 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Network Embedding via Incremental Skip-gram with Negative Sampling
Jun 09, 2019
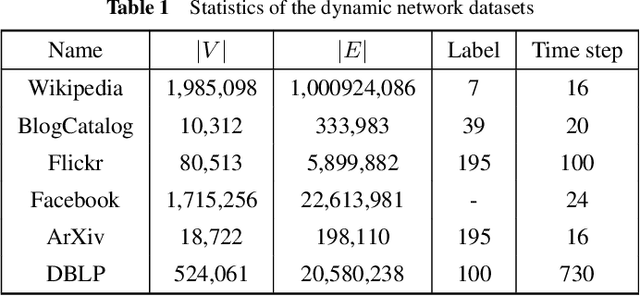

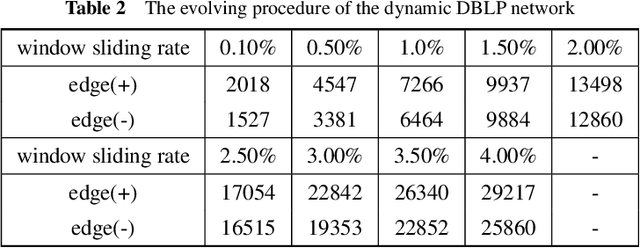
Network representation learning, as an approach to learn low dimensional representations of vertices, has attracted considerable research attention recently. It has been proven extremely useful in many machine learning tasks over large graph. Most existing methods focus on learning the structural representations of vertices in a static network, but cannot guarantee an accurate and efficient embedding in a dynamic network scenario. To address this issue, we present an efficient incremental skip-gram algorithm with negative sampling for dynamic network embedding, and provide a set of theoretical analyses to characterize the performance guarantee. Specifically, we first partition a dynamic network into the updated, including addition/deletion of links and vertices, and the retained networks over time. Then we factorize the objective function of network embedding into the added, vanished and retained parts of the network. Next we provide a new stochastic gradient-based method, guided by the partitions of the network, to update the nodes and the parameter vectors. The proposed algorithm is proven to yield an objective function value with a bounded difference to that of the original objective function. Experimental results show that our proposal can significantly reduce the training time while preserving the comparable performance. We also demonstrate the correctness of the theoretical analysis and the practical usefulness of the dynamic network embedding. We perform extensive experiments on multiple real-world large network datasets over multi-label classification and link prediction tasks to evaluate the effectiveness and efficiency of the proposed framework, and up to 22 times speedup has been achieved.
Hierarchical Taxonomy-Aware and Attentional Graph Capsule RCNNs for Large-Scale Multi-Label Text Classification
Jun 09, 2019



CNNs, RNNs, GCNs, and CapsNets have shown significant insights in representation learning and are widely used in various text mining tasks such as large-scale multi-label text classification. However, most existing deep models for multi-label text classification consider either the non-consecutive and long-distance semantics or the sequential semantics, but how to consider them both coherently is less studied. In addition, most existing methods treat output labels as independent methods, but ignore the hierarchical relations among them, leading to useful semantic information loss. In this paper, we propose a novel hierarchical taxonomy-aware and attentional graph capsule recurrent CNNs framework for large-scale multi-label text classification. Specifically, we first propose to model each document as a word order preserved graph-of-words and normalize it as a corresponding words-matrix representation which preserves both the non-consecutive, long-distance and local sequential semantics. Then the words-matrix is input to the proposed attentional graph capsule recurrent CNNs for more effectively learning the semantic features. To leverage the hierarchical relations among the class labels, we propose a hierarchical taxonomy embedding method to learn their representations, and define a novel weighted margin loss by incorporating the label representation similarity. Extensive evaluations on three datasets show that our model significantly improves the performance of large-scale multi-label text classification by comparing with state-of-the-art approaches.
