 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Image Super-Resolution State-of-the-arts and Learning Multi-model Ensemble for Video Super-Resolution
Paper and Code
May 07, 2019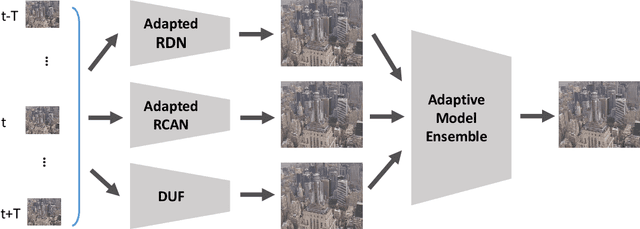
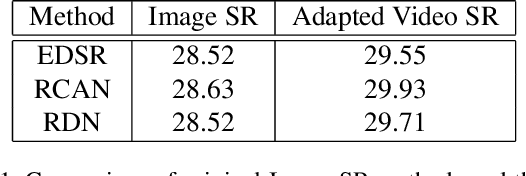
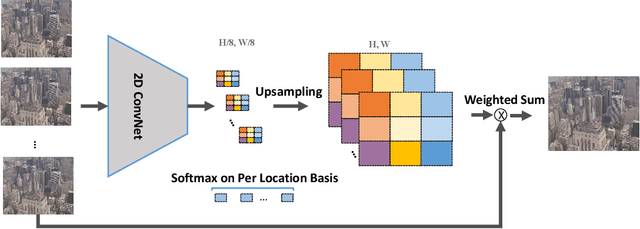

Recently, image super-resolution has been widely studied and achieved significant progress by leveraging the power of deep convolutional neural networks. However, there has been limited advancement in video super-resolution (VSR) due to the complex temporal patterns in videos. In this paper, we investigate how to adapt state-of-the-art methods of image super-resolution for video super-resolution. The proposed adapting method is straightforward. The information among successive frames is well exploited, while the overhead on the original image super-resolution method is negligible. Furthermore, we propose a learning-based method to ensemble the outputs from multiple super-resolution models. Our methods show superior performance and rank second in the NTIRE2019 Video Super-Resolution Challenge Track 1.