copying mechanism, yet employing a variety of novel components and techniques to boost the performance of question generation. In CGC-QG, we design a multi-task labeling strategy to identify whether a question word should be copied from the input passage or be generated instead, guiding the model to learn the accurate boundaries between copying and generation. Furthermore, our input passage encoder takes as input, among a diverse range of other features, the prediction made by a clue word predictor, which helps identify whether each word in the input passage is a potential clue to be copied into the target question. The clue word predictor is designed based on a novel application of Graph Convolutional Networks onto a syntactic dependency tree representation of each passage, thus being able to predict clue words only based on their context in the passage and their relative positions to the answer in the tree. We jointly train the clue prediction as well as question generation with multi-task learning and a number of practical strategies to reduce the complexity. Extensive evaluations show that our model significantly improves the performance of question generation and out-performs all previous state-of-the-art neural question generation models by a substantial margin.
Growing Story Forest Online from Massive Breaking News
Mar 01, 2018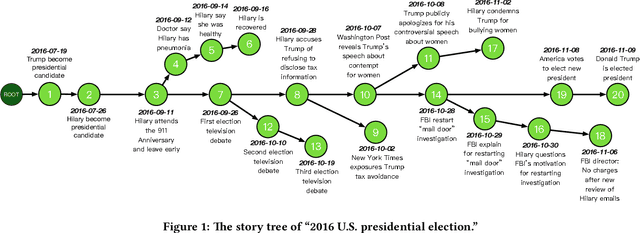
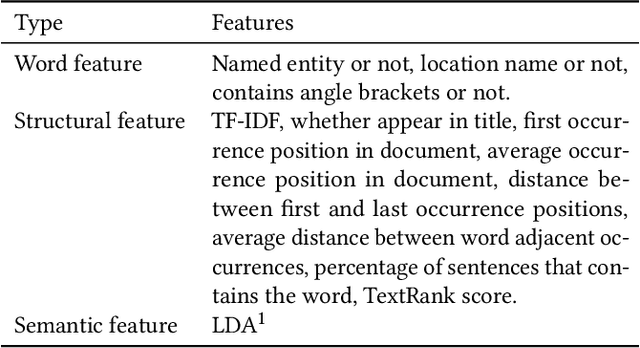
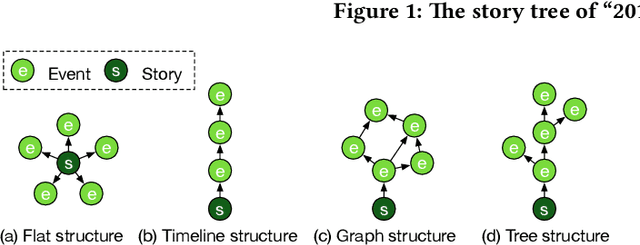
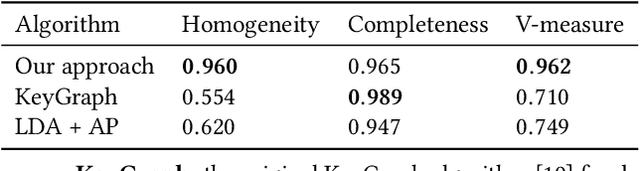
We describe our experience of implementing a news content organization system at Tencent that discovers events from vast streams of breaking news and evolves news story structures in an online fashion. Our real-world system has distinct requirements in contrast to previous studies on topic detection and tracking (TDT) and event timeline or graph generation, in that we 1) need to accurately and quickly extract distinguishable events from massive streams of long text documents that cover diverse topics and contain highly redundant information, and 2) must develop the structures of event stories in an online manner, without repeatedly restructuring previously formed stories, in order to guarantee a consistent user viewing experience. In solving these challenges, we propose Story Forest, a set of online schemes that automatically clusters streaming documents into events, while connecting related events in growing trees to tell evolving stories. We conducted extensive evaluation based on 60 GB of real-world Chinese news data, although our ideas are not language-dependent and can easily be extended to other languages, through detailed pilot user experience studies. The results demonstrate the superior capability of Story Forest to accurately identify events and organize news text into a logical structure that is appealing to human readers, compared to multiple existing algorithm frameworks.