Fine-grained Event Categorization with Heterogeneous Graph Convolutional Networks
Jun 09, 2019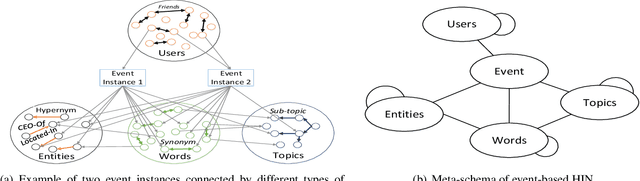
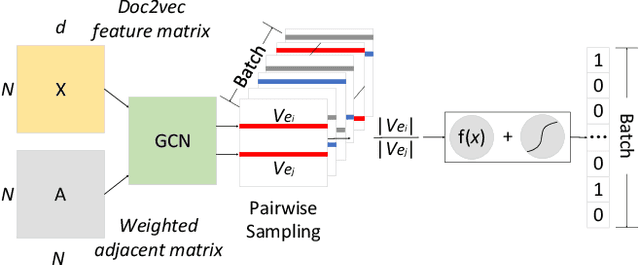
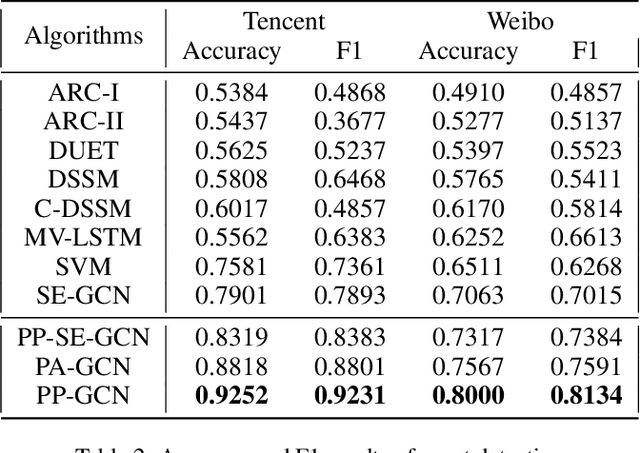
Events are happening in real-world and real-time, which can be planned and organized occasions involving multiple people and objects. Social media platforms publish a lot of text messages containing public events with comprehensive topics. However, mining social events is challenging due to the heterogeneous event elements in texts and explicit and implicit social network structures. In this paper, we design an event meta-schema to characterize the semantic relatedness of social events and build an event-based heterogeneous information network (HIN) integrating information from external knowledge base, and propose a novel Pair-wise Popularity Graph Convolutional Network (PP-GCN) based fine-grained social event categorization model. We propose a Knowledgeable meta-paths Instances based social Event Similarity (KIES) between events and build a weighted adjacent matrix as input to the PP-GCN model. Comprehensive experiments on real data collections are conducted to compare various social event detection and clustering tasks. Experimental results demonstrate that our proposed framework outperforms other alternative social event categorization techniques.
