 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Video Quality Scoring and Justification via Large Multimodal Models
Jun 26, 2025Classical video quality assessment (VQA) methods generate a numerical score to judge a video's perceived visual fidelity and clarity. Yet, a score fails to describe the video's complex quality dimensions, restricting its applicability. Benefiting from the linguistic output, adapting video large multimodal models (LMMs) to VQA via instruction tuning has the potential to address this issue. The core of the approach lies in the video quality-centric instruction data. Previous explorations mainly focus on the image domain, and their data generation processes heavily rely on human quality annotations and proprietary systems, limiting data scalability and effectiveness. To address these challenges, we propose the Score-based Instruction Generation (SIG) pipeline. Specifically, SIG first scores multiple quality dimensions of an unlabeled video and maps scores to text-defined levels. It then explicitly incorporates a hierarchical Chain-of-Thought (CoT) to model the correlation between specific dimensions and overall quality, mimicking the human visual system's reasoning process. The automated pipeline eliminates the reliance on expert-written quality descriptions and proprietary systems, ensuring data scalability and generation efficiency. To this end, the resulting Score2Instruct (S2I) dataset contains over 320K diverse instruction-response pairs, laying the basis for instruction tuning. Moreover, to advance video LMMs' quality scoring and justification abilities simultaneously, we devise a progressive tuning strategy to fully unleash the power of S2I. Built upon SIG, we further curate a benchmark termed S2I-Bench with 400 open-ended questions to better evaluate the quality justification capacity of video LMMs. Experimental results on the S2I-Bench and existing benchmarks indicate that our method consistently improves quality scoring and justification capabilities across multiple video LMMs.
KVQ: Boosting Video Quality Assessment via Saliency-guided Local Perception
Mar 13, 2025Video Quality Assessment (VQA), which intends to predict the perceptual quality of videos, has attracted increasing attention. Due to factors like motion blur or specific distortions, the quality of different regions in a video varies. Recognizing the region-wise local quality within a video is beneficial for assessing global quality and can guide us in adopting fine-grained enhancement or transcoding strategies. Due to the heavy cost of annotating region-wise quality, the lack of ground truth constraints from relevant datasets further complicates the utilization of local perception. Inspired by the Human Visual System (HVS) that links global quality to the local texture of different regions and their visual saliency, we propose a Kaleidoscope Video Quality Assessment (KVQ) framework, which aims to effectively assess both saliency and local texture, thereby facilitating the assessment of global quality. Our framework extracts visual saliency and allocates attention using Fusion-Window Attention (FWA) while incorporating a Local Perception Constraint (LPC) to mitigate the reliance of regional texture perception on neighboring areas. KVQ obtains significant improvements across multiple scenarios on five VQA benchmarks compared to SOTA methods. Furthermore, to assess local perception, we establish a new Local Perception Visual Quality (LPVQ) dataset with region-wise annotations. Experimental results demonstrate the capability of KVQ in perceiving local distortions. KVQ models and the LPVQ dataset will be available at https://github.com/qyp2000/KVQ.
Visual Autoregressive Modeling for Image Super-Resolution
Jan 31, 2025



Image Super-Resolution (ISR) has seen significant progress with the introduction of remarkable generative models. However, challenges such as the trade-off issues between fidelity and realism, as well as computational complexity, have also posed limitations on their application. Building upon the tremendous success of autoregressive models in the language domain, we propose \textbf{VARSR}, a novel visual autoregressive modeling for ISR framework with the form of next-scale prediction. To effectively integrate and preserve semantic information in low-resolution images, we propose using prefix tokens to incorporate the condition. Scale-aligned Rotary Positional Encodings are introduced to capture spatial structures and the diffusion refiner is utilized for modeling quantization residual loss to achieve pixel-level fidelity. Image-based Classifier-free Guidance is proposed to guide the generation of more realistic images. Furthermore, we collect large-scale data and design a training process to obtain robust generative priors. Quantitative and qualitative results show that VARSR is capable of generating high-fidelity and high-realism images with more efficiency than diffusion-based methods. Our codes will be released at https://github.com/qyp2000/VARSR.