Matching Natural Language Sentences with Hierarchical Sentence Factorization
Mar 01, 2018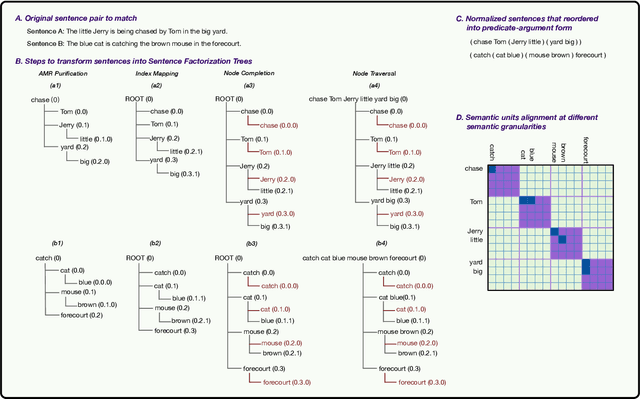

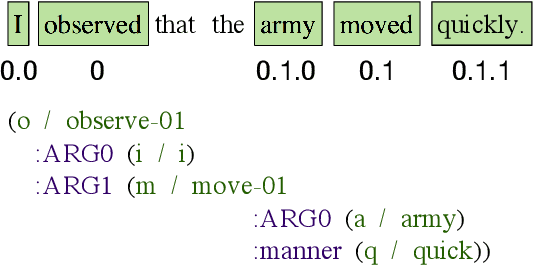
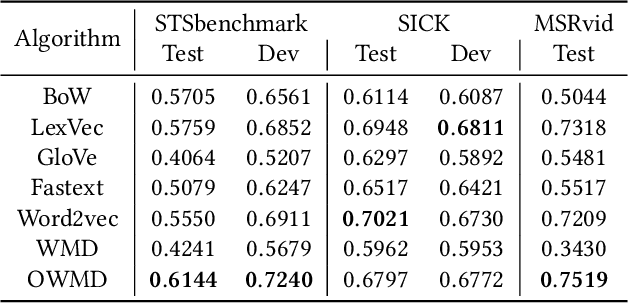
Semantic matching of natural language sentences or identifying the relationship between two sentences is a core research problem underlying many natural language tasks. Depending on whether training data is available, prior research has proposed both unsupervised distance-based schemes and supervised deep learning schemes for sentence matching. However, previous approaches either omit or fail to fully utilize the ordered, hierarchical, and flexible structures of language objects, as well as the interactions between them. In this paper, we propose Hierarchical Sentence Factorization---a technique to factorize a sentence into a hierarchical representation, with the components at each different scale reordered into a "predicate-argument" form. The proposed sentence factorization technique leads to the invention of: 1) a new unsupervised distance metric which calculates the semantic distance between a pair of text snippets by solving a penalized optimal transport problem while preserving the logical relationship of words in the reordered sentences, and 2) new multi-scale deep learning models for supervised semantic training, based on factorized sentence hierarchies. We apply our techniques to text-pair similarity estimation and text-pair relationship classification tasks, based on multiple datasets such as STSbenchmark, the Microsoft Research paraphrase identification (MSRP) dataset, the SICK dataset, etc. Extensive experiments show that the proposed hierarchical sentence factorization can be used to significantly improve the performance of existing unsupervised distance-based metrics as well as multiple supervised deep learning models based on the convolutional neural network (CNN) and long short-term memory (LSTM).
Matching Long Text Documents via Graph Convolutional Networks
Feb 21, 2018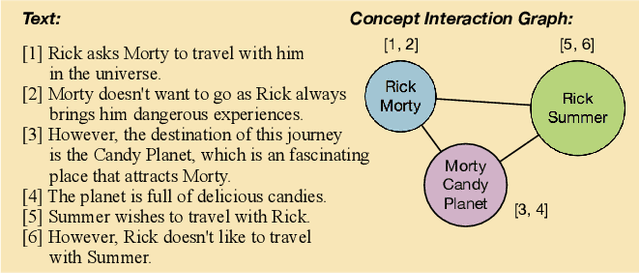
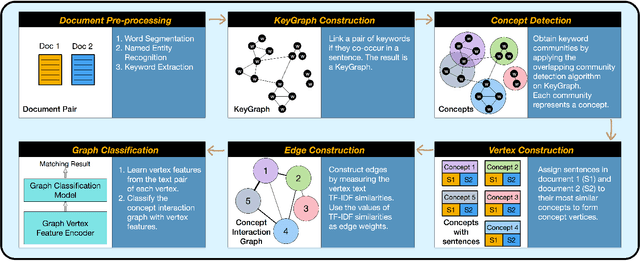

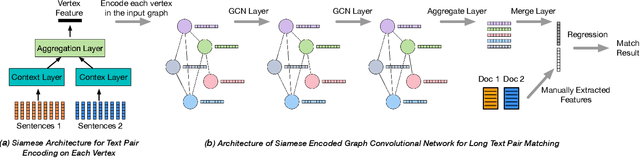
Identifying the relationship between two text objects is a core research problem underlying many natural language processing tasks. A wide range of deep learning schemes have been proposed for text matching, mainly focusing on sentence matching, question answering or query document matching. We point out that existing approaches do not perform well at matching long documents, which is critical, for example, to AI-based news article understanding and event or story formation. The reason is that these methods either omit or fail to fully utilize complicated semantic structures in long documents. In this paper, we propose a graph approach to text matching, especially targeting long document matching, such as identifying whether two news articles report the same event in the real world, possibly with different narratives. We propose the Concept Interaction Graph to yield a graph representation for a document, with vertices representing different concepts, each being one or a group of coherent keywords in the document, and with edges representing the interactions between different concepts, connected by sentences in the document. Based on the graph representation of document pairs, we further propose a Siamese Encoded Graph Convolutional Network that learns vertex representations through a Siamese neural network and aggregates the vertex features though Graph Convolutional Networks to generate the matching result. Extensive evaluation of the proposed approach based on two labeled news article datasets created at Tencent for its intelligent news products show that the proposed graph approach to long document matching significantly outperforms a wide range of state-of-the-art methods.