Graph Convolutional Neural Networks via Motif-based Attention
Nov 11, 2018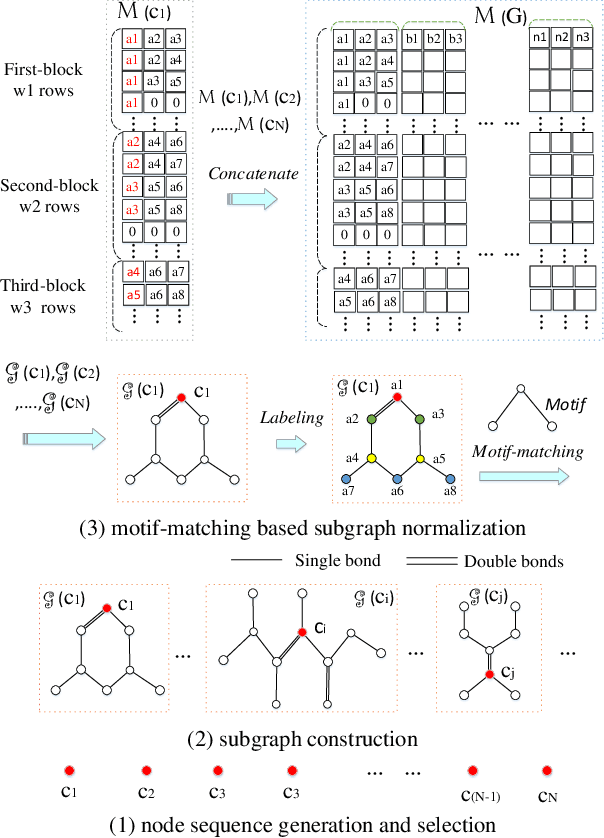
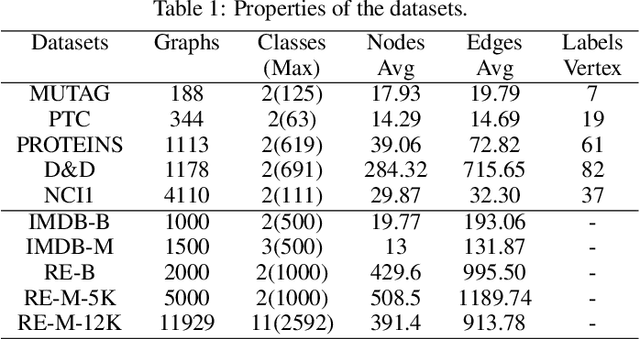
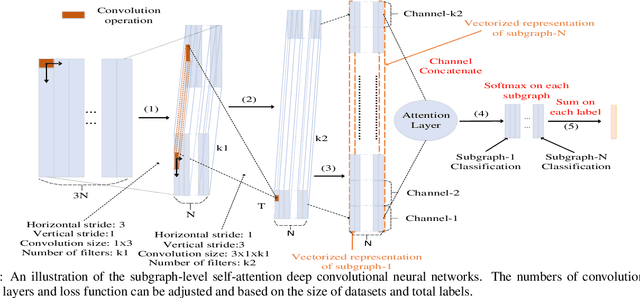
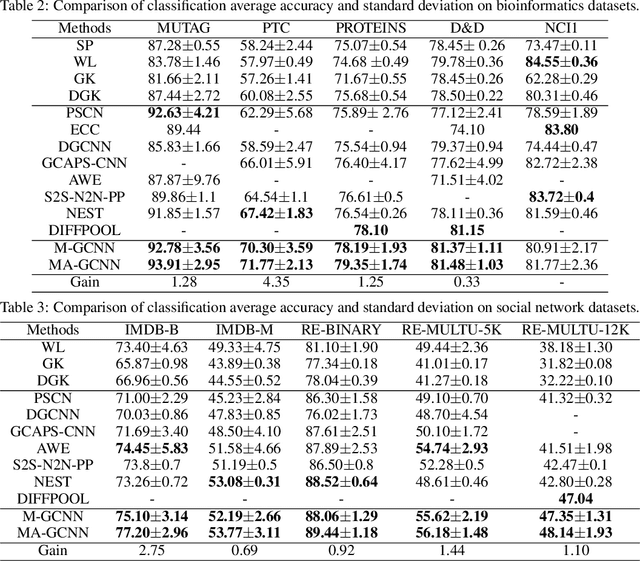
Many real-world problems can be represented as graph-based learning problems. In this paper, we propose a novel framework for learning spatial and attentional convolution neural networks on arbitrary graphs. Different from previous convolutional neural networks on graphs, we first design a motif-matching guided subgraph normalization method to capture neighborhood information. Then we implement self-attentional layers to learn different importances from different subgraphs to solve graph classification problems. Analogous to image-based attentional convolution networks that operate on locally connected and weighted regions of the input, we also extend graph normalization from one-dimensional node sequence to two-dimensional node grid by leveraging motif-matching, and design self-attentional layers without requiring any kinds of cost depending on prior knowledge of the graph structure. Our results on both bioinformatics and social network datasets show that we can significantly improve graph classification benchmarks over traditional graph kernel and existing deep models.