QPT V2: Masked Image Modeling Advances Visual Scoring
Jul 23, 2024



Quality assessment and aesthetics assessment aim to evaluate the perceived quality and aesthetics of visual content. Current learning-based methods suffer greatly from the scarcity of labeled data and usually perform sub-optimally in terms of generalization. Although masked image modeling (MIM) has achieved noteworthy advancements across various high-level tasks (e.g., classification, detection etc.). In this work, we take on a novel perspective to investigate its capabilities in terms of quality- and aesthetics-awareness. To this end, we propose Quality- and aesthetics-aware pretraining (QPT V2), the first pretraining framework based on MIM that offers a unified solution to quality and aesthetics assessment. To perceive the high-level semantics and fine-grained details, pretraining data is curated. To comprehensively encompass quality- and aesthetics-related factors, degradation is introduced. To capture multi-scale quality and aesthetic information, model structure is modified. Extensive experimental results on 11 downstream benchmarks clearly show the superior performance of QPT V2 in comparison with current state-of-the-art approaches and other pretraining paradigms. Code and models will be released at \url{https://github.com/KeiChiTse/QPT-V2}.
XPSR: Cross-modal Priors for Diffusion-based Image Super-Resolution
Mar 08, 2024
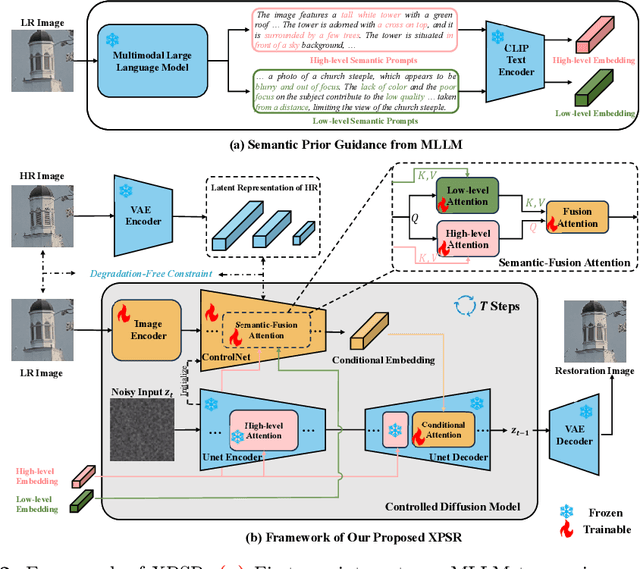
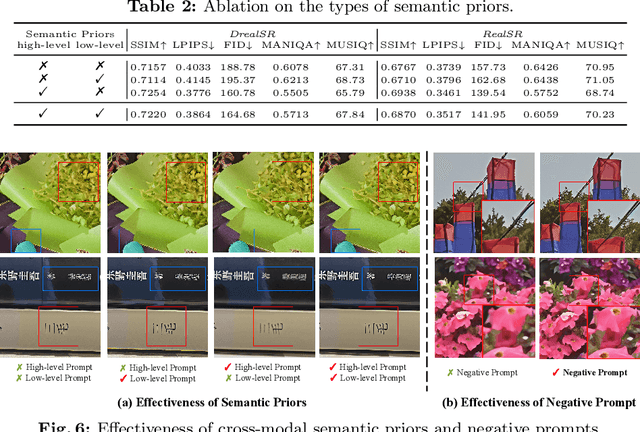
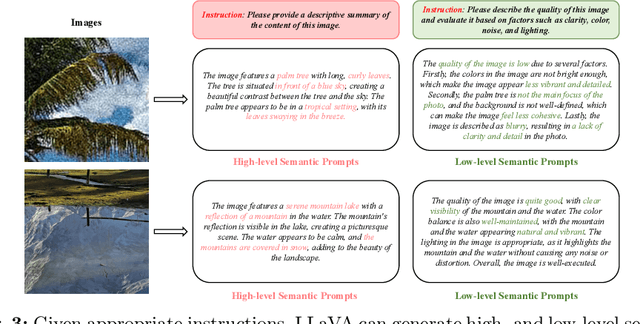
Diffusion-based methods, endowed with a formidable generative prior, have received increasing attention in Image Super-Resolution (ISR) recently. However, as low-resolution (LR) images often undergo severe degradation, it is challenging for ISR models to perceive the semantic and degradation information, resulting in restoration images with incorrect content or unrealistic artifacts. To address these issues, we propose a \textit{Cross-modal Priors for Super-Resolution (XPSR)} framework. Within XPSR, to acquire precise and comprehensive semantic conditions for the diffusion model, cutting-edge Multimodal Large Language Models (MLLMs) are utilized. To facilitate better fusion of cross-modal priors, a \textit{Semantic-Fusion Attention} is raised. To distill semantic-preserved information instead of undesired degradations, a \textit{Degradation-Free Constraint} is attached between LR and its high-resolution (HR) counterpart. Quantitative and qualitative results show that XPSR is capable of generating high-fidelity and high-realism images across synthetic and real-world datasets. Codes will be released at \url{https://github.com/qyp2000/XPSR}.
