 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQBSUM: a Large-Scale Query-Based Document Summarization Dataset from Real-world Applications
Oct 28, 2020
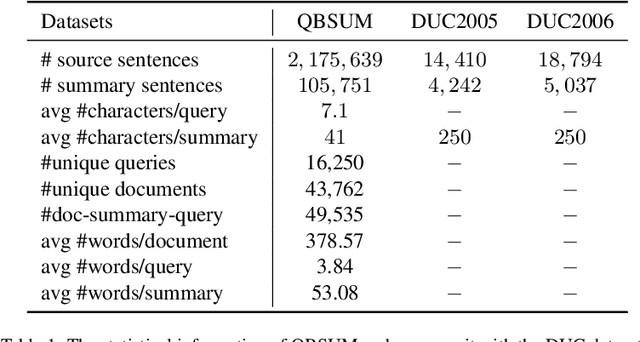

Query-based document summarization aims to extract or generate a summary of a document which directly answers or is relevant to the search query. It is an important technique that can be beneficial to a variety of applications such as search engines, document-level machine reading comprehension, and chatbots. Currently, datasets designed for query-based summarization are short in numbers and existing datasets are also limited in both scale and quality. Moreover, to the best of our knowledge, there is no publicly available dataset for Chinese query-based document summarization. In this paper, we present QBSUM, a high-quality large-scale dataset consisting of 49,000+ data samples for the task of Chinese query-based document summarization. We also propose multiple unsupervised and supervised solutions to the task and demonstrate their high-speed inference and superior performance via both offline experiments and online A/B tests. The QBSUM dataset is released in order to facilitate future advancement of this research field.
Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model
Jun 04, 2019
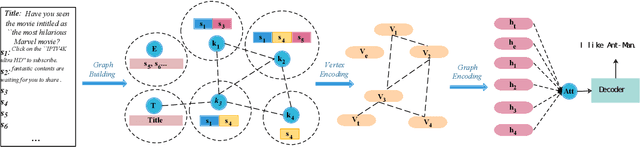
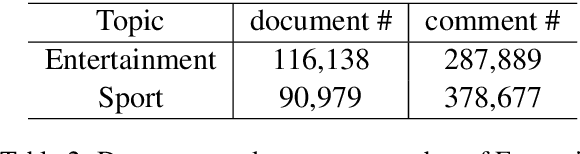
Automatic article commenting is helpful in encouraging user engagement and interaction on online news platforms. However, the news documents are usually too long for traditional encoder-decoder based models, which often results in general and irrelevant comments. In this paper, we propose to generate comments with a graph-to-sequence model that models the input news as a topic interaction graph. By organizing the article into graph structure, our model can better understand the internal structure of the article and the connection between topics, which makes it better able to understand the story. We collect and release a large scale news-comment corpus from a popular Chinese online news platform Tencent Kuaibao. Extensive experiment results show that our model can generate much more coherent and informative comments compared with several strong baseline models.