KVQ: Kwai Video Quality Assessment for Short-form Videos
Feb 20, 2024



Short-form UGC video platforms, like Kwai and TikTok, have been an emerging and irreplaceable mainstream media form, thriving on user-friendly engagement, and kaleidoscope creation, etc. However, the advancing content-generation modes, e.g., special effects, and sophisticated processing workflows, e.g., de-artifacts, have introduced significant challenges to recent UGC video quality assessment: (i) the ambiguous contents hinder the identification of quality-determined regions. (ii) the diverse and complicated hybrid distortions are hard to distinguish. To tackle the above challenges and assist in the development of short-form videos, we establish the first large-scale Kaleidoscope short Video database for Quality assessment, termed KVQ, which comprises 600 user-uploaded short videos and 3600 processed videos through the diverse practical processing workflows, including pre-processing, transcoding, and enhancement. Among them, the absolute quality score of each video and partial ranking score among indistinguishable samples are provided by a team of professional researchers specializing in image processing. Based on this database, we propose the first short-form video quality evaluator, i.e., KSVQE, which enables the quality evaluator to identify the quality-determined semantics with the content understanding of large vision language models (i.e., CLIP) and distinguish the distortions with the distortion understanding module. Experimental results have shown the effectiveness of KSVQE on our KVQ database and popular VQA databases.
3D Adversarial Attacks Beyond Point Cloud
Apr 25, 2021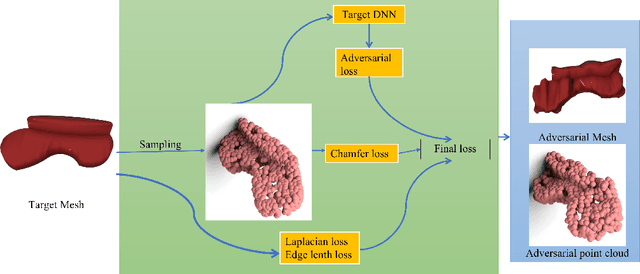
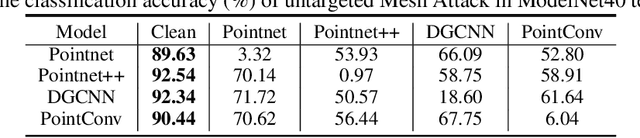
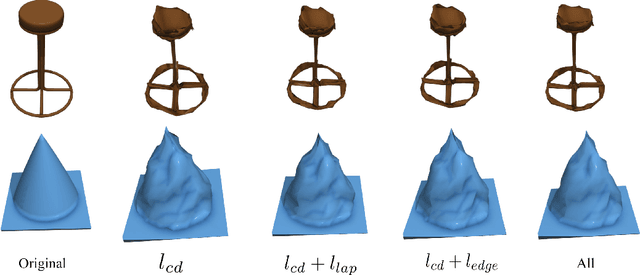
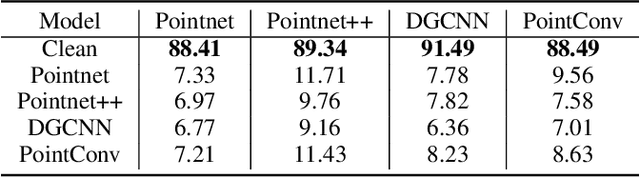
Previous adversarial attacks on 3D point clouds mainly focus on add perturbation to the original point cloud, but the generated adversarial point cloud example does not strictly represent a 3D object in the physical world and has lower transferability or easily defend by the simple SRS/SOR. In this paper, we present a novel adversarial attack, named Mesh Attack to address this problem. Specifically, we perform perturbation on the mesh instead of point clouds and obtain the adversarial mesh examples and point cloud examples simultaneously. To generate adversarial examples, we use a differential sample module that back-propagates the loss of point cloud classifier to the mesh vertices and a mesh loss that regularizes the mesh to be smooth. Extensive experiments demonstrated that the proposed scheme outperforms the SOTA attack methods. Our code is available at: {\footnotesize{\url{https://github.com/cuge1995/Mesh-Attack}